面向移動警務應用的云計算平臺設計與實現
2013-10-20 08:35:56計春雷
微型電腦應用 2013年1期
肖 薇,計春雷
0 引言
隨著科技的不斷發展與金盾工程的全面啟動,公安部門也越來越重視科技強警工作。常住人口、重點人口、逃犯庫、指紋系統、被盜搶車輛、駕駛員信息等一系列公安基礎數據庫在不斷完善[1],使得大規模數據不斷產生。公安民警在執行警務活動的時候,通過電臺、手機等通訊工具與留守在單位的同事來查詢、驗證數據的方式,已經不能適應目前的公安工作[2]。本文提出了Android平臺的功能模塊開發與云計算平臺有機整合的思想,通過高效的網絡接入Libev遠程調用Spark云計算服務平臺,以解決海量數據的圖像檢索問題;通過構建圖像特征索引技術,提高了圖像檢索的效率,從而提升了移動警務的執行能力。
1 研究意義
我國目前的移動警務系統主要存在以下幾個方面的問題:
(1)系統性能低。以前的移動警務系統是圍繞實現小數據集來構造的,而對于日趨龐大的公安部數據源,如何能在多個結點之間快速的運行就成為一個難點。
(2)系統結構穩定性低。系統的性能差直接導致系統結構穩定性差,隨著移動警務數量和服務質量要求的不斷提升,勢必導致系統內部結構穩定性下降。
(3)系統復用性低。目前的移動警務系統過分依賴于操作系統或網絡系統等環境提供的服務,系統中的一些模塊往往不能在其他應用環境中重復使用,并且與其他系統進行交互時存在很大的困難。
本系統的實現能夠為一線移動警務工作現場提供了強大的數據信息支持,促進業務綜合、信息關聯,滿足公安快速反應、及時行動的工作要求,提升公安交警執法的能力和水平。
2 系統設計
本系統研究的移動警務云計算平臺,主要由移動終端、移動通信網絡、服務接入網關、分布式文件系統、數據庫系統和文本檢索服務器等組成,通過這些模塊實現了系統數據信息注入、服務請求處理、海量數據存儲和處理三大內容,是服務系統的核心,如圖1所示:
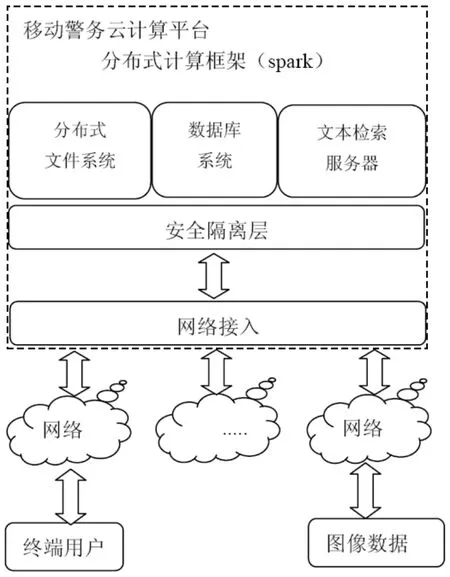
圖1 系統整體架構
基于云計算平臺的移動警務應用,在技術上主要面臨的問題包括:高效的網絡通信處理與系統交互實現;高性能的集群運行;海量數據的存儲。為了解決這些問題規劃了研究路線:
(1)對于移動終端數據的導入及系統交互,依靠于成熟可靠的 Libev、Thrift技術,實現高性能且穩定可靠的運行環境。
(2)高性能集群框架Mesos。Mesos支持分布式數據集上的迭代作業,為分布式應用程序的資源共享和隔離提供了有效的平臺[3]。
(3)分布式計算框架Spark。Spark運行在Mesos集群框架上,通過啟用內存分布式數據集,能夠提供交互式查詢和優化迭代工作負載。
(4)在海量圖像數據的一體化存儲管理研究方面,針對非結構的圖像數據、半結構的標注數據,可統一管理分別存儲。其中元數據信息可存儲在關系數據庫中;半結構的標注數據根據數據性質,可以以文件的形式存儲在分布式文件系統GlusterFS中或NoSQL數據庫中;圖像數據可以存儲在GlusterFS中,GlusterFS通過擴展能夠支持數PB存儲容量和處理數千客戶端。
3 云計算平臺模塊介紹
(1)分布式計算框架spark
Spark是一種可擴展的數據分析平臺,它為集群計算中特定類型的工作負載而設計,即那些在并行操作之間重用工作數據集(比如機器學習算法)的工作負載。為了優化這些類型的工作負載,Spark整合了內存集群計算的基元,可以在內存集群計算中將數據集緩存在內存中,以縮短訪問延遲,如圖2所示:
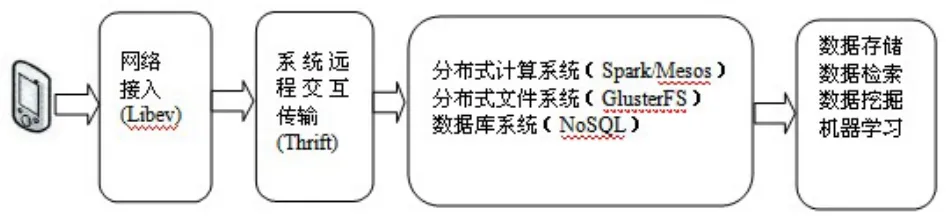
圖2 移動警務云服務平臺的研究路線
因此,相對于 Hadoop 的集群存儲方法,它在性能方面更具優勢[4]。Spark還引入了彈性分布式數據集(RDD)。RDD允許在大型集群上執行基于內存的計算,與此同時還保持了MapReduce等數據流模型的容錯特性。RDD 是分布在一組節點中的只讀對象集合。這些集合是彈性的,如果數據集有一部分丟失,則可以對它們進行重建。重建部分數據集的過程依賴于容錯機制,該機制可以維護基于數據衍生過程重建部分數據集的信息。為了實現有效地容錯,RDD提供了一種高度受限的共享內存,即RDD是只讀的,并且只能通過其他RDD上的批量操作來創建。RDD在迭代計算方面比Hadoop快20多倍,同時還可以在5-7秒的延時內交互式地查詢1TB的數據集[5]。
(2)高性能集群框架Mesos
Mesos是Spark在文件系統中并行運行的一種分布式集群框架。它支持Spark在分布式數據集上進行迭代運行,如圖3所示:
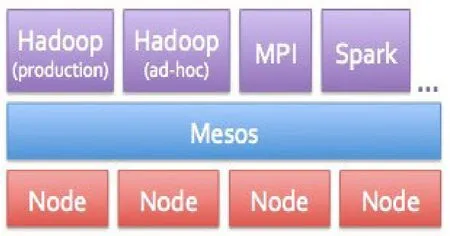
圖3 Mesos集群管理器實現資源共享和隔離
它不僅可以在動態分享的結點集上運行 Hadoop, MPI,Spark和其他結構,還能在相同集群上運行多個實體或者多版本的Hadoop來隔離任務。此外,在一批應用和共享資源中,它還可以在相同結點上執行長時間的服務(如Hypertable,HBase),在創建一個新的集群計算結構時,不用重塑低級任務就能與現有的兼容。
(3)并行編程模型MapReduce
Spark主要采用MapReduce模型。MapReduce是Google提出的一個軟件架構,用于大規模數據集(大于1TB)的并行運算。MapReduce的設計理念是通過把一個大的任務分成多個小的任務分發到多個機器上進行一個并行的數據處理,通過這種方式可以處理TB級的數據,而且保證數據不會出錯,具有可靠的容錯性。
MapReduce是一個 master/slave的架構,由一個JobTracker和多個TaskTracker組成。JobTracker主要負責任務分發,把一個任務分解成多個小的任務分發到多個TaskTracker上。當某個TaskTracker發生故障導致任務無法繼續執行時, JobTracker 需要進行任務的調度和監控,重新分配任務的執行。TaskTracker只進行任務的處理。一般情況下,TaskTracker和DataNode是同一個節點,這樣實現執行任務的數據本地化,提高任務的執行效率。
MapReduce的任務執行[6]分為Map和Reduce兩個步驟,如圖4所示:
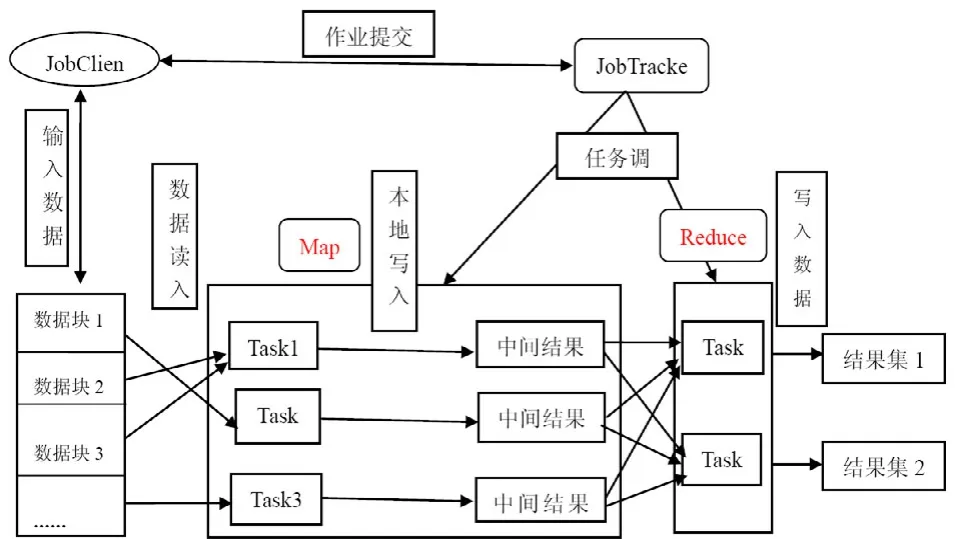
圖4 Map/Reduce整體運行框架
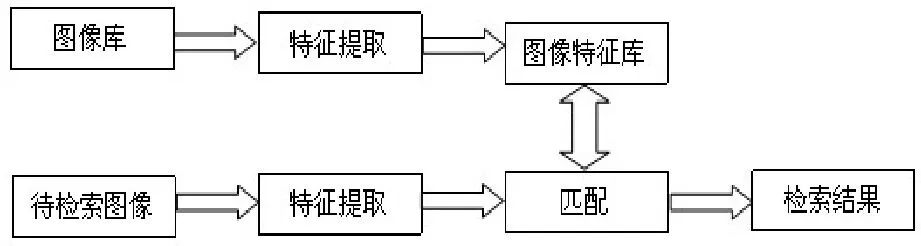
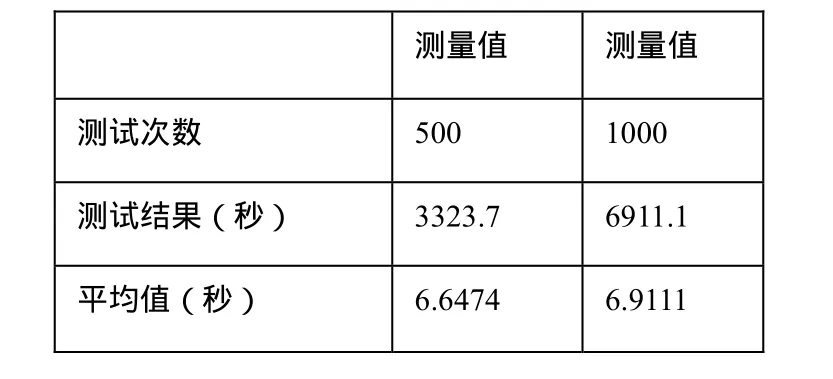
Map把mapper()函數的輸入進行一些處理,然后將結果輸出到一些數據集中。Reduce接收Map輸出的數據集作為輸入,通過相關的聚合運算,把聚合后的結果輸出。在MapReduce任務中,數據的輸入和生成是以多組 (4)分布式文件系統GlusterFS GlusterFS是一個開源的分布式文件系統,具有強大的橫向擴展能力,能夠支持數PB存儲容量和處理數千客戶端[7]。GlusterFS 架構中沒有元數據服務器組件,這是其最大的創新點,對于提升整個系統的性能、可靠性和穩定性都有著決定性的意義。它可以把多個不同類型的存儲塊通過Infiniband RDMA或TCP/IP匯聚成一個大的并行網絡文件系統,聚集在一個單一的全局命名空間中,來管理磁盤和內存資源及數據。GlusterFS是基于一個可堆疊的用戶空間設計,可以為不同的工作負載提供優異的性能,它的模塊化架構允許管理員堆疊模塊,以滿足用戶需求。 本設計是基于MPEG-7標準的車輛圖像檢索。車輛圖像中包含大量有意義的局部特征信息,如顏色,紋理,形狀等。這些特征信息以一定的形式分布在車輛圖片中,從一張圖片中抽取相關的信息并以盡可能有效的方式表示出來,然后將這種方式表示的圖片與存儲在車輛圖片模型庫中的相比較,從而獲得匹配的車輛圖片信息。 為了提高圖像檢索的速率,我們提出了創建索引方法,并采用了K-Means聚類算法的思想。K-Means聚類算法根據對象與各聚類質心之間的距離,將所有特征對象劃分為k個簇,每個簇至少擁有一個對象,每個對象只屬于一個簇。每個簇中對象之間的相似度最高,不同簇之間的相似度最低。 通過抽取和選擇能代表這個模式的特征,然后用這些特征構成的特征向量占有特征空間的一個點。通過相似性度量方法,求出提取的特征向量之間的相似度,進而確定待分類識別的車輛屬于某一已知類別。在此,我們選擇ColorLayout,ColorStructure作為索引的特征對象。通過相似度度量方法,我們可以將多維空間的聚類轉換成二維空間聚類,從而能夠方便快速的建立索引。 將ColorLayout,ColorStructure設置成二維空間坐標中的X和Y,通過將他們與設定的坐標原點(即選定的初始值)比較,可以得出相應的X和Y的值,以對象到簇的中心點的距離作為相似度的衡量標準,相似度計算采用歐基米德距離計算公式為: 在聚類過程中,作為每類數據中心的一簇圖像的特征信息被保存在高速NoSQL數據庫中,每一個聚類結果集都作為一個單獨的文件存儲在分布式文件系統中。當有新的圖片檢索請求時,通過計算待匹配圖像的 ColorLayout,ColorStructure的值,然后與存儲在高速NoSQL數據庫中的每一個聚類中心進行比對,根據結果可以得知待檢索圖像與哪個聚類最為相似。選定聚類后就可以再次通過分布式計算框架實現對這個聚類中的圖像的特征值的比對,從而得到圖片檢索的匹配結果。 創建 K-Means聚類索引,先通過檢索存儲在高速NoSQL數據庫中的特征信息,找到一個聚類中心,縮小圖像檢索范圍,然后對聚類范圍中的圖像信息進行特征值對比,這樣縮短了圖像檢索的次數,提高了檢索的效率。 移動警務人員在治安巡邏、現場執法等場景下采集車輛圖片信息,然后將照片及其標注描述信息通過3G網絡上傳到服務接入網關;服務接入網關將請求的圖像信息發送給云計算平臺中的后端服務進程,服務進程啟動分布式計算框架運行處理作業,運行結束后將計算結果反饋給警務終端人員。 (1) 客戶端發送服務請求:客戶端程序開啟之后,根據服務器端的IP和端口號,發送業務請求。主要實現代碼如下: (2) 服務器端接收服務請求:服務器端程序開啟之后,通過調用 Me sos Handler Iterator() 方法接收客戶端的服務請求。主要實現代碼如下: (3) 服務器端接收到圖像請求后,根據提取的特征值,調用Distributed Cbir.iterator Compare()方法與已經存儲在數據庫中的圖片特征信息進行匹配,圖像檢索的流程,如圖5所示: 圖5 圖像檢索的流程圖 如下是調用iterator Compare()方法代碼, (4) 服務器端將Spark云計算平臺中查找到的匹配信息返回給客戶端,客戶端接收到從云服務端返回的匹配圖片信息,如圖6所示: 圖6 客戶端接收到圖片返回信息 主要實現代碼如下: 測試結果表明,當客戶端和服務器端成功開啟之后,通信傳輸可以正常運行。客戶端模擬終端設備開始發送一個圖片請求,Libev接收到數據與服務請求后,通過Thrift遠程調用Spark云服務端數據,云服務端通過圖像特征的計算與匹配,檢索到數據庫中相應的匹配信息,將正確的結果返回給客戶端。客戶端正常顯示所有檢索的結果,從而實現了整個通信傳輸與云計算平臺的結合。 通過在模擬客戶端不斷的發送數據請求,測試從發送信息到客戶端收到返回信息的時間。系統的性能測試結果,如表1所示: 表1 系統性能測試時間 通過上表可知,系統進行壓力測試,性能仍然保持基本穩定。客戶端每次從發送信息到收到反饋信息的平均時間大約為6.9秒,對于公安內部這樣的海量信息對的圖像檢索,其性能優勢表現更加明顯。 本文在云計算平臺的基礎上,實現了面向移動警務應用的圖像檢索業務。使用高效的網絡接入Libev遠程調用Spark云計算服務平臺的解決方案,解決海量數據的圖像檢索問題;通過構建圖像特征索引技術,提高了圖像檢索的效率。本系統尤其對于處理公安部內部等海量數據時,系統性能體現良好,具有很強的實用性。 [1]朱時清.公安移動警務應用研究, [J]電子科技大學,2012,6. [2]毛冬霞.移動警務系統的應用研究, [J]華東師范大學,2009,4. [3]Apache Mesos.http://incubator.apache.org/mesos/. [4]Tim.Jones.Spark,一種快速數據分析替代方案.[M]2012,01,04. [5]彈性分布式數據集:基于內存的集群計算的容錯性抽象.http://bbs.sciencenet.cn/cn/hom.php?mod=space&uid=425672&do=blog&id= 520947. [6]王賢偉.基于 hadoop的外觀專利圖像檢索系統的研究與實現.[J]廣東工業大學學報.2011年第11期. [7]劉愛貴.GlusterFS集群文件系統研究.http://blog.csdn.net/liuben/article/details/628455.4 圖像索引的構建
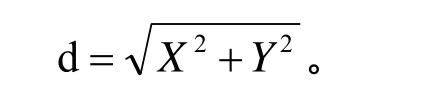
5 圖像檢索的業務實現與測試
5.1 系統實現



5.2 系統測試
6 結束語
猜你喜歡
工業設計(2022年8期)2022-09-09 07:43:20
軍民兩用技術與產品(2021年10期)2021-03-16 06:05:30
北京測繪(2020年12期)2020-12-29 01:33:58
裝備制造技術(2019年12期)2019-12-25 03:06:46
中國洗滌用品工業(2019年4期)2019-05-11 09:27:34
家庭影院技術(2017年9期)2017-09-26 03:41:45
中華手工(2017年2期)2017-06-06 23:00:31
中外會展(2014年4期)2014-11-27 07:46:46
建筑創作(2001年3期)2001-08-22 18:48:14
祝您健康(1987年3期)1987-12-30 09:52:32
