基于語音編碼中自適應碼本的隱藏信息方法
2013-09-11 03:20:52楊婉霞孫東紅黃永峰
計算機工程與設計 2013年8期
楊婉霞,孫東紅,黃永峰
(1.甘肅農業大學 工學院,甘肅 蘭州730070;2.清華大學 信息科學技術學院,北京100084)
0 引 言
信息隱藏是一種在最近幾年開始得到應用的信息安全傳遞技術。但目前信息隱藏所使用隱藏載體主要是圖像和視頻等文件,對使用語音、特別是低速率語音作為隱藏載體的研究成果卻比較少。然而,在目前人們網絡交互方式中,語音通信是主要方法。例如,電話、移動通信、VoIP(voice over IP)、語音即時通信等等 。而且這些語音通信中,基本都是采用低速率語音編碼。因此,研究以低速率語音為信息隱藏載體具有十分重要的學術意義和實際價值。目前,比較流行的低速率編碼典型代表有 G.723.1、G.729a等。尤其是專為互聯網設計的低速率語音編解碼器iLBC (internet low bit rate codec),因 其 語 音 質 量 優 于G.729A和G.723.1等常用低速率語音編碼器,以及具有良好抗丟包性能,日益得到越來越多的應用。例如SKYPE之所以發展如此迅猛,主要歸功于使用了iLBC語音編碼。因此,研究以iLBC為隱藏載體的信息隱藏技術,具有很大應用前景[1]。然而,由于信息隱藏技術是利用媒體信息中的冗余來嵌入秘密信息,而低速率語音在壓縮編碼過程中盡可能大的去除冗余信息,而且人耳對語音極其敏感。因此,如何在低速率語音中實現信息隱藏是十分具有挑戰性的研究方向。
1 相關研究工作
目前,針對低速率壓縮編碼器的信息隱藏研究內容還比較少,傳統的語音信息隱藏方法針對的對象是脈沖編碼調制 (pulse-code modulation,PCM)[2]。這些方法都難以直接應用于低速率壓縮語音。原因是語音信號經過壓縮,已經去除了很多冗余信息,使得信息嵌入容量有限且難以提取。目前與低速率語音壓縮信息隱藏算法相關的研究有:Chang等人提出了適用于 MELP和G.729a編碼的基于多級矢量量化信息隱藏算法[3];Huang等人也引入了LSB(least significant bit)matching 的方法替代傳統的 LSB 方法,取得了較好的隱藏效果[4]。Yang等人通過對G.729a算法特性的研究,提出了一種基于碼書位置向量的信息隱藏算法,并通過抗噪性分析得出了固定碼書是適合信息隱藏的最佳位置的結論[5]。Xiao等人引入量化索引調制(quantization index modulation,QIM)方法提出了一種針對低速率語音編碼的信息隱藏方法[6]。文獻 [7,8]等從不同角度分析了G.729a幀中的各參數,總結了G.729a中可用于信息隱藏的且具有較高透明性的最低有效位。
從目前國際國內的研究現狀來看,雖然有一些針對低速率語音壓縮的研究成果,但大部分只是對編碼參數簡單的LSB和改進的LSB嵌入算法,這樣的算法不僅容易受到統計檢測攻擊,而且容易對重構語音質量造成較大的影響[10]。因此,如何更有效的利用參數壓縮編碼特點,研究在語音編碼的壓縮域中進行信息隱藏是本文研究的主要問題。
2 基于iLBC編碼的壓縮域信息隱藏方法
2004年12月IETF發布了專為互聯網設計的編解碼算法iLBC。iLBC的語音質量優于G.729A和G.723.1。在出現丟包時,仍可以獲得非常清晰的語音效果,其語音質量更要優于其他低比特率編碼方式,這是iLBC算法得到越來越多的應用原由。因此,研究iLBC的信息隱藏方法成為一個熱點。
2.1 基于iLBC編碼原理
iLBC是基于碼本激勵線性預測模型。該模型對語音進行一系列分析,得到一組能夠表示語音特征的參數,將這些參數編碼封裝發送,接收方根據接收到的這些特征參數對語音進行恢復。因此,iLBC語音編碼經歷了多個編碼環節,其中之一是自適應碼本編碼。論文針對iLBC的自適應碼本編碼過程特點,建立一種基于動態碼本量化的信息隱藏算法。
(1)碼本存儲構建。碼本是由碼本存儲構成的,碼本存儲的大小為85/147bit。下面以30ms幀為例分析碼本存儲的構建原理。如圖1所示。初始狀態是第二和第三個子幀的后58個樣本,編碼時,在初始狀態前的子塊的碼本存儲要進行時間反轉。首先編碼的是子塊1,由于位于開始狀態前,所以要進行反轉,由于存儲有85位,而初始狀態只有58位,剩余的位用0填滿。如1(b)所示。編碼子塊2時,子塊1已經編碼完成,對應的碼本存儲如1(c)所示,碼本存儲有147位,剩余用0填充。對子塊3,4也如此。對于子塊5,由于在初始狀態之前,所以碼本存儲要進行時間反轉,如1(f)所示。
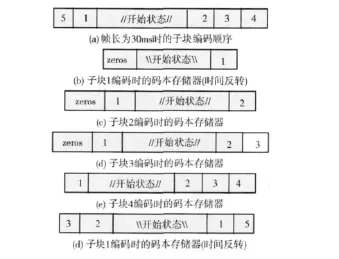
圖1 子塊編碼順序及對應的碼本存儲
(2)碼本的構建:碼本由基礎碼本和擴展碼本兩部分組成,基礎碼本和擴展碼本都包含一個稱為增值碼本的部分。將碼本存儲通過一個8階的FIR濾波器,然后按照基礎碼本的建立方法得到一個擴展碼本。擴展碼本其實是基礎碼本中向量的線性組合。擴展碼本中也含有增值碼本。增值碼本擁有20個碼字,建立方法如圖2所示。增值碼本的第一個碼字以碼本存儲中的第127個數據開始,由三部分組成:第一部分是圖中指針pp之后的15個數據;第二部分是指針pp前的5個數據和最后5個數據的線性組合;第三部分是由指針pp后的20個數據構成。
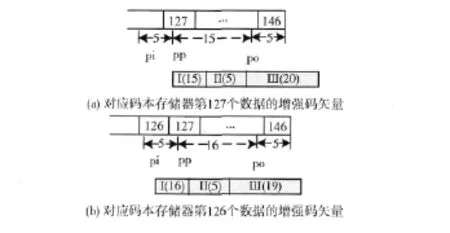
圖2 增值碼本創建過程
(3)碼本搜索。碼本搜索三級增益形成匹配方法。首先計算出每個階段的最佳匹配向量,然后計算最佳匹配向量的增益并量化增益,更新目標向量進行下一階段的匹配。碼本搜索的主要步驟如下:
1)最佳匹配感知權重向量需要滿足如下3個條件:
a.計算度量,如公式 (1)所示:選擇碼本中的碼字向量使其最大

公式 (1)cbvec表示選擇的碼本向量,target表示目標碼本向量。
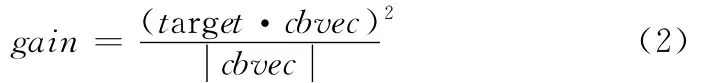
c.在第一階段匹配時,選擇最佳碼本向量與目標向量的點積必須大于0,即滿足式 (3)

2)量化每個階段的增益。3個階段的增益都要進行量化,分別使用5、4和3位來進行量化。
3)更新感知權重目標。在執行第二第三階段的搜索之前,要用加權后的目標向量減去選擇的目標碼本乘以相應的量化后的增益來更新感知加權的目標向量。
2.2 基于碼本搜索的壓縮域隱藏方法
基于上述自適應碼本構建過程,采用QIM (quantization impulse modulation)原理來建立一種基于iLBC動態碼本量化的信息隱藏方法,如圖3所示。因為,動態碼本中的碼字相對較多,對其實現信息隱藏所帶來的誤差,相比之下對語音質量影響較小;而且,動態碼本進行編碼時分為3個階段,每個階段結束以后都會對目標向量進行更新,也就是說在第一階段和第二階段量化都是精確的,只有第三階段會產生量化誤差,這就保證了語音的質量。但是,動態碼本和其他3個位置的靜態碼本的不同點在于:在編碼過程中動態碼本身是一直在改變的,編碼每個子幀時都要對動態碼本進行分區,而靜態碼本分區一次就可以。
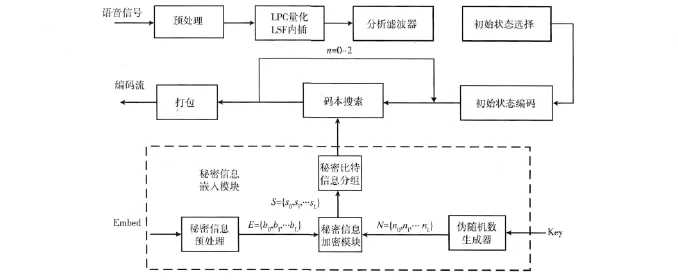
圖3 壓縮域隱藏信息的嵌入方法
(1)隱藏信息的嵌入算法設計
在自適應碼本的編碼過程中,根據嵌入機密信息的比特來控制選擇是在奇數索引還是偶數索引所代表的碼本中進行匹配。動態編碼一共3個階段,因此要重復三次,具體嵌入算法的流程如下所述。
信息隱藏的嵌入算法描述
1)將機密信息經過處理得到二進制的秘密信息比特流。
2)對得到的二進制秘密信息利用偽隨機碼發生器進行加密操作。得到加密后的二進制比特流。
3)由碼本存儲構成待編碼子幀編碼所需的動態碼本。
4)動態編碼第一階段,根據當前需要嵌入的機密信息的值來選擇所需碼本,若機密信息為1則選擇在索引為奇數的碼字作為當前碼本,若機密信息為0則在索引為偶數的碼字作為當前碼本。
5)對目標向量與當前碼本中碼字進行匹配,得到索引號以及增益。然后對目標向量進行更新。秘密信息已經嵌入,向后移一位。
6)動態編碼第二階段,重復4)5)的操作。
7)動態編碼第三階段,重復4)5)的操作。
8)若秘密信息已經嵌入完畢或已無載體則結束,否則回到第3)步。
(2)信息隱藏的提取算法設計
在接收端收到含有秘密信息的語音信號時,對其進行iLBC解碼,然后獲取秘密信息。如圖4所示。解碼的第1步驟是解析編碼參數,其中最主要的是碼本索引參數。碼本索引參數記錄的是在編碼時動態編碼3個階段選擇的最佳匹配向量的索引號,根據索引號的奇偶性就可以判斷嵌入比特位。
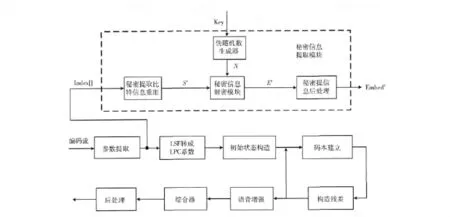
圖4 壓縮域隱藏信息的提取方法
提取算法描述
1)接收端對接收到的語音包進行解析,并獲取各個參數。
2)對其中碼本索引的參數進行分析獲得索引的值。注意此時解析的是一幀數據而不是一個子幀,因此對20ms的幀而言,獲得的碼本索引參數包含9bit的秘密信息,對于30ms的幀,獲得的碼本索引參數包含15bit的秘密信息。
3)判斷索引值的奇偶來決定當前秘密信息位是0還是1。
4)將提取得到的秘密信息進行整合,形成機密信息比特流。
5)通過利用和發送方相同的密鑰,對加密的機密信息流進行解密處理,獲得被隱藏的秘密信息。
3 算法實驗結果與性能分析
對于一種信息隱藏性能分析,主要是從隱蔽性和隱藏容量兩個方面來衡量[11]。
3.1 隱藏容量分析
通過對上述隱藏算法的分析可以從理論上計算得到二種不同幀結構下的機密信息隱藏容量:
(1)對于30ms幀結構的隱藏容量
由前面動態碼本編碼原理分析可知:由于每個幀分為5個子幀,每個子幀進行了3個階段量化編碼,嵌入算法是動態碼本分區來隱藏信息。因此,可以得到30ms幀結構下的信息隱藏容量如式 (4)來計算
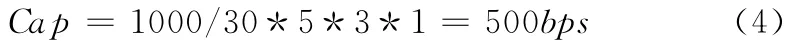
(2)對于20ms幀結構的隱藏容量
同理,我們也可以建立20ms幀結構的隱藏容量計算方法,如式 (5)來計算。由于20ms幀結構分為3個子幀
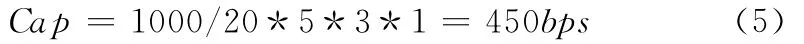
從計算結果可以看出,這種算法的隱藏容量對低速率語音編碼載體來說,是比較理想的結果。
3.2 iLBC編碼信息隱藏算法的隱蔽性分析
對于以語音為載體的信息隱藏算法,其隱蔽性的好壞主要對比測試載密和非載密情況的語音質量。對語音質量的評價,國際上常采用標準語音質量評測工具來測試PESQ值[11]。本文也是采用該方法來評價隱藏算法的隱蔽性。
實驗采用中文男聲、中文女聲、英文男聲、英文女聲4組不同類型的語音樣本。每組語音各有20段。首先要判斷隱藏信息提取的準確性,然后通過對只進行編解碼不隱藏信息得到的語音質量和進行隱藏后得到的語音質量的比較,來判斷隱藏算法的優劣。語音質量的好壞用PESQ值來表示。對iLBC編碼,有兩種幀結構,下面分別對這二種幀進行測試。其中圖5是30ms幀結構下的隱蔽性測試結果,分別對比了進行信息隱藏和未信息隱藏時20段語音樣本對應的PESQ值。圖6是20ms幀結構下的隱蔽性測試結果,對比了進行信息隱藏和未信息隱藏時20段語音樣本對應的PESQ值。
通過對不同種類的語音載體進行測試,可以看出在信道良好的條件下,iLBC語音編碼中的隱藏算法能夠保證秘密信息的準確性。同時載體語音的質量也沒有受到嵌入機密信息的影響而產生很大變化。另外,也可以看出對于環境情況不太好時,即有很多噪音時,隱藏算法對語音質量改變相對較小,這是因為秘密信息對于載體語音而言就相當于噪聲,有一部分秘密信息湮沒在了噪聲中,因此,對語音質量改變較小,隱蔽性會更好些。
另外,對PESQ平均值和方差進行了進一步分析,計算了不同條件的平均值和方差,從而來評估隱藏算法隱蔽性能的平穩性。其中,表1是4組語音測得PESQ平均值,以及與文獻 [8]隱藏算法 (CNV)的隱蔽性比較。該算法也是采用QIM方法進行隱藏,但是采用靜態碼本,本文是采用動態碼本。表2是4組語音測得PESQ值變化的平均值和方差。
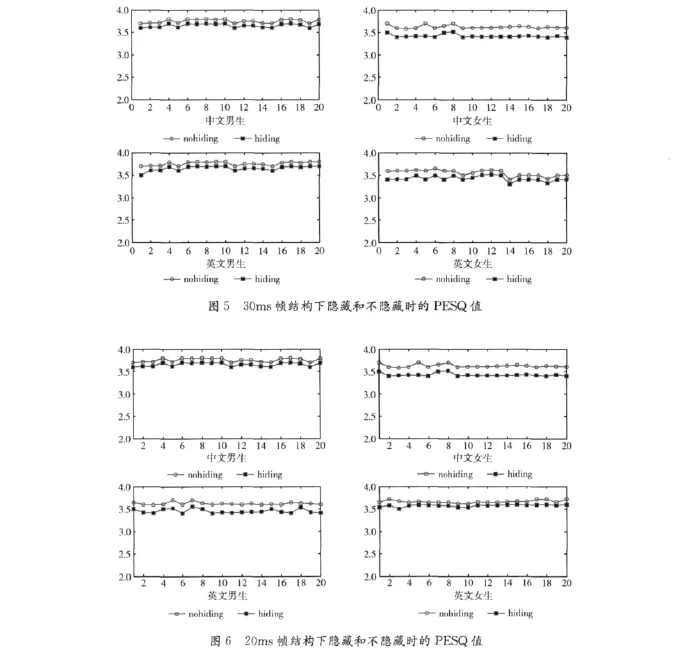
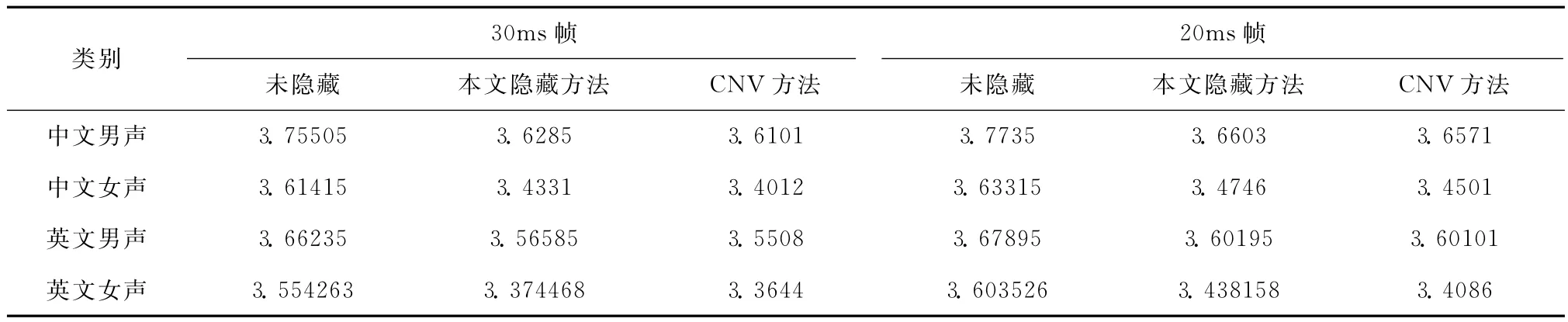
表1 4組語音測得PESQ平均值
從表1可以看出,論文采用動態碼本載體的隱藏方法, 從語音質量的隱蔽性比文獻 [8]靜態載體要好,文獻 [8]采用的CNV碼本隱藏方法是目前國際性能最好方法之一。而且,本論文提出的動態載體還具有對抗統計分析的隱蔽性能。另外,從表1表2中還可以發現,相對于非載密情況,載密條件下語音質量的PESQ值的方差增大。也就是說,在iLBC語音編碼使用隱藏算法來隱藏信息情況下,語音質量更容易受到外界的干擾。同時,還可以發現iLBC20ms幀結構比30ms幀結構更能獲得穩定的語音質量。
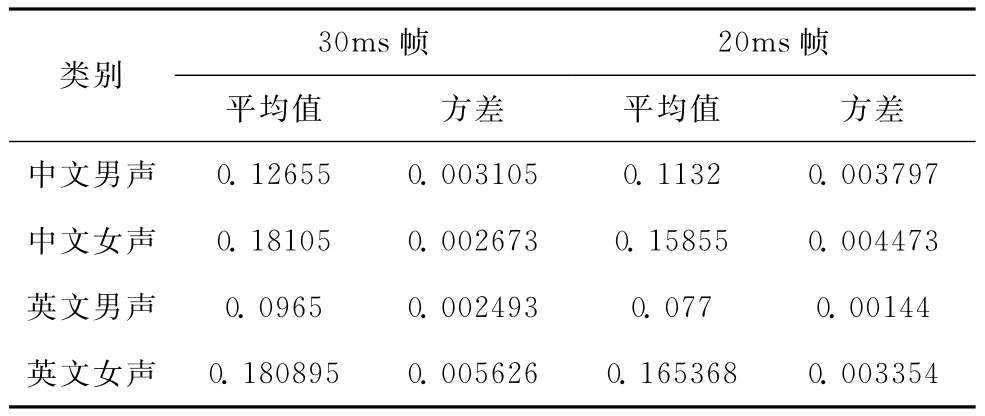
表2 4組語音測得PESQ值變化的平均值和方差
最后,我們還對30ms幀結構和20ms幀結構的隱蔽性進行了比較。主要是對比分析了30ms幀結構和20ms幀結構在載密情況下的語音質量變化情況。iLBC的這兩種幀結構在具體應用中產生的效果不一樣,將4種不同的聲音樣本共80段語音經過iLBC編解碼后語音質量關系如圖7所示。
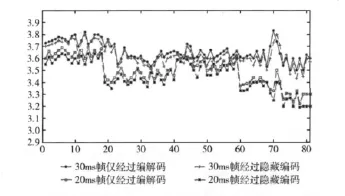
圖7 20ms和30ms幀的PESQ值比較
從圖7中可以得到以下結論:①僅對于iLBC語音編碼而言,選擇20ms或30ms幀結構對語音質量的影響基本一樣。不同的只是傳輸速率。②對于動態碼本信息隱藏算法而言,更適合用20ms幀結構來實現,從圖上可以看出,20ms幀結構隱藏后的語音質量明顯比30ms幀結構要好,因此以后選用此方法進行隱藏時用20ms幀結構較好。
4 結束語
基于低速率語音編碼的信息隱藏是一項非常具有挑戰性工作。論文選擇目前廣泛應用的iLBC語音為研究對象,提出了一種基于動態碼本量化過程的壓縮域的信息隱藏方法,并研發了一套基于信息隱藏功能的iLBC編解碼軟件。實驗測試表明,該算法具有較好隱藏容量和很好隱蔽性能,特別是具有很好的對抗統計分析檢測能力。而且,該隱藏算法由于實現了編碼和隱藏計算的共享。因此該方法還有一個優點是運行速度快,算法復雜度低。可以應用于網絡閾下信道的構建等。未來的工作是進一步分析iLBC語音其他特征,進一步提高隱藏容量。
[1]Andersen S,Duric A Telio.Internet low bit rate codec(iLBC)[M].IETF RFC 3951,2004.
[2]Miao Rui,Huang Yongfeng.An approach of covert communication based on the adaptive steganography scheme on voice over IP [C]//IEEE International Conference on Communications,2011:1-5.
[3]Lu Z M,Yan B,Sun S H.Watermarking combined with CELP speech coding for authentication [C]//IEICE Transactions on Information and System,2005,E88-D (2):330-334.
[4]Huang Yongfeng,Yuan Jian,Tang Shanyu,et al.Steganography in inactive frames of VoIP streams encoded by source codec[J].IEEE Transactions on Information Forensics and Security,2011,6 (2):296-306.
[5]Yang Jun,Bai Sen,Huang Yongfeng,et al.Implementation of steganography based on HOOK [J].Advances in Intelligent and Soft Computing,2012 (112):133-141.
[6]Xiao B,Huang Y,Tang S.An approach to information hiding in low bit-rate speech stream [C]//Proceedings of the IEEE Global Telecommunications Conference,2008:1-5.
[7]Huang Yongfeng,Chen mingchao,Jian Yuan.Key distribution in the convert communication based on Voip [J].Chinese Journal of Electronics,2011,20(CJE-2):357-360.
[8]Tang Shanyu,Huang Yongfeng.Prediction of distortion patterns in image steganography by means of fractal computing[C]//The Third International Conferences on Pervasive Patterns and Applications,2011:128-132.
[9]Huang Yongfeng,Tang Shanyu,Bao Chunlai,et al.Steganalysis of compressed speech to detect covert VoIP channels [J].IEE/IEEE Journal.IET Information Security,2011,5 (1):1-7.
[10]Huang Y,Zhang Y,Tang S.Detection of covert VoIP communications using sliding window based steganalysis [J].IEE/IEEE Journal.IET Communications,2011,5 (2):126-133.
[11]Huang Y,Yuan J,Tang S,et al.Steganography in inactive frames of VoIP streams encoded by source codec [J].IEEE Transactions on Information Forensics and Security,2011,6(2):296-306.
猜你喜歡
中學生數理化·八年級物理人教版(2021年12期)2021-12-31 03:23:08
中學生數理化·中考版(2020年10期)2020-11-27 01:59:48
中國生殖健康(2019年2期)2019-08-23 08:12:08
產品可靠性報告(2017年7期)2017-09-05 09:49:12
中華手工(2017年2期)2017-06-06 23:00:31
汽車觀察(2016年3期)2016-02-28 13:16:26
中外會展(2014年4期)2014-11-27 07:46:46
中國質量與標準導報(2014年1期)2014-02-28 22:21:28
建筑創作(2001年3期)2001-08-22 18:48:14
祝您健康(1987年3期)1987-12-30 09:52:32
