粗糙集在洪水風險評估中的應用
2012-09-27 03:42:34劉孫俊
成都信息工程大學學報 2012年1期
張 進, 李 超, 劉孫俊
(成都信息工程學院計算機學院,四川成都 610225)
0 引言
隨著計算機和網絡的飛速發展,信息技術的不斷發展和普及,人類積累的數據量以指數級的方式增長,并且在網絡上還存在著各種豐富的數據資源。不過與數據量的增長迅速形成了鮮明的對比,人類分析數據的能力和從數據中提取知識的能力卻與之存在著相當大的差距,大量的數據被收集在大型數據庫中常年不被訪問,造成了”數據墳墓”。因此如何有效、科學、合理、正確地應用這些數據擺在了科學家的面前,知識挖掘技術就在這個時候產生了。但是對大量數據分析和挖掘時遇到了很大的問題,大量的數據具有不完全、模糊、冗余的特性,只有很少一部分能夠滿足數據挖掘算法的要求,因此需要對數據進行預處理,并且需要去除其中無意義的成分,粗糙集理論由此誕生了。
粗糙集理論是由波蘭杰出的數學家Z.Pawlak在1982年提出來的一種數據分析理論,剛開始時主要集中在東歐國家,當時并沒有引起國際計算機界和數學界的重視,直到1990年左右該理論在數據的知識發現,模式識別,決策與分析中的成功應用才引起了各國學者的廣泛關注。1991年Z.Pawlak的專著《粗糙集一關于數據推理的理論》的問世,標志著粗糙集理論及其應用的研究進入活躍時期[1-2]。
粗糙集理論是一種刻畫不完整性和不精確性的數學工具,能夠有效地分析和處理不完備性數據,通過發現其中的隱藏關系,從而提取出有效數據揭示其規律,簡化信息處理。屬性約簡算法是粗糙集理論的核心內容之一。
中國是一個自然災害頻繁的國家,而洪水災害則是對整個社會經濟發展影響最大的自然災害之一。僅僅依靠工程防洪根本無法抵御洪水的侵襲,所以在建立完善的防洪工程體系的基礎上通過災情評估,防洪調度等非工程措施對于實現防洪減災的正規化和現代化具有非常重要的意義。洪水災害風險評估是一項復雜的系統工程,涉及到社會,經濟等諸多方面,選擇洪水災害評估指標是進行洪水災害評估的前提和關鍵。此前的洪水風險評估一般都是集中在評估算法的優化,而用于評估的指標都是由專家根據經驗和知識總結出來的,為了評估的準確性可能一些并沒有意義或者對洪水風險評估不起作用的指標也被加入指標體系,從而導致參照的指標多達上百個,嚴重影響了評估算法的精確度和收斂速度。
通過對粗糙集中屬性約簡算法的研究,首次提出對用于洪水風險評估的指標進行約簡,剔除無意義的指標,然后利用約簡后的屬性進行風險評估,不僅降低了專家在對指標進行打分時的模糊性,并且提高風險評估的準確性和效率[3-4]。
1 粗糙集的基本概念
粗糙集理論是處理不精確和不完備問題的數學工具,主要思想是在保持分類能力不變的前提下通過約簡導出問題的分類規則。
1.1 論域等價關系和不可分辨關系
定義1 設非空集U是我們感興趣的對象組成的非空有限集合,稱為論域。
定義2 設R施U上的一個等價關系,U/R表示R的所有等價類構成的集合。
定義3 給定一個論域U和U上的一簇等價關系,若P?S且P≠?,則∩P仍是論域U上的一個等價關系,稱為P上的不可分辨關系,記為 IND(P)。
顯然不可區分關系是一個等價關系,U/IND(P)表示不可區分關系 IND(P)在論域U上形成的一個區分,稱為U的一個知識,可以簡記為 U/P。
1.2 屬性約簡
屬性約簡是粗糙集理論的核心內容之一,所謂屬性約簡就是在保持知識庫分類能力不變的前提下刪除其中不相關或不重要的屬性。
定義4 給定一個知識庫K=(U,S)和知識庫中的一個等價關系簇P?S,∨P∈P若IND(P)=IND(P-{R})成立,則稱知識 R為P中不必要的,否則稱R為P中必要的。其中必要的條件屬性組成的集合稱為核。
定義5 給定一個知識庫K=(U,S)和知識庫中的一簇等價關系P?S,對任意的G?P,若G滿足以下兩條:
(1)G是獨立的;
(2)IND(G)=IND(P);
則稱G是P的一個約簡,記為G∈RED(P)。其中RED(P)表示P的全體約簡組成的集合。
顯然,知識的任何一個約簡與知識本身對數據庫中的任意一個范疇的表達都是等同的,即它們對論域的分類能力相同。一般而言,知識約簡不唯一,可以有多種約簡。
粗糙集理論對給定的對象集合由若干個屬性描述,對象按照屬性的取值情況分成若干個等價類,統一等價類中的對象不可區分[5]。
1.3 基于區分矩陣的屬性約簡算法
定義8 對于決策表 T=(U,A,V,F),A=C∪D,C∩D=?,C為條件屬性集,D為決策屬性集,可以用類似的方法計算其相對約簡和相對核。
定義9 令S=(U,A,V,F)是一個只是表達系統,|U|=n,決策表S的區分矩陣是一個n*n矩陣。
基于區分矩陣的約簡算法的基本過程一般如下:
(1)基于決策表生成區分矩陣;
(2)從區分矩陣中找到屬性組合數為1的屬性,即為核屬性;
(3)從區分矩陣中找到不包含核屬性的條件屬性組合;
(4)將這些條件屬性組合轉化成合取范式的形式,并且利用吸收率進行約簡;
(5)根據要求選擇合適的約簡。
1.4 屬性約簡算法的改進
因為當決策表條件屬性很多時,基于區分矩陣的屬性約簡算法邏輯轉換運算代價太大,計算復雜度很大,所以本過程利用任何一個相對約簡都包含核屬性這一特性對基于屬性依賴度的約簡算法進行改進,將大大降低計算的復雜度[6]。
根據區分矩陣中屬性的特點,可以得知,區分矩陣中某個屬性出現的頻率越大和它所在的項越短,則該屬性的潛在區分能力就會越大,該屬性就會越重要
因此可以得到屬性的重要性函數:

其中k為項長,指屬性a是否出現在該項中,如果出現則值為1,否則值為0。該函數能夠很好的體現屬性的重要性,因此把其作為啟發函數。
由區分矩陣可以得知,區分矩陣中的每一項與系統的約簡都不為空,因為如果為空就說明該約簡對該兩個對象不可區分。可以根據區分矩陣中屬性長度為1的作為核元素,在區分矩陣中凡是含有約簡中屬性的項都可以用約簡代替。因此可以將這些項直接置空,從而得到過濾矩陣。
綜上得到約簡算法的步驟:
(1)根據構造的區分矩陣得到核元素,既項長為1的就是核元素;
(2)利用核元素對約簡進行初始化,然后用約簡和區分矩陣中的每一項進行與運算,將結果不為空的項刪除,從而得到過濾矩陣;
(3)利用上述的啟發函數對約簡以外的屬性計算重要性,將屬性重要性最大的屬性加入到約簡中;
(4)計算約簡與區分矩陣中每一項的交集,如果為空則結束,否則轉到(3);
(5)返回約簡。
2 應用粗糙集理論的洪水風險評估介紹
首先應該選定進行洪水風險評估的特定地區,這里選定武漢市作為洪水風險評估的區域。
2.1 洪水風險評估的指標集的選取
通過詢問專家和實地調查得到可能影響該地洪水風險的因子包括:地形,植被,土壤含水量,降雨,水庫分布,人口密度,耕地面積,人均收入水平,水利設施建設,防災意識,河網密度,年齡結構,健康狀況,教育程度,基礎設施密度,生產總值等。
2.2 根據當地歷年的指標值和結果值構造決策表
通過查詢1991~2005年《中國城市統計年鑒》中武漢市當時相關統計數據和中國氣象科學數據共享服務網中暴雨洪澇災害數據集、中國地面國際交換站氣候標準值年值數據集、中國農作物生長發育和農田土壤濕度旬值數據集得到武漢市對應各屬性的數值。
表1是通過對上述查詢數據進行一致性處理:即根據一定的標準劃分等級,這里采用中華人民共和國水利部于1994年6月2日發布的防洪標準(GB50201-94),其中決策屬性劃分為特大洪水,大洪水,小洪水,無4個等級;而條件屬性則根據防洪標準劃分為4個等級,然后再根據等級數據構造洪水信息決策表。

表1 歷年洪水信息決策表
2.3 根據決策表構造對應的區分矩陣
根據區分矩陣的定義,可以知道區分矩陣具有如下性質:首先,區分矩陣是一個對稱矩陣,因此只需要計算上三角矩陣或者下三角矩陣就可以了。其次可以根據定義得知區分矩陣的元素內容是由區分兩個對象的屬性構成的:當兩個對象的條件屬性和決策屬性完全相同時,則它們所對應的區分矩陣的元素為0;當兩個對象可以通過條件屬性取值不同加以區分時,則它們所對應的區分矩陣元素取值為這兩個對象不同的條件屬性集合;當這兩個對象的所有條件屬性取值相同而決策屬性取值不同時,則對應的區分矩陣中的元素取值為空。
表2是根據歷年洪水信息決策表構建的區分矩陣,由于區分矩陣是對稱矩陣,所以這里只計算了下三角矩陣。
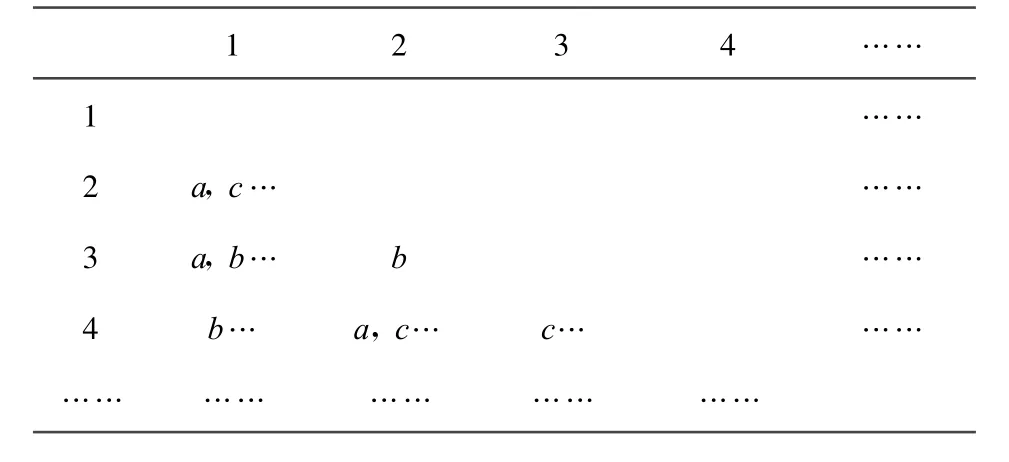
表2 區分矩陣
2.4 根據區分矩陣得到核屬性
從區分矩陣中找到屬性組合數為1的條件屬性,則這些條件屬性的組合即為核屬性,得到的核屬性是降雨,將核屬性加入到約簡集中。
2.5 將約簡集和區分矩陣中的每一項進行與操作,從而得到約簡矩陣
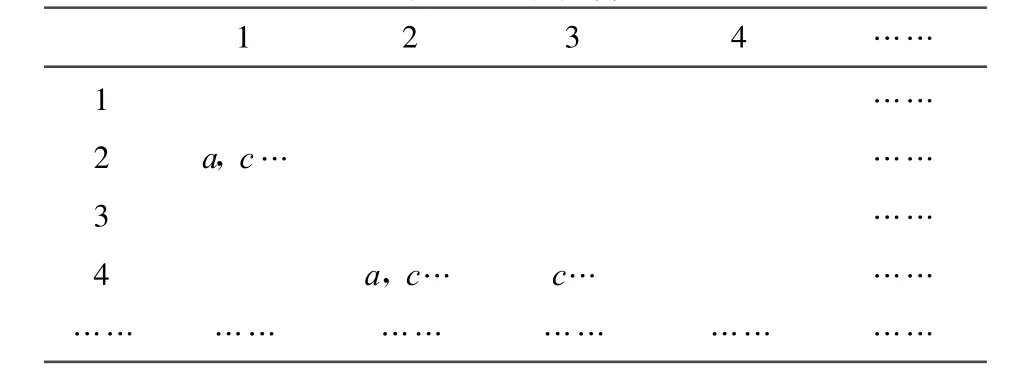
表3 過濾矩陣
表3就是用約簡集和區分矩陣中的每一項進行與操作后得到的過濾矩陣,然后根據過濾矩陣計算矩陣中所有屬性的重要性:
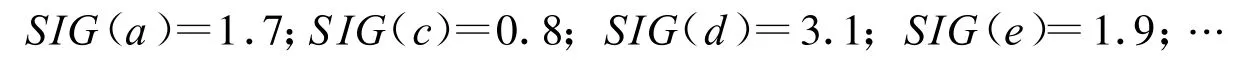
由以上計算可知,在過濾矩陣中重要性最大的是d(國民生產總值),因此將d加入到約簡集中,然后再次用約簡集與過濾矩陣相交,得到新的過濾矩陣,再按屬性的重要度依次將屬性加入到約簡集中,直到約簡集與過濾矩陣的相交為空,返回約簡集。
得到的相對約簡包括的條件屬性:降雨,國民生產總值,植被覆蓋率,人口密度,財產密度,基礎設施密度,中小企業密度,防洪設施建設。
2.6 將條件屬性約簡作為指標集,構建層次的洪水風險評估指標體系
由于在此應用的是粗糙集的基于區分矩陣的約簡算法,能夠得到所有約簡,因此這里還需要專家根據經驗選擇合適的約簡作為指標集構建風險評估指標體系。用約簡的結果和以前一些用于洪水評估的指標進行對比,不難發現條件屬性中土壤含水量,地勢,國民受教育程度等因素都沒有被用于構建評價指標體系。因為根據武漢市的歷史資料發現這些因素對武漢市的洪水災情并沒有起到作用,因此在這里對這些因素進行了刪除,以免影響后面進行的風險評估。
圖1是武漢市的洪水風險評估的指標體系,分為3層結構:第一層是該地區的洪水風險等級;第二層是因素集;第三層是子因素集。
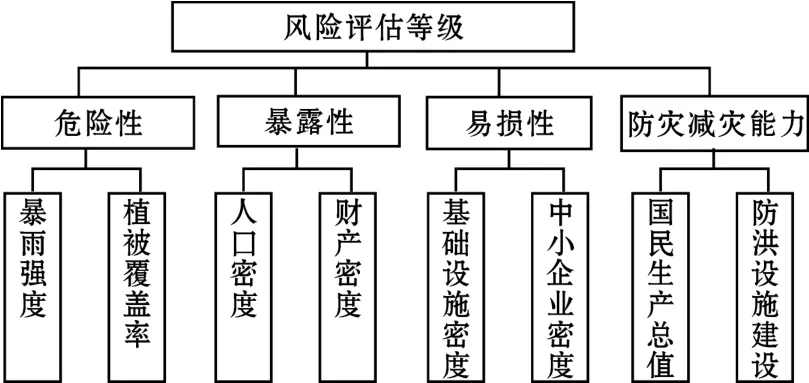
圖1 洪水風險評估的指標體系
2.7 運用模糊層次分析法在構建的評估指標的基礎上對該地區的洪水風險進行評估
根據模糊層次分析法所建立的數學評估模型如下:
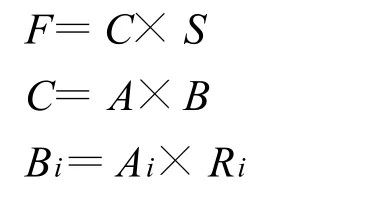
其中F為系統總得分,C為系統評估矩陣;S為專家評定的洪水風險的安全等級加權值;A為指標體系第二層的因素權重分配集;B為由Bi組成的總評估矩陣;Ai為第三層子因素的權重分配集;Ri各因素對應的評估矩陣,是由專家根據評語集即表4投票得出的[7-8]。

表4 洪水風險等級加權值

表5 洪水風險等級
應用模糊層次分析法進行洪水風險評估介紹:
(1)要采用層次分析法確定武漢市洪水評估指標因素的權重值:洪水風險評估指標體系遞減層次結構的構成確定了上下級之間的關系,可對每一層次各個因素相對于上一層某一準則的重要性進行兩兩比對,從而構造出判斷矩陣。其中表6是因素層中各因素對于系統的權重所建立的判斷矩陣,求得的權重集是(0.45,0.27,0.10,0.18)。類似還需要求出子因素層中各子因素對于因素層中對應因素的權重判斷矩陣,并且求出權重集。

表6 判斷矩陣
(2)求得武漢市洪水風險的總得分:利用表4根據所建立的模糊層次評估模型計算得到的武漢市的風險評估得分為51。
(3)確定武漢市洪水風險等級:根據表5,武漢市的風險的風險評估得分為51屬于45-59范疇,因此風險等級為較差。
查看了武漢市2005年至今的洪水災害損失情況都是比較嚴重的,其中重大洪水兩次,排在了全國城市洪水損失的前列,可見評估得到的結果與武漢市的現實情況基本相符。因此在對武漢市的洪水風險進行評估時利用粗糙集約簡理論對用于評估的屬性集進行約簡,利用約簡后的屬性進行風險評估,最終的結果是可靠的。由此可見土壤,地勢等屬性對于武漢市的洪水風險評估是多余的,是可以剔除的,并不影響最終評估結果的準確性。
3 結束語
運用粗糙集理論的基于區分矩陣的改進的屬性約簡算法對洪水風險評估中的指標集進行了約簡,得到了在洪水風險評估中起作用的指標,剔除了無意義的指標,比傳統的專家投票等單純依靠經驗的方法具有科學依據和數據支持。由于指標數量減少更易于專家對各個指標進行打分,提高了區域洪水風險評估的準確性和效率。因為應用粗糙集的屬性約簡算法需要大量的樣本數據,當數據量不充足時可能會導致最終的結果出現偏差,所以在應用粗糙集的屬性約簡算法時應該保證樣本數據的正確性和充分性。
[1] 張文修,吳偉志,梁吉業,李德.粗糙集理論與方法[M].北京:機械工業出版社,2002.
[2] 殷杰,柴毅,郭茂耘.應用粗糙集提取柴油機故障數據特征[J].計算機工程與應用,2011,(29).
[3] 劉新立.區域水災風險評估的理論與實踐[D].北京:北京師范大學,2000.
[4] 王保生,江西旱澇災害風險評估與農業可持續發展[J].同濟大學學報(自然科學版),2005,(8):31-34.
[5] 梁蒙.基于粗糙集的屬性約簡算法研究[D].河南:河南大學,2011.
[6] 趙永安.基于粗糙集的屬性約簡算法研究[D].內蒙古:內蒙古大學,2008.
[7] 王為人.基于層次分析法的流域水資源配置權重測算[M].北京:中國林業出版社,1998.
