分布式存儲中數據分布策略的分析與研究
2012-09-25 09:17:34陳艷君
河北建筑工程學院學報 2012年3期
龐 慧 陳艷君
(1.河北建筑工程學院,河北張家口075000;2.北京交通大學計算機與信息技術學院,北京100000)
0 論文所要解決的問題
分布式存儲系統,就是將數據分散存儲在多臺獨立的設備上.傳統的網絡存儲系統采用集中的存儲服務器存放所有數據,存儲服務器成為系統性能的瓶頸,也是可靠性和安全性的焦點,不能滿足大規模存儲應用的需要.分布式網絡存儲系統采用可擴展的系統結構,利用多臺存儲服務器分擔存儲負荷,利用位置服務器定位存儲信息,它不但提高了系統的可靠性、可用性和存取效率,還易于擴展.
如何才能最大限度地提高分布式存儲系統的容量、可靠性、安全性、數據分布、負載均衡性、可移植性,在數據存儲領域中已成為一個急需解決的迫切問題.本課題主要研究合理的分布式存儲管理系統的體系結構,分布式數據存儲的數據流向與數據負載均衡和系統優化等各方面的關鍵技術.所得結論使得分布式存儲系統更能適應網絡存儲數據的動態變化,可以更加合理地利用存儲設備的磁盤資源.有效地調度系統資源,使服務器的負載趨于平衡,使存儲設備的性能得到充分利用.
1 分布式存儲中數據分布策略的分析
1.1 分布式存儲架構模型:
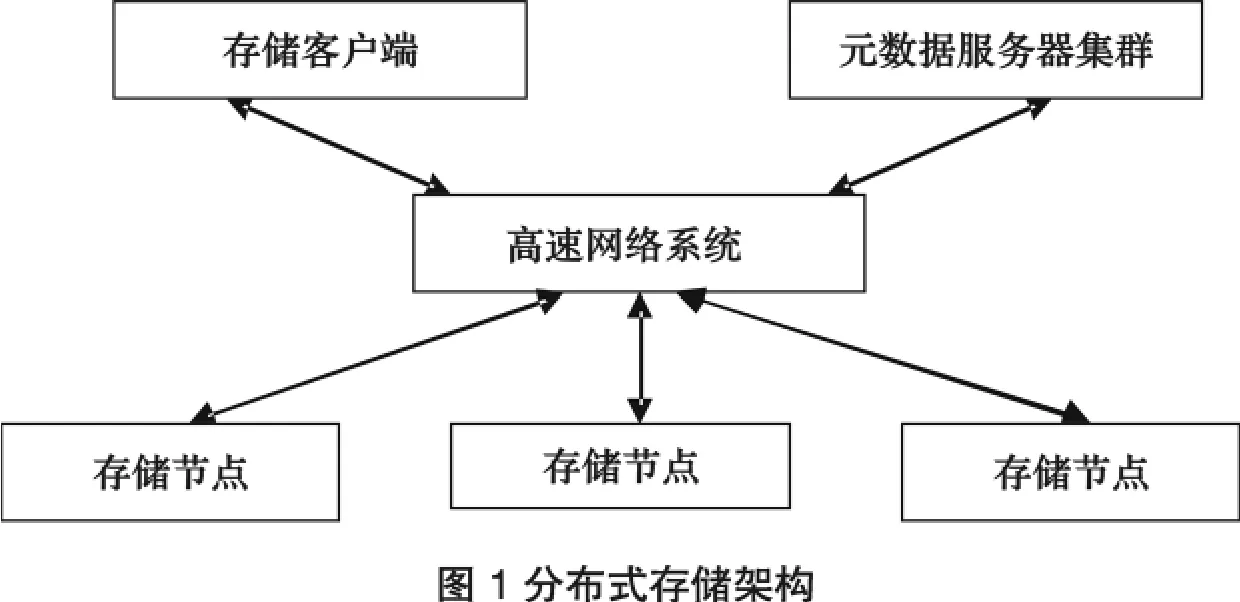
整個存儲架構可以分成三部分:存儲客戶端、元數據服務器集群以及存儲資源池.其中客戶端內嵌入用戶或者存儲應用系統內部,提供與元數據服務器以及存儲資源池通信的應用接口,完成客戶端與存儲系統之間的數據交互功能.由于原型系統對于存儲應用接口進行了封裝,元數據服務器集群以及存儲資源池的底層架構以及工作方式對抗上層客戶端是完全透明的,這使得用戶無需考慮底層復雜的結構特征,利用簡單的接口輕松使用存儲資源,開發數據服務應用.元數據服務器集群用來管理用戶數據的元數據信息,并且管理數據的存放位置以及冗余策略.元數據服務器對用戶提供文件IO,處理來自客戶端的文件級操作,并保存關鍵的元數據信息.存儲資源池由多個存儲節點構成,主要采用對象存儲技術和分布式的架構,完成客戶數據的保存,并提供數據的容錯,容災功能.
海量的網絡存儲系統必須支持在底層存儲池變動的情況下保持數據負載的均衡,數據尋址的高效.特別是隨著數據量不斷增加,網絡存儲系統面臨著不斷擴展的壓力,對系統的可擴展性提出了要求.所以,為了滿足這些技術需求,網絡存儲系統需要靈活高效的數據分布策略來確保性能.數據分配策略是在數據與存儲地址之間建立起高效映射關系的方法,換言之,是將數據合理的分配到存儲設備中,并最大限度地簡化尋址過程,同時確保存儲資源和網絡資源的合理分配.
1.2 分布式緩存的問題
假設我們有一個網站,最近發現隨著流量增加,服務器壓力越來越大,之前直接讀寫數據庫的方式不太合適了,于是我們想引入一種高性能的分布式內存對象緩存系統作為緩存機制.現在我們有兩臺機器可以作為服務器,如圖2所示.

很顯然,最簡單的策略是將每一次緩存請求隨機發送到一臺服務器,但是這種策略可能會帶來兩個問題:一是同一份數據可能被存在不同的機器上而造成數據冗余,二是有可能某數據已經被緩存但是訪問卻沒有命中,因為無法保證對相同key的所有訪問都被發送到相同的服務器.因此,隨機策略無論是時間效率還是空間效率都非常不好.
要解決上述問題只需做到如下一點:保證對相同key的訪問會被發送到相同的服務器.很多方法可以實現這一點,最常用的方法是計算哈希.例如對于每次訪問,可以按如下算法計算其哈希值:h=Hash(key)%2其中Hash是一個從字符串到正整數的哈希映射函數.這樣,如果我們將服務器分別編號為0、1,那么就可以根據上式和key計算出服務器編號h,然后去訪問.
這個方法雖然解決了上面提到的兩個問題,但是存在一些其它的問題.如果將上述方法抽象,可以認為通過:h=Hash(key)%N這個算式計算每個key的請求應該被發送到哪臺服務器,其中N為服務器的臺數,并且服務器按照0–(N-1)編號.
這個算法的問題在于容錯性和擴展性不好.所謂容錯性是指當系統中某一個或幾個服務器變得不可用時,整個系統是否可以正確高效運行;而擴展性是指當加入新的服務器后,整個系統是否可以正確高效運行.
現假設有一臺服務器壞了,那么為了填補空缺,要將壞的服務器從編號列表中移除,后面的服務器按順序前移一位并將其編號值減一,此時每個key就要按h=Hash(key)%(N-1)重新計算;同樣,如果新增了一臺服務器,雖然原有服務器編號不用改變,但是要按h=Hash(key)%(N+1)重新計算哈希值.因此系統中一旦有服務器變更,大量的key會被重定位到不同的服務器從而造成大量的緩存不命中.而這種情況在分布式系統中是非常糟糕的.
一個設計良好的分布式哈希方案應該具有良好的單調性,即服務節點的增減不會造成大量哈希重定位.
1.3 一種改進的哈希方案
如果將整個哈希值空間假想成一個虛擬的圓環,然后將各個服務器使用H進行一個哈希,具體可以選擇服務器的IP或主機名作為關鍵字進行哈希,這樣每臺機器就能確定其在哈希環上的位置,這里假設將上文中兩臺服務器使用IP地址哈希后在環空間的位置如圖3所示:
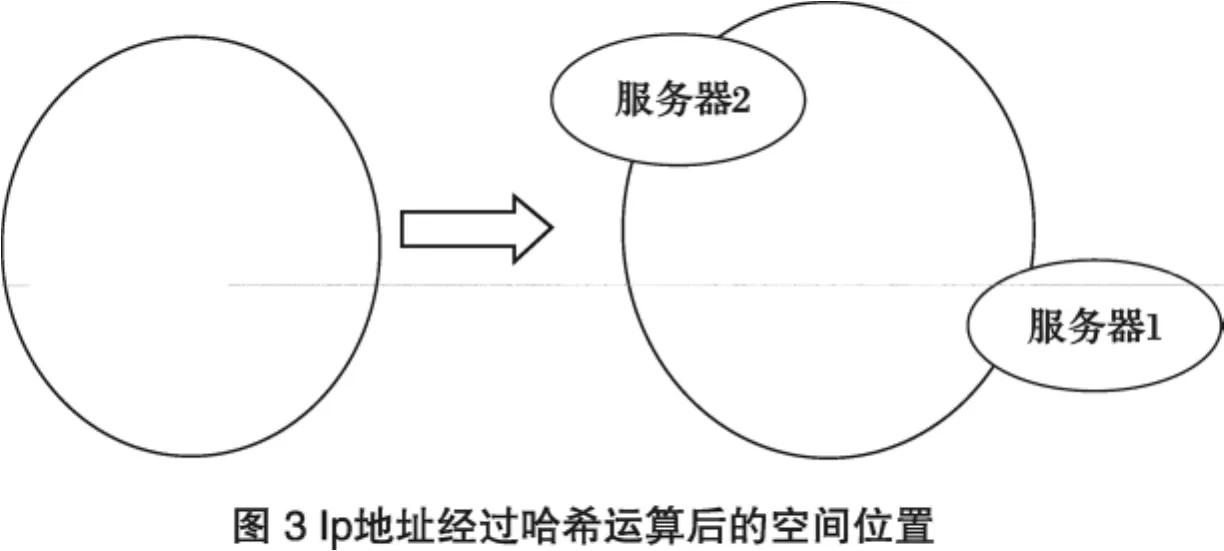
接下來使用如下算法定位數據訪問到相應服務器:將數據key使用相同的函數H計算出哈希值h,通根據h確定此數據在環上的位置,從此位置沿環順時針“行走”,第一臺遇到的服務器就是其應該定位到的服務器.
例如我們有a、b、c三個數據對象,經過哈希計算后,在環空間上的位置如圖4所示:
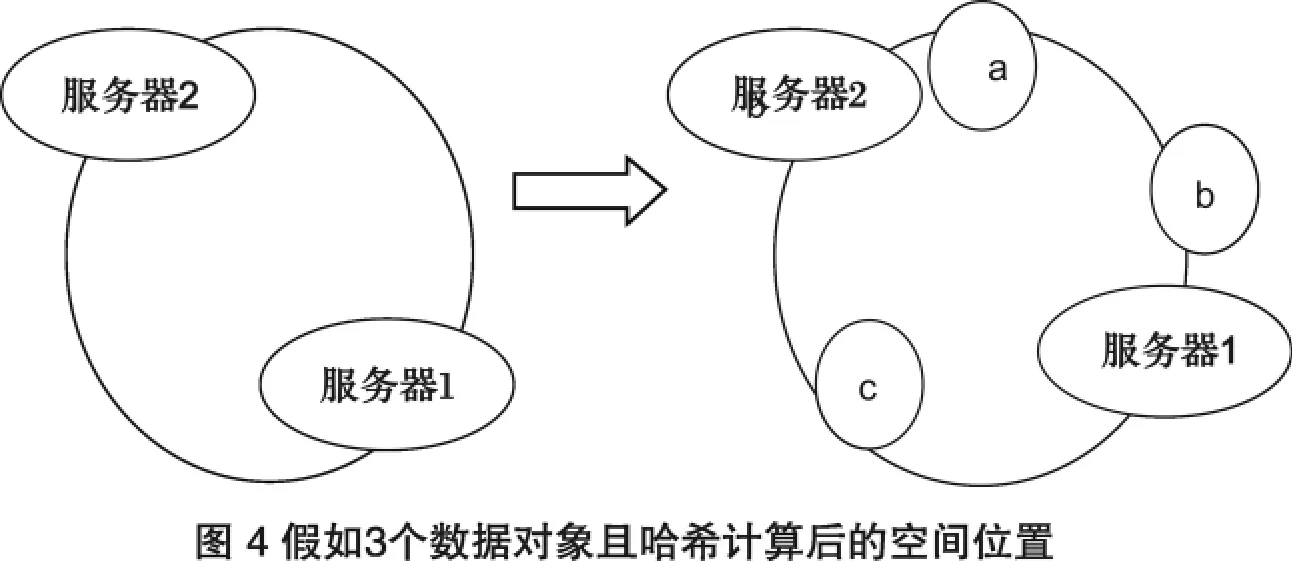
根據算法,數據a,b會被定為到服務器1上,c被定為到服務器2上.現假設服務器1壞了:
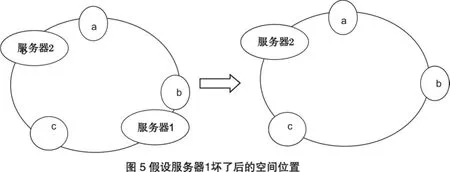
可以看到此時c不會受到影響,只有a,b節點被重定位到服務器2.一般的,在該算法中,如果一臺服務器不可用,則受影響的數據僅僅是此服務器到其環空間中前一臺服務器之間數據,其它不會受到影響.如果我們在系統中增加一臺服務器3:
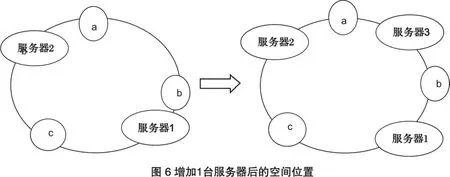
此時b,c不受影響,只有a需要重定位到新的服務器3.一般的,在一致性哈希算法中,如果增加一臺服務器,則受影響的數據僅僅是新服務器到其環空間中前一臺服務器之間數據,其它不會受到影響.
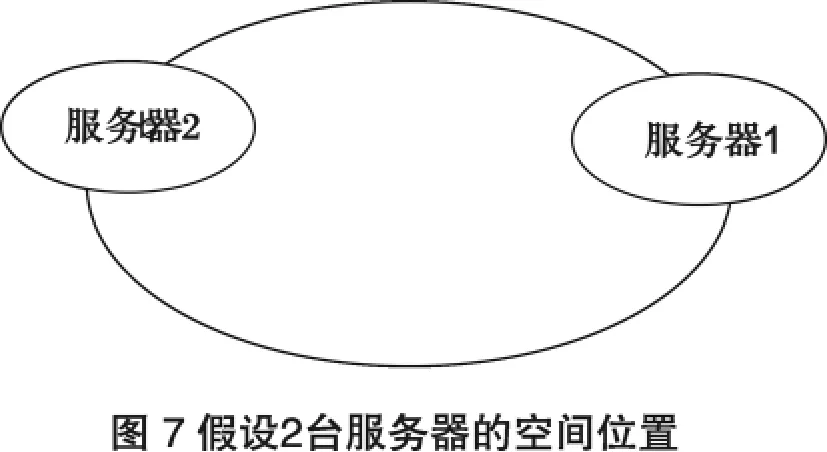
綜上所述,該算法對于節點的增減都只需重定位環空間中的一小部分數據,具有較好的容錯性和可擴展性.但是在服務器節點太少時,容易因為節點分部不均勻而造成數據傾斜問題.例如我們的系統中有兩臺服務器,其環分布如圖7所示:
此時必然造成大量數據集中到服務器2上,而只有極少量會定位到服務器1上.為了解決這種數據傾斜問題,上述算法引入了虛擬節點機制,即對每一個服務節點計算多個哈希,每個計算結果位置都放置一個此服務節點,稱為虛擬節點.具體做法可以在服務器IP或主機名的后面增加編號來實現.例如上面的情況,我們決定為每臺服務器計算三個虛擬節點,于是可以分別計算“服務器1.1”、“服務器1.2”、“服務器 1.3”、“服務器 2.1”、“服務器 2.2”、“服務器2.3”的哈希值,于是形成六個虛擬節點:
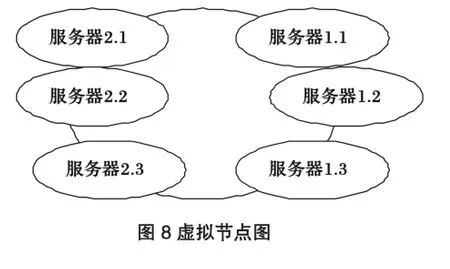
同時數據定位算法不變,只是多了一步虛擬節點到實際節點的映射,例如定位到“服務器1.1”、“服務器1.2”、“服務器1.3”三個虛擬節點的數據均定位到服務器1上.這樣就解決了服務節點少時數據傾斜的問題.在實際應用中,通常將虛擬節點數設置為32甚至更大,因此即使很少的服務節點也能做到相對均勻的數據分布.
1.4 基于節點容量感知的負載均衡策略
在大多數的存儲系統中,隨著系統存儲設備的更新升級,新加入的節點往往具有更高的帶寬,更大的存儲空間.而基本的一致性哈希算法所有節點默認為資源對等,地址分配的結果只是滿足統計學意義上的均勻分配.所以基本算法的使用環境默認為由同構存儲節點構成的存儲池,無法再存儲資源分配過程中體現存儲節點之間的性能差異.
所以,針對該問題,本文在虛擬節點分配方法的基礎上,提出了基于節點容量感知負載均衡策略,對分配方法進行優化,提高系統數據分布策略的靈活性,從而提高系統的整體性能.該優化方法的實現基于以下假設:存儲對象的哈希值成均勻分布,并且各個存儲地址段的存儲開銷呈均勻分布.優化的基本思想是對每個物理節點的資源進行估計量化,根據整個系統的節點資源情況,對物理節點分配的虛擬節點數進行調整,從而進一步優化物理節點間的負載均衡.對于每個物理節點分配調節因子w,該參數表示該物理節點的資源分配權值,可表示節點的容量或者帶寬等,原型系統設計中采用的是對容量資源的量化權值.然后,統計每個物理節點的所分配地址空間的大小s.基于前提假設,s值可以表示該節點所分配存儲開銷;設P=s/w,作為物理節點資源利用率量化值.系統通過統計計算,獲取P的均值,并設定門限值Pmax和Plow,當節點超過門限范圍時,采用增加或減少虛擬節點的方法,均衡整個系統負載.圖9為該策略具體的實現流程:
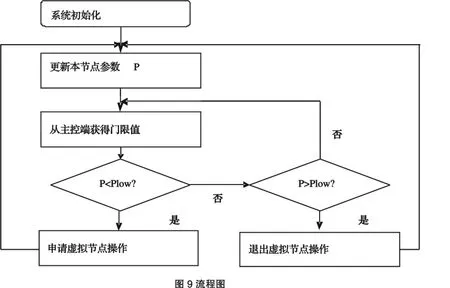
基于節點容量感知的分配策略采用分布式的方式完成,存儲資源節點通過主控端獲得相關門限值,并計算自身的相關參數,實時比較.當本節點的參數P值小于下限值Plow時,進行申請虛擬節點操作,請求信息被發送到控制端,調用函數完成操作;同理,當本節的參數P值大于上限值Phigh時,進行退出虛擬節點操作.此外,在主控端保存著節點的信息,很容易獲得理論均值.門限值的設定采用如下公式:
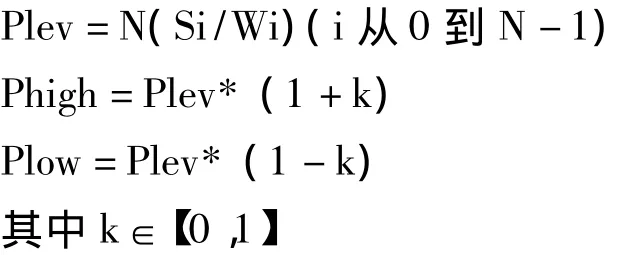
其中:Plev時P的均值;N為物理節點數;S為物理節點所有虛擬節點地址范圍之和;W為存儲資源標準化權值(例如采用50GB為單位,200GB的節點W值為4,100GB的節點W值為2.值得注意的是:當K過大時,會影響到負載平衡的效果;當K值過小時,會造成虛擬節點的頻繁增減操作,甚至造成某些物理節點的虛擬節點數出現“顫動”(頻繁來回增減虛擬節點),造成極大地系統開銷.此外,K值的極限值與物理節點的個數有一定關系,當物理節點數越多時,k值可以設得越小.
以上便是基于接點容量感知分配策略的實現方法,在前提假設成立的情況下,該方法為系統存儲資源的合理利用提供了更加靈活的機制,確保了系統存儲資源的負載均衡.
2 結論
本文對分布式存儲領域的技術展開了研究,介紹了一種分布式存儲的基本架構.該策略以一致性哈希數據分布策略為基礎,引入了虛擬化設計思路,采用虛擬節點的分配策略,并分析研究了一種基于節點容量感知的負載均衡方法,有效優化了系統的性能,提高了系統的可擴展性.但是上述負載均衡策略由于算法的缺陷帶來過大的負載轉移開銷,如:由于需要實時比較,主控端必須不停的獲取并計算理論均值,并調用函數進行比較,這就必將增加系統的負荷.
既然靜態負載均衡策略具有簡單易行的優點,動態負載均衡策略具有較好的時間和空間效率,而二者又都具有其弊端,故單獨使用某個策略并不能滿足所有網絡系統的需求.因此我們可以試著動靜結合,將這兩種策略互相配合使用,或許可以達到更好的效果.下面是一個新的算法設想:
在沒有節點加入或退出系統時,我們可以采用普通的靜態負載分配算法,在靜態負載分配算法中,利用特殊的ID生成算法可有效地為節點均衡分配負載;同時,當網絡發生動蕩時,即有節點加入或退出系統時,采用特殊的動態負載分配方法來對其進行調整,以最快的速度和最小的轉移開銷可保證系統負載重新均衡.設想中提出的策略雖有待改進和細化,但我相信在不久的將來必將出現與之相符的詳細實用的算法.
[1](美)特尼博姆等著,辛春生等譯.分布式系統原理與范型(第2版).清華大學出版社,2008,6
[2]肖迎元.分布式實時數據庫技術.科技出版社,2009,6
[3]陸嘉恒.分布式系統及云計算概論.清華大學出版社,2011,5
[4]李明.認識 Linux的磁盤配額.http://blog.chinaunix.net/u3/93755/showart-187
[5]Andrew S.Tanenbaum著,陳向群,馬洪兵譯.現代操作系統.北京機械工業出版社,2009,7
[6]韋理,周悅芝,夏楠。用于網絡存儲系統的存儲空間動態分配方法.計算機工程,2008(5)
[7]田穎.2003.分布式文件系統中的負載平衡技術研究[D]:[碩士學位論文]北京:中國科學院計算技術研究所
[8]楊德志,許魯,張建剛.2008.藍鯨分布式文件系統元數據服務[J].計算機工程:4~9
[9]肖培棕.2009.分布式文件系統元數據負載均衡技術研究與實現[D][碩士學位論文]合肥中國科學技術大學
[10]馮幼樂.2010.分布式文件系統元數據管理技術研究與實現[D]:[碩士學位論文].合肥:中國科學技術大學
猜你喜歡
工業設計(2022年8期)2022-09-09 07:43:20
教學考試(高考化學)(2021年2期)2021-05-30 06:15:52
軍民兩用技術與產品(2021年10期)2021-03-16 06:05:30
北京測繪(2020年12期)2020-12-29 01:33:58
中學生數理化·高一版(2020年3期)2020-04-21 08:03:20
中學生數理化(高中版.高考理化)(2020年2期)2020-04-21 05:32:50
裝備制造技術(2019年12期)2019-12-25 03:06:46
小學生作文(低年級適用)(2019年9期)2019-10-08 08:37:10
中國洗滌用品工業(2019年4期)2019-05-11 09:27:34
數學大世界(2018年1期)2018-04-12 05:39:14
