MPI程序的性能優化方法研究*
2013-08-10 07:54:30闞亞斌張世燎
艦船電子工程 2013年7期
劉 鵬 闞亞斌 張世燎
(大連艦艇學院 大連 116018)
1 引言
MPI是目前集群系統最流行的并行編程環境之一。而且隨著科學與工程技術的發展,對計算量的需求越來越大。因此基于分布存儲的MPI并行編程模型也逐漸被廣泛應用。由于MPI是基于消息傳遞的并行模型,所以進程之間的通信必須通過顯示的調用MPI消息傳遞庫中的通信函數來實現。因此,如何在MPI并行程序中充分利用MPI提供的函數庫,如何從MPI函數庫提供的多種通信函數中有效的選擇通信函數,以及如何通過盡量減少通信開銷來提高并行程序性能已成為該領域研究熱點之一。本文兩次改進DNS的MPI程序實現,減少了程序的通信開銷,提高了程序性能,并通過兩次改進提出一個優化MPI并行程序的一般思路與方法。
2 只用Send和Receive調用來實現通信部分
盡管MPI函數庫提供了多種消息傳遞函數,但點對點通信仍然是所有通信函數的基礎[2],所以本文先完全以點對點通信函數來實現DNS算法的通信部分,用以和改進后的程序做比較。由MPI函數庫為每種阻塞通信形式都提供了相應的非阻塞通信形式[3],盡管非阻塞通信方式可以實現計算與通信的重疊,從而提高程序的性能,但是由于DNS算法本身計算和通信重疊的可能性不大,即使采用非阻塞的通信方式效率也不可能得以提高,所以本文選用阻塞的點對點通信 MPI_Send/MPI_Recv來實現DNS。
在程序中,由于只采用點對點通信函數 MPI_Send/MPI_Recv,所以起初的分布數據是由根進程root通過p-1(p:進程數)次 MPI_Send函數調用來將數據發送給其它進程的,而非root進程通過一次MPI_Recv函數調用來完成數據接收。各進程運算結束后,由根進程root通過p-1次MPI_Recv函數調用來完成數據收集,非root進程通過一次MPI_Send函數調用來將結果發送給root進程。
3 通過集群通信函數來改進程序
MPI函數庫不僅提供了點對點通信函數,還提供了豐富的集群通信函數,這些集群通信函數和點對點通信的一個重要區別就在于集群通信需要一個特定組內的所有進程同時參加通信,而不是像點對點通信那樣只涉及到發送方和接收方兩個進程。集群通信在各個不同進程的調用形式完全相同,而不像點到點通信那樣在形式上就有發送和接收的區別。這就為編程提供了方便性,也提高了程序的可讀性和移植性。
MPI提供的集群通信函數基本分為四類[4]:
1)一對多的通信操作,根進程發送相同數據到所有進程或分發不同數據到所有進程。例如廣播操作MPI_Bcast和數據分發操作MPI_Scatter。
2)多對一的通信操作,根進程從所有進程接收數據。例如數據聚集操作MPI_Gather。
3)多對多的通信操作,進程組中各進程從每個進程接收數據,或者各進程向每個進程分發數據并從每個進程接收數據。例如多對多的數據聚集操作MPI_Allgather和多對多的數據分發與聚集操作MPI_Alltoall。
4)進程組中所有進程進行全局數據運算,運算結果返回給根進程或所有進程,例如多對一的全局運算操作MPI_Reduce和多對多的全局運算操作MPI_Allreduce。
本文對程序的第一次改進是將通過調用點對點通信實現的數據分布和收集操作分別用 MPI_Scatter和 MPI_Gather操作來代替。本文對改進前后的程序性能做了對比,對比結果如圖1。
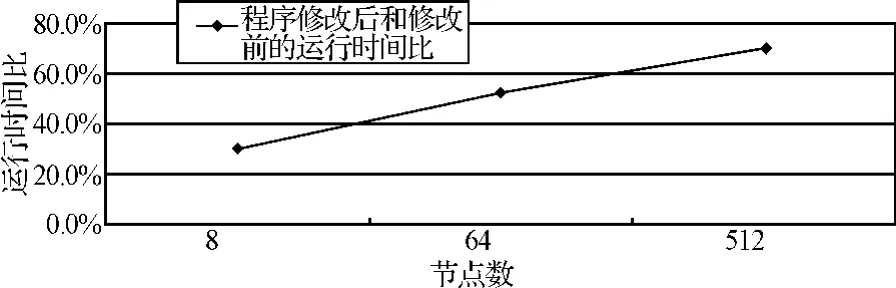
圖1 第一次改進后的性能優化
由圖1可見,改進后程序的運行時間比改進前有了明顯的縮短,這說明在實現集群通信時使用MPI提供的集群通信函數比使用點對點通信函數的性能好。但是隨著節點數的增加,兩者的差距逐漸縮小,甚至當節點數增加到足夠多時,修改后程序的運行時間有可能比修改前更長。這是因為在程序中使用集群通信函數時,通信域的參數直接使用了 MPI_COMM_WORLD,而該算法只要部分進程通信,因而增加了無效數據的傳輸開銷,且該開銷隨著節點數的增加而增大。
4 利用派生數據類型和建立新通信域來改進程序
4.1 通過派生數據類型減少通信次數
盡管MPI庫函數提供的所有通信函數在進行調用的時候,都有一個參數count和datatype。這兩個參數允許用戶把基本類型相同的多個數據項打包成一個基本的消息項。但是為了使用這項功能,被打包的數據項必須被存儲在連續的內存空間。因此,要發送存儲在非連續的內存空間中的多個數據項時,以上方法就無能為力了,就必須考慮使用MPI提供的兩種處理不連續數據的方法[5]:一是允許用戶自定義新的數據類型(又稱派生數據類型);二是數據的打包與解包,即在發送方將不連續的數據打包到連續的區域,然后發送出去,在接收方將打包后的連續數據解包到不連續的存儲空間。程序中由于兩矩陣之間數據的不連續性,導致進程間數據的傳輸需要兩次通信過程才能完成,降低了程序的性能。因此,本文考慮采用以上兩種方法之一來解決非連續數據的傳輸問題,以進一步提高程序效率。鑒于使用數據的打包與解包過程開銷相對過大,因此本文選擇使用派生數據類型的方法來改進程序。新數據類型的聲明,生成與提交如下:

程序中使用數據類型生成器MPI_Type_Contiguous派生出一個由兩個連續的整型數據構成的新數據類型。這樣,新建立的MPI數據類型可用于 MPI的任何通信函數中。當用它的時候,需要在數據類型參數的位置上寫上派生的數據類型。
4.2 通過分割通信域避免無效數據的傳輸
由于該程序中數據的分布與收集實際上只需要通信域中的部分進程參與,而程序中使用的集群通信函數的通信域的參數是預定義組內通信域 MPI_COMM_WORLD,這就意味著所有的進程都參與了該集群操作,其中n*n*(n-1)進程發送和接收了許多無效數據,增加了通信開銷。
為了解決這一問題,避免這種沒有必要的開銷,本文考慮使用MPI函數庫提供的用于建立新通信域與新進程組的相關函數 MPI_Comm_split(comm.,color,key,newcomm)。MPI_Comm_split對于通信域comm中的每一個進程都要執行,每一個進程都要指定一個color值,根據color值的不同,此調用首先將具有相同color值的進程形成一個新的進程組,新產生的通信域與這些進程組一一對應,新通信域中各個進程的順序編號是由key決定的。程序中通過調用MPI_Comm_split函數建立了一個由n*n個進程組成的新進程組與通信域。這樣在很大程度上改善了程序的性能。本文對改進前后的程序性能做了對比,對比結果如圖2。
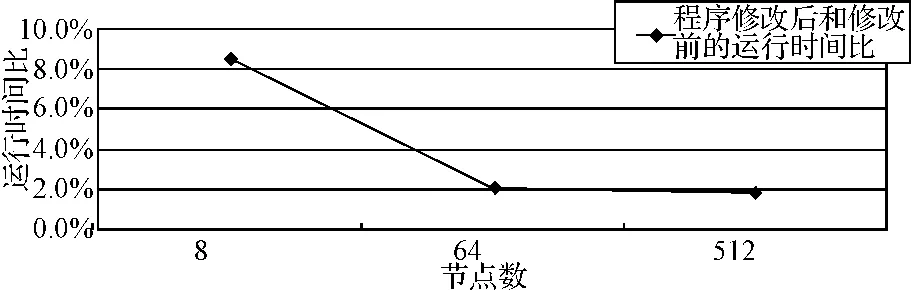
圖2 程序修改前后運行時間比
由圖2可見,程序經過兩次改進獲得了性能的提升,而且隨著節點數的增加,性能提升的幅度越大。
5 優化MPI并行程序的一般思路與方法
1)盡量使用MPI函數庫提供的集群通信函數。盡管有實驗表明MPI并沒有對集群通信操作的執行性能進行加速[6],但是在MPI并行程序設計當中,由于開發人員通常沒有考慮而且也不易設計出更優化的集群通信操作,所以在一般情況下,MPI并行程序選用MPI提供的集群通信函數比單純使用點對點通信函數能獲得更優的性能。而且集群通信函數給用戶提供了一個方便地進行集群通信的界面,在一定程度上簡化開發難度,也提高了程序的可讀性和移植性[7]。
2)通過數據打包以減少通信次數。據測試,發送一次消息的通信開銷相當于幾千次計算量的開銷[8]。然而,在實際編程的過程中,不可避免地要發送多個數據,并且這多個數據的基本類型可能相同,也可能不同。在這種情況下,應該盡可能地將多個單獨的數據項打包成一個單獨的信息項,從而在保證不減少消息量的 前提下,減少了通信次數。具體應用中可以考慮使用派生數據類型或者 MPI_PACK/MPI_UNPACK等方法將數據打包,從而降低通信過程中的開銷。
3)考慮通過建立新的進程組和通信域來避免無效通信。進程組是通信域的組成部分,MPI的通信是在通信域的控制和維護下進行的,因此所有的MPI通信都用到通信域這一參數。由于MPI預定義組內通信域是MPI_COMM_WORLD,它包括所有的進程。而程序中經常會遇到部分進程需要通信的問題,無論選擇點對點通信還是簡單地使用集群通信都難以得到較好的性能。為了解決這一問題,可以通過對通信域的重組,以非常簡單的方式方便地實現通信任務的劃分,從而提高通信效率[9]。
4)選取適當的通信方式,充分發掘程序中通信與計算重疊的可能性。MPI中每種阻塞通信函數都有與其對應的非阻塞通信函數。程序中由于通信經常需要較長的時間,在阻塞通信結束之前,處理器只能等待,這樣就浪費了處理器的計算資源。對于非阻塞通信,不必等到通信操作完成便可以返回,這樣處理器可以同時進行計算操作,實現了計算與通信的重疊,大大地提高了程序執行的效率[10]。然而,要合理地選擇通信方式需要開發人員對程序中計算與通信重疊的可能性進行詳細的分析,由于DNS算法中計算與通信重疊的可能性不大,因此在對以上程序優化的過程中并未使用該優化方法。
6 結語
本文討論了MPI并行程序的性能優化問題,尤其是其中的通信優化問題,并通過具體的實驗為MPI程序開發人員提出了優化MPI并行程序的一般思路與方法。本文設計的并行程序有很好的加速效果,適合于大規模科學與工程計算。未來的工作:對虛擬進程拓撲進行深入的研究,以簡化并行程序設計,提高程序效率;對 MPI通信函數的源碼進行分析與研究,設計效率更高的通信函數,尤其是集群通信函數;通過對MPI中的動態進程管理作深入的研究,分析如何通過有效地利用動態進程管理以提高MPI并行程序的效率。
[1]Ghanbari M.The Cross-search Algorithm for Motion Estimation[J].IEEE Trans.Commun.1990.38:950-953.
[2]羅省賢,李錄明.基于MPI的并行計算集群通信及應用[J].計算機應用,2003,23(6):51-53.
[3]羅省賢,何大可.基于MPI的網絡并行計算環境及應用[M].成都:西南交通大學出版社,2001:35-44.
[4]陳國良.并行計算——結構·算法·編程[M].北京:高等教育出版社,1999:285-290.
[5]陳國良,吳俊敏,章鋒等.并行計算機體系結構[M].北京:高等教育出版社,2002:125--146.
[6]任波,王乘.MPI集群通信性能分析[J].計算機工程,2004,30(11):71-73.
[7]蔣英,雷永梅.MPI中的3種數據打包發送方式及其性能分析[J].計算機工程,2002,28(8):261-263.
[8]都志輝.高性能計算并行編程技術[M].北京:清華大學出版社,2001:178-187.
[9]雒戰平,劉之行.有限元并行計算的MPI程序設計[J].西安交通大學學報,2004,38(8):873-876.
[10]楊愛民,劉韌.集群系統中基于MPI的并行GMRES(m)計算通信的研究及應用[J].微電子學與計算機,2009,26(9):129-131.
猜你喜歡
中國外匯(2019年20期)2019-11-25 09:54:58
人大建設(2019年12期)2019-05-21 02:55:44
中山大學法律評論(2018年1期)2018-03-30 01:21:00
瞭望東方周刊(2017年42期)2017-12-05 18:49:38
環球時報(2017-03-30)2017-03-30 06:44:45
中國衛生(2015年3期)2015-11-19 02:53:32
政治與法律(2014年11期)2014-03-01 02:20:40
教育與職業(2014年7期)2014-01-21 02:35:04
計算機與網絡(2013年1期)2013-06-05 05:31:50
中華女子學院學報(2012年6期)2012-03-25 13:52:27
