Fermi架構(gòu)下各向異性擴(kuò)散超聲斑點(diǎn)噪聲抑制
2013-09-12 01:49:52何興無
微處理機(jī) 2013年1期
關(guān)鍵詞:擴(kuò)散系數(shù)
何興無
(1.成都師范學(xué)院網(wǎng)絡(luò)與信息管理中心,成都 611130;2.成都農(nóng)業(yè)科技職業(yè)學(xué)院電子信息分院,成都 611130)
1 概述
在醫(yī)學(xué)影像技術(shù)中,醫(yī)學(xué)超聲診斷技術(shù)因?yàn)槠湟子眯裕瑹o侵入性,實(shí)時(shí)性,廉價(jià)性等特點(diǎn)和優(yōu)勢(shì)在現(xiàn)代的醫(yī)學(xué)診斷中,有著難以取代的作用[1]。然而在超聲回波信號(hào)成像處理過程中,由于需要對(duì)位于成像介質(zhì)內(nèi)的超聲隨機(jī)散射點(diǎn)產(chǎn)生的信號(hào)進(jìn)行疊加產(chǎn)生圖像信號(hào),導(dǎo)致在超聲圖像上往往會(huì)出現(xiàn)被稱為斑點(diǎn)噪聲的不規(guī)則斑點(diǎn),通常會(huì)讓人體組織難以識(shí)別,降低圖像的分辨率,從而影響圖像質(zhì)量。因此通過去除斑點(diǎn)噪聲來提高超聲圖像的質(zhì)量具有非常重要意義。
在斑點(diǎn)噪聲抑制算法中,傳統(tǒng)的顯式非線性擴(kuò)散濾波方式可以達(dá)到比較好的期望效果,但僅限于有限的很小的時(shí)間步長范圍內(nèi),對(duì)于全部時(shí)長則不穩(wěn)定。半隱式加性算子分裂的方式來離散化擴(kuò)散方程[2],使迭代過程對(duì)于任意步長都是穩(wěn)定的,并且在邊緣保持和噪聲抑制方面都有非常好的處理效果,但在傳統(tǒng)基于CPU處理時(shí)很難滿足實(shí)時(shí)系統(tǒng)的要求,這阻礙了其在實(shí)際臨床中的應(yīng)用。隨著多核時(shí)代的降臨,并行處理技術(shù)日益成為解決計(jì)算瓶頸的最重要手段,一些復(fù)雜計(jì)算也可以通過并行處理平臺(tái)進(jìn)行顯著加速。
隨著GPU技術(shù)的發(fā)展,其浮點(diǎn)數(shù)處理能力大大超過了CPU,特別是Fermi架構(gòu)GPU的出現(xiàn),使這一新的處理平臺(tái)的計(jì)算能力顯著提高。相比較于早期的通用計(jì)算GPU設(shè)備,在保持圖形性能的前提下,F(xiàn)ermi架構(gòu)將通用計(jì)算技術(shù)提升到前所未有的高度,具體表現(xiàn)在[3]:計(jì)算資源更為豐富,每個(gè)多處理器擁有32個(gè)CUDA(Compute Unified Device Architecture,統(tǒng)一計(jì)算設(shè)備架構(gòu))核心(最基本的運(yùn)算單元);其次,F(xiàn)ermi架構(gòu)引入了緩存機(jī)制,使GPU擁有真正意義的可讀寫L1緩存和L2緩存;浮點(diǎn)計(jì)算精度和速度也有大幅提高。
與傳統(tǒng)CPU方式不同,對(duì)于CUDA并行處理程序設(shè)計(jì),要獲得比較高的性能,需要考慮幾個(gè)方面:首先是存儲(chǔ)器操作,CPU的內(nèi)存存取延遲主要是通過多級(jí)緩存來消除,而CUDA主要通過高度并行化和合并訪問的方式來達(dá)到高的帶寬利用率,即使在新一代Fermi架構(gòu)下讓CUDA程序盡可能滿足合并訪問,也會(huì)明顯地提高性能;其次,并行處理方式的設(shè)計(jì),即如何提高運(yùn)算并行度,盡可能的使GPU占用率高。
第一部分已經(jīng)介紹所作研究的相關(guān)背景和技術(shù)介紹,在第二部分中將詳細(xì)闡述設(shè)計(jì)的并行算法。實(shí)驗(yàn)數(shù)據(jù)的結(jié)果及相關(guān)分析討論放在的第三部分;最后在第四部分給出了工作總結(jié)和對(duì)未來工作的展望。
2 Fermi架構(gòu)平臺(tái)下基于各向異性擴(kuò)散斑點(diǎn)噪聲抑制并行處理算法
2.1 各向異性擴(kuò)散斑點(diǎn)噪聲抑制算法概述
各向異性擴(kuò)散斑點(diǎn)噪聲抑制算法的核心是基于局部相干性,并且采用加性算子分裂方法進(jìn)行離散化完成快速斑點(diǎn)噪聲抑制。基于局部相干性信息的半隱式各向異性擴(kuò)散的超聲圖像斑點(diǎn)噪聲抑制算法[3]主要包括低通濾波、擴(kuò)散系數(shù)表和三對(duì)角矩陣的生成及解三對(duì)角線性方程組三個(gè)環(huán)節(jié)。首先,各向異性擴(kuò)散方程定義如下:

其中,擴(kuò)散系數(shù)l(·)定義如下:
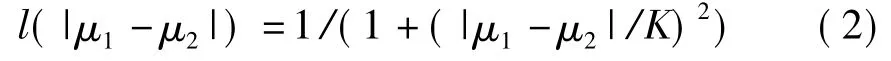
μ1和μ2是每點(diǎn)處結(jié)構(gòu)矩陣的特征值,結(jié)構(gòu)矩陣的定義為:J(▽Iσ)=(▽Iσ·▽ITσ)。▽Iσ是通過與一個(gè)二維高斯核進(jìn)行卷積(方差為σ)得到的模糊的原圖像I的梯度。把(1)式轉(zhuǎn)化為一個(gè)矩陣和向量的形式,并且采用加性算子分裂方法離散化,即得如下方程:
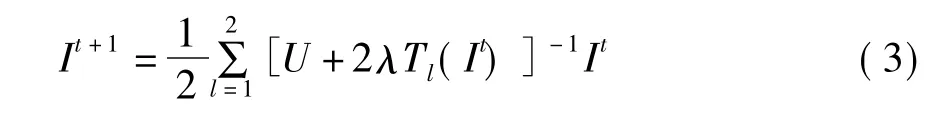
其中U是一個(gè)KL×KL的單位矩陣(K,L分別為圖像的高和寬),λ是迭代步長,Tl(It)是一個(gè)三對(duì)角陣,Tl(It)=[tij(It)]。
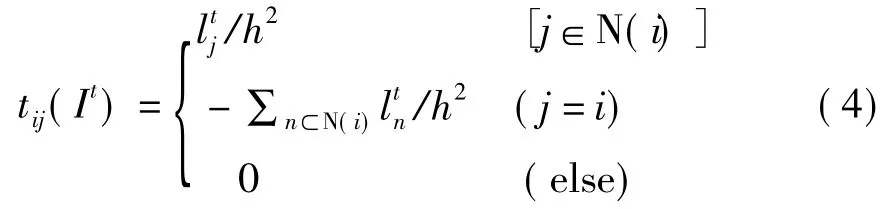
此處,l是擴(kuò)散系數(shù)。N(i)是一個(gè)像素在某一個(gè)維度上i的兩個(gè)相鄰點(diǎn)的集合。h為濾波窗口的大小。
2.2 數(shù)據(jù)準(zhǔn)備階段
利用GPU平臺(tái)進(jìn)行通用計(jì)算,相比較一般CPU的處理方式,算法的參數(shù)和數(shù)據(jù)都必須首先從主機(jī)端傳送到設(shè)備端才可以進(jìn)行處理,主機(jī)端和設(shè)備端都有多種具有不同性能特性的存儲(chǔ)器。因此在并行算法設(shè)計(jì)與實(shí)現(xiàn)時(shí)需要綜合考慮以減少數(shù)據(jù)傳輸?shù)拈_銷。本算法中主要的處理數(shù)據(jù)是圖像數(shù)據(jù),而參數(shù)包括單個(gè)的系統(tǒng)參數(shù)如算法閾值,圖像大小等。這些數(shù)據(jù)的存儲(chǔ)器選擇策略如下:
在主機(jī)端,主要進(jìn)行的處理數(shù)據(jù)是每一幀圖像。而在CUDA平臺(tái)上為內(nèi)存開放了兩種類型的存儲(chǔ)器,分頁內(nèi)存和頁鎖定內(nèi)存。頁鎖定內(nèi)存的帶寬會(huì)比分頁內(nèi)存高出2倍多。頁鎖定內(nèi)存一共提供了4種工作模式。其中,寫結(jié)合模式可以使數(shù)據(jù)在通過PCI-e總線傳輸時(shí)不會(huì)被監(jiān)視,這能夠獲得高達(dá)40%的傳輸加速,是最適合CPU是只寫的情況。由于輸入數(shù)據(jù)對(duì)于CPU來講是只寫的,因此可以使用頁鎖定內(nèi)存中的這種寫結(jié)合模式[6]。
在設(shè)備端,由于Fermi架構(gòu)對(duì)全局存儲(chǔ)器引入了緩存機(jī)制,因此可以使用二維對(duì)齊的線性顯存空間存放來自主機(jī)端的輸入數(shù)據(jù)。另外在實(shí)現(xiàn)中,可以將一些預(yù)定義好的單個(gè)參數(shù)合并入一個(gè)數(shù)組放入常量存儲(chǔ)器供所有線程訪問,這樣不僅可以充分利用常量存儲(chǔ)器帶寬,也可以減少寄存器的占用率以提高整體運(yùn)行的并行度。
2.3 低通濾波
在各向異性擴(kuò)散方法中每次迭代都要先對(duì)原始圖像進(jìn)行一個(gè)低通濾波處理,常用的低通濾波器是高斯濾波器。它通常使用一個(gè)高斯核卷積實(shí)現(xiàn)。這里使用的是5×5的高斯核。對(duì)于一個(gè)2維的高斯卷積,為了減少冗余計(jì)算,可以將其分解為兩個(gè)1維高斯核分別沿X,Y軸作卷積的結(jié)果。同時(shí),可以用一個(gè)均值濾波代替高斯濾波。通過測(cè)試,兩者的處理效果基本一致。但在CUDA程序設(shè)計(jì)時(shí),采用均值濾波的處理能力更快,具體的并行實(shí)現(xiàn)方式是啟動(dòng)兩個(gè)核函數(shù)分別進(jìn)行沿X方向和沿Y方向的處理。讓一個(gè)線程負(fù)責(zé)處理一行或一列,X方向的示意如下:
這里需要注意的是在沿X方向處理時(shí),相鄰線程訪問的圖像像素點(diǎn)是隔開的,并不滿足合并訪問規(guī)則,全局存儲(chǔ)器在這種情況下效率極低。因此在進(jìn)行X方向?yàn)V波時(shí),圖像數(shù)據(jù)應(yīng)綁定到紋理存儲(chǔ)器,然后將X方向一維濾波輸出寫入到全局存儲(chǔ)器中供Y方向?yàn)V波使用。在進(jìn)行沿Y方向?yàn)V波時(shí),由于相鄰線程同時(shí)讀取圖像一行的像素值(物理上是相鄰并且對(duì)齊存儲(chǔ)的),所以滿足了全局存儲(chǔ)器的合并訪問條件,實(shí)現(xiàn)最優(yōu)化訪存。
2.4 擴(kuò)散系數(shù)表和三對(duì)角矩陣的生成計(jì)算
由公式(3)可知,本算法需要進(jìn)行多次迭代才能得到比較好的去噪效果,在每一次迭代中,擴(kuò)散系數(shù)是不同的。如果在每次迭代過程中都要計(jì)算擴(kuò)散系數(shù),就會(huì)大大降低算法的效率[7]。于是在設(shè)計(jì)中采用生成擴(kuò)散系數(shù)表,每次迭代用查表的方式得到擴(kuò)散系數(shù),這樣就減少了大量的冗余計(jì)算。因?yàn)閿U(kuò)散系數(shù)與圖像上某點(diǎn)的梯度有關(guān),而梯度分量的取值范圍為-255~255,所以生成的擴(kuò)散系數(shù)表的大小為511×511。同時(shí),利用式(4)查表可以得到三對(duì)角矩陣。
值得注意的是,為了減少數(shù)據(jù)傳輸時(shí)間,將擴(kuò)散系數(shù)表的生成放在了GPU端,由多線程核函數(shù)完成。同時(shí)這里的擴(kuò)散系數(shù)表在查表時(shí)是具有一定隨機(jī)性的,因此采用二維紋理存儲(chǔ)器來存儲(chǔ)它,這樣在查表的過程中就可以通過紋理緩存機(jī)制實(shí)現(xiàn)比較好的帶寬利用率。二維紋理綁定的具體實(shí)現(xiàn)如下:
使用cudaMallocArray函數(shù)分配專為紋理拾取而優(yōu)化的顯存存儲(chǔ)空間CUDA Array空間存放數(shù)據(jù)。然后設(shè)置紋理通道參數(shù)來決定紋理拾取的工作條件,并利用cudaBindTexture函數(shù)將擴(kuò)散系數(shù)表綁定到紋理存儲(chǔ)器。
2.5 解三對(duì)角線性方程組
本算法需要要解出的三對(duì)角線性方程組有如下形式:
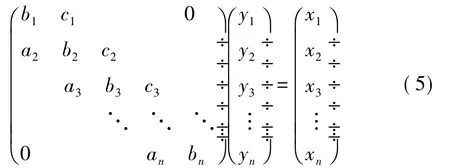
其中 ai,bi,ci和 xi,i=1,…,n,為已知。而解上式的三對(duì)角線性方程組是實(shí)現(xiàn)加性算子分裂方式離散化各向異性擴(kuò)散方法的關(guān)鍵。在CPU上,一般使用Thomas算法求解三對(duì)角線性方程組[8]。Thomas算法是一種高效的串行算法,但是它并不能完全發(fā)揮GPU的并行計(jì)算能力,因此需要尋找一種能夠并行化的求解方法。使用循環(huán)約化的方法來解這個(gè)三對(duì)角線性系統(tǒng)[5],可以在GPU上并行的實(shí)現(xiàn)。
采用GPU進(jìn)行處理的循環(huán)約化的方法主要由四個(gè)部分組成:
(1)對(duì)圖像的每一行建立一個(gè)三對(duì)角矩陣。
(2)并行地解三對(duì)角矩陣。
(3)對(duì)每一列重復(fù)以上兩個(gè)步驟,即對(duì)圖像的每一列建立三對(duì)角矩陣。
(4)循環(huán)約化法使用的是高斯消去法迭代地并行消去三對(duì)角矩陣中的奇數(shù)行。其偽代碼如下:
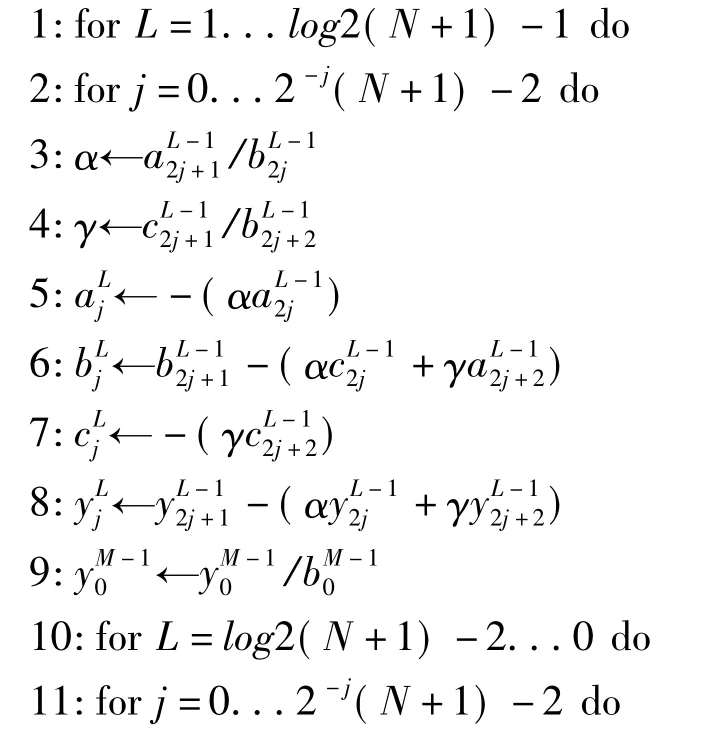
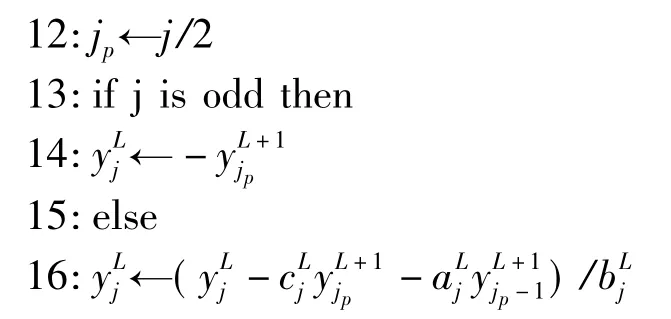
在GPU平臺(tái)上實(shí)現(xiàn)時(shí),設(shè)計(jì)兩個(gè)CUDA核函數(shù)分別處理行向和列向。在線程結(jié)構(gòu)方面,讓一個(gè)線程對(duì)應(yīng)與一行或一列,由于是在Fermi平臺(tái)下,每個(gè)線程塊內(nèi)設(shè)計(jì)應(yīng)至少為2個(gè)warp塊,即64個(gè)線程,對(duì)于此處測(cè)試所用的平臺(tái),為了盡可能利用多處理器,塊內(nèi)線程數(shù)設(shè)置較小,在其它應(yīng)用場(chǎng)合最好根據(jù)圖像數(shù)據(jù)規(guī)模合理設(shè)置線程結(jié)構(gòu),以盡可能利用GPU計(jì)算資源。
在存儲(chǔ)器使用方面,在Fermi架構(gòu)下全局存儲(chǔ)器已提供了L1緩存機(jī)制,因此在核函數(shù)處理設(shè)計(jì)時(shí)沒有使用共享存儲(chǔ)器作為中間運(yùn)算的載體。而是直接在全局存儲(chǔ)器完成,這里為了讓L1更好的工作,使用cudaFuncSetCacheConfig函數(shù)將這兩個(gè)核函數(shù)的執(zhí)行配置設(shè)為L1優(yōu)先模式,即讓L1擁有48KB的空間,參數(shù)項(xiàng)為cudaFuncCachePreferL1。
2.6 圖像顯示
經(jīng)過圖像后處理的超聲圖像顯示數(shù)據(jù)存放在顯存上,要進(jìn)行顯示,既可以寫回主機(jī)端然后進(jìn)入圖形學(xué)管線進(jìn)行繪制,也可以直接利用CUDA技術(shù)與圖形學(xué)管線的互操作接口如OpenGL進(jìn)行資源共享。后者可以將顯存中存放的數(shù)據(jù)直接寫入到圖形學(xué)紋理體素空間中進(jìn)行圖像渲染顯示,這就避免內(nèi)存和顯存進(jìn)行數(shù)據(jù)傳輸?shù)臅r(shí)間消耗。具體的實(shí)現(xiàn)方式是首先初始化OpenGL設(shè)備,然后進(jìn)行紋理資源創(chuàng)建與注冊(cè),并設(shè)定資源的讀寫屬性。在把CUDA中處理完畢的圖像數(shù)據(jù)寫入到OpenGL紋理空間,就可以進(jìn)行圖像渲染,最后釋放占有的資源。
3 實(shí)驗(yàn)結(jié)果與分析
實(shí)驗(yàn)平臺(tái)為 2.20GHz的 AMD Althlon(tm)644200+,操作系統(tǒng)為Windows XP。GPU為 NVIDIA Geforce GTX 560 Ti,顯存為 1GB,核心頻率 1.645GHz,14個(gè)多處理器,使用4.0版本的CUDA toolkit及對(duì)應(yīng)的開發(fā)包。編程環(huán)境為Visual Studio 2010。
為了測(cè)試提出的并行實(shí)現(xiàn)算法的處理效果和運(yùn)行效率,使用由數(shù)字超聲掃描器在超聲系統(tǒng)iMago C21上采集得到的人體數(shù)據(jù)作為研究工作的實(shí)驗(yàn)數(shù)據(jù)。圖1(a)和(b)顯示的是由3.5MHz凸陣掃描器采集得到的人體組織的超聲原圖像,(c)和(d)是斑點(diǎn)噪聲抑制后CPU處理結(jié)果。(e)和(f)是斑點(diǎn)噪聲抑制后GPU的處理結(jié)果。通過對(duì)比知道CPU和GPU的處理結(jié)果完全保持一致,圖像像素值誤差為0,其中算法迭代次數(shù)為4,步長設(shè)置的是1.5。
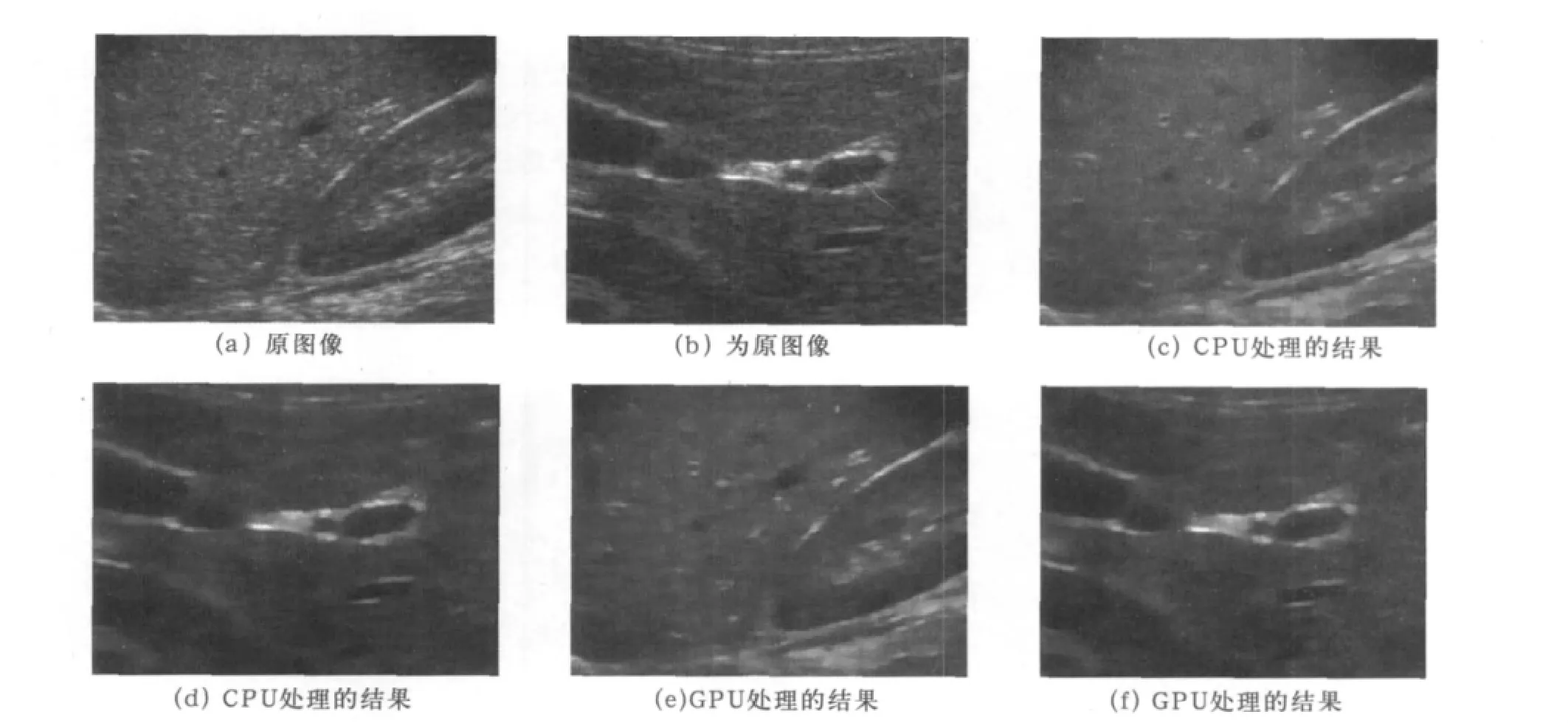
圖1 采用超聲凸陣掃描器采集得到的人體組織圖像分別測(cè)試CPU和GPU的去噪效果對(duì)比圖
表1給出了所研究的斑點(diǎn)噪聲算法CPU和GPU處理的性能比較。程序的運(yùn)行時(shí)間是圖像數(shù)據(jù)進(jìn)入顯存后進(jìn)行噪聲抑制處理的全部運(yùn)行時(shí)間。從表1可以明顯看出,基于Fermi架構(gòu)GPU并行處理算法相比較于傳統(tǒng)的CPU串行處理提高了大約120倍。加速比也說明了數(shù)據(jù)計(jì)算規(guī)模越密集,GPU并行加速效果越明顯。
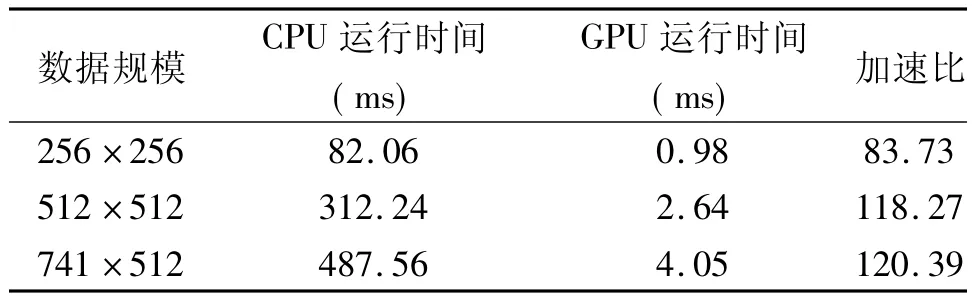
表1 性能比較
4 結(jié) 束 語
實(shí)驗(yàn)結(jié)果顯示了基于Fermi架構(gòu)GPU的超聲斑點(diǎn)噪聲抑制并行實(shí)現(xiàn)方法得到的圖像去噪質(zhì)量和通用CPU處理的結(jié)果保持基本一致,而在時(shí)間性能方面達(dá)到了實(shí)時(shí)系統(tǒng)的處理要求,得到大約120多倍的加速效果。在這樣的GPU處理效率下,使用各向異性的方式進(jìn)行超聲圖像斑點(diǎn)噪聲抑制不僅可以取得比較好的圖像噪聲抑制效果,也可以滿足臨床超聲檢測(cè)系統(tǒng)的實(shí)時(shí)處理要求。另一方面,從加速比的分析來看,也說明了GPU并行處理平臺(tái)對(duì)于計(jì)算密集的情況加速效果更好,這與Gustafson加速比模型分析一致[9]。
[1]李治安.臨床超聲影像學(xué)[M].北京:人民衛(wèi)生出版社,2003.
[2]J.Weichert,B.Romeny,M.A.Viergever.Efficient and reliable schemes for nonlinear diffusion filtering[J].Image Processing,1998,7(3):398 -410.
[3]NVIDIA Corporation.CUDA ProgrammingGuide4.0[S/OL].[2011 -05 -06].http://www.nvdia.com.
[4]夏春蘭,石丹,劉東權(quán).基于CUDA的超聲B模式成像[J].計(jì)算機(jī)應(yīng)用研究,2011,28(6):2011 -2015.
[5]范正娟,劉東權(quán).基于CUDA的超聲彩色血流成像[J].計(jì)算機(jī)應(yīng)用,2011,31(3):856 -859.
[6]NVIDIA Co..CUDA API Reference Manual 4.0[M].Santa Clara,CA,2011.
[7]Wang,Bo,Tan,Chaowei,Liu Dong C.Local Coherence based Fast Speckle Reducing Anisotropic Diffusion[C].Proceedings of 2008 International Pre-Olympic Congress on Computer Science,Nanjing:IACSS,2008:304 -309.
[8]Krüger J.,Westermann R..Linear Algebra Operators for GPU Implementation of Numerical Algorithms[J].ACM Transactions on Graphics.2003,22(3):908 -916.
[9]孫世新.并行算法及其應(yīng)用[M].北京:機(jī)械工業(yè)出版社,2005.
猜你喜歡
物理化學(xué)學(xué)報(bào)(2025年3期)2025-03-20 00:00:00
傳染病信息(2022年6期)2023-01-12 08:57:54
甘肅科技(2020年20期)2020-04-13 00:30:42
數(shù)學(xué)物理學(xué)報(bào)(2018年4期)2018-09-14 03:41:02
磁共振成像(2015年9期)2015-12-26 07:20:32
磁共振成像(2015年7期)2015-12-23 08:53:09
腫瘤影像學(xué)(2015年3期)2015-12-09 02:38:51
上海金屬(2015年5期)2015-11-29 01:13:59
上海金屬(2015年6期)2015-11-29 01:09:09
數(shù)學(xué)物理學(xué)報(bào)(2015年2期)2015-02-28 16:06:39
