基于支持向量機集成算法的煤礦頂板狀態檢測
2012-08-15 02:01:46付家才張鐵山
網絡安全與數據管理 2012年17期
付家才,張鐵山,任 眾
(黑龍江科技學院,黑龍江 哈爾濱 150027)
我國是一個煤炭大國,煤炭資源豐富,且煤炭消費量逐年增加。為保證國民經濟的持續健康發展,需要有計劃地大規模開采煤炭資源。然而,我國在煤炭開采中的安全事故經常發生。其中,冒頂事故是最常見的安全事故之一,給國家和人民帶來了巨大的損失。而要避免和減少冒頂事故的發生,關鍵就是要對頂板的安全性能進行及時、有效地檢測,以便工程技術人員及時排除安全隱患。
敲幫問頂(wall tapping and roof sounding)是依靠人耳極其靈敏的聽覺系統和長期的實踐經驗來判斷頂板的安全穩定性的,是目前被廣泛沿用的對頂板進行安全檢測的重要途徑。但這種方法對工人自身技能要求較高,且對工人的人身安全有一定的安全隱患。因此,研究新的檢測技術就顯得非常迫切。其中,基于模式識別的檢測是目前研究的重要方向之一。在應用現代模式識別技術對頂板進行狀態監測和故障診斷中,功率特征提取和分類器模型設計是兩個至關重要的因素。本文采用基于聽覺模型和支持向量機集成算法。基于聽覺模型的聲信號特征提取、分類、識別的研究,近年來得到了國內外學者的高度重視,特別在語音信號處理方面。但是針對煤礦頂板敲擊聲音信號方面重視較少。支持向量機SVM(Support Vector Machines)是Vapnik等人根據統計學習理論中結構風險最小化原則提出的。而支持向量機集成SVME(Support Vector Machine Ensemble)可以提高支持向量機的分類性能[1-2]。
本文正是基于以上原因,針對小樣本、多類煤礦頂板,提出了基于支持向量機集成算法對煤礦頂板安全性能進行檢測的方法。
1 人耳聽覺功率譜特征提取
人們通過對生理聲學、心理聲學和信號處理的研究和分析[3-4],建立了人耳聽覺模型,并且利用此模型來對聲音信號進行聽覺譜特征提取。該聽覺譜特征[5]提取過程如圖1所示。
通過對模仿人的聽覺感知機理進行分析,聽覺譜特征提取算法主要有三個方面的處理:(1)臨界頻帶段分析處理;(2)等響度級預處理;(3)等響度轉換。利用臨界頻帶分析,計算模型考慮了耳蝸的分頻特性,由此可以反映人耳的掩蔽效應。
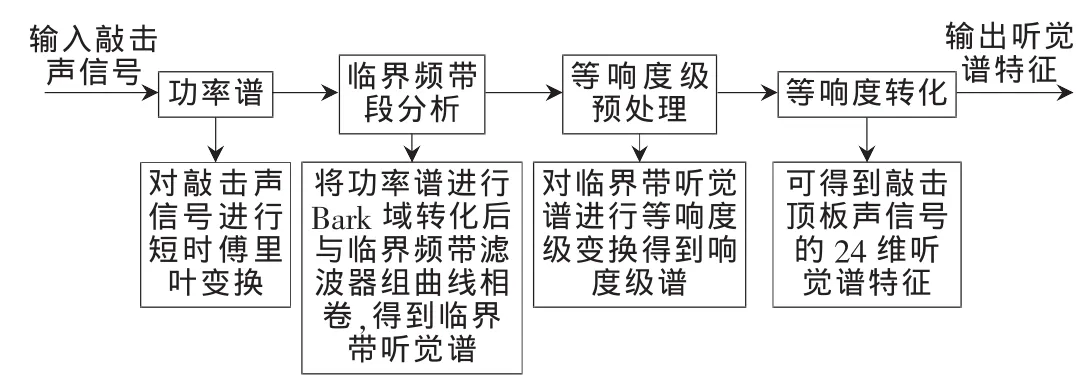
圖1 聽覺譜特征提取原理
2 支持向量機集成算法
頂板狀態模型為利用已知類別的頂板狀態樣本建立支持向量機分類器模型。首先給定n個獨立樣本,每個樣本xi有d個特征,樣本x分別屬于m類頂板狀態。
X={(xi,yi)}|{xi∈Rd,yi∈{1,2,…,m},i=1,2,…,n}
通過對給定的樣本集進行訓練得到一個分類器,利用此分類器對測試樣本集進行分類的算法稱為機器學習算法。
為了提高支持向量機的分類性能和分類精度,可以把多個分類器集成起來。針對小樣本、多類頂板狀態診斷問題,本文提出的支持向量機集成(SVME)算法,結合了敲擊聲音信號的人耳聽覺譜特征,對頂板狀態進行診斷。
SVME算法流程如圖2所示。

圖2 支持向量機集成(SVME)算法流程
如圖2所示,對于SVME算法而言,首先應給定訓練樣本集X和訓練樣本的初始加權系數w1(i)=,i=1,2,…,n;然后,進行一個循環函數以訓練 T個個體SVMC。
在循環體中,首先從給出的訓練樣本集X中按照一定的概率抽取樣本并獲得新的訓練樣本Xt;然后,依據新獲得的訓練樣本Xt來優化選擇個體SVMC核函數參數,并訓練 SVM以獲得分類超平面 ft(Xt);再次,計算出該分類超平面的加權分類錯誤率;最后,做出一個判斷:即判斷計算出的加權分類錯誤率是否≥0.5或=1。如果條件成立,則結束該循環,并運用加權多數投票法集成個體SVMC;反之,則改變加權系數,進行下一輪循環,直至條件成立,退出循環。
要想獲得一個高性能和高精度的支持向量機集成模型,就必需要對優化不敏感損失函數ε、懲罰系數c和核參數γ等參數進行優化處理,而這些參數之間相互影響。實際上,選擇過程是一個優化搜索的過程,由于深度優先算法具有全局搜索性能力強、并行性和啟發式等優點,所以本文采用深度優先算法對SVMC參數進行尋優。深度優先算法[6]是一種基于圖論的優化算法,其基本思想:為了求得問題的解,先選擇某一種可能情況向前(子結點)探索,在探索過程中,一旦發現原來的選擇不符合要求,則回溯至父親結點重新選擇另一結點,繼續向前探索。如此反復進行,直至求得最優解。深度優先搜索的實現方式可以采用遞歸或者棧來實現。
采用深度優先搜索對SVMC參數c、γ和ε進行優化的具體步驟如下:
(1)對SVMC中的參數 c、γ和ε進行初始范圍的確定,按照步長對參數c、γ和ε進行等量劃分,以此獲得離散數組。
(2)首先利用LIBSVM軟件采用交叉驗證方法對參數c、γ和ε進行建立模型和預測;然后對每組均方根誤差進行比較;最后選擇最小的均方根誤差所對應的參數為本次的SVMC最佳參數組合。
(3)將本次最優參數和上一次最優參數的均方根誤差進行比較,如果均方根誤差小于上一次均方根誤差,則跳轉到步驟(4),否則跳轉到步驟(5)。
(4)根據上一次的最優參數,并且采用啟發式方式在該參數附近進行參數范圍修改,從而加快參數搜索速度;然后跳轉到步驟(1),重新進行遞歸運算。
(5)參數優化結束后,退出運算,取此時的參數 c、γ和ε為SVMC的最優參數。
深度優先搜索參數優化流程圖如圖3所示。
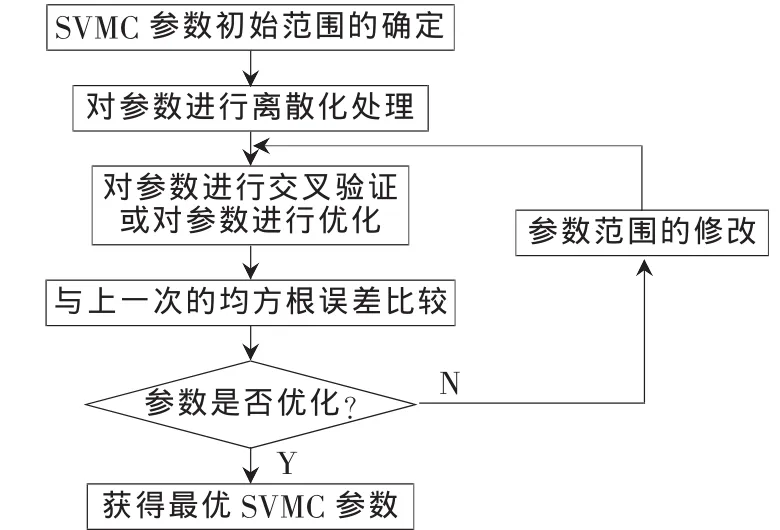
圖3 深度優先搜索參數優化流程
3 實驗及結果
3.1 實驗數據集
本文實驗數據是從我國東北某大型煤礦井下頂板上采集的,共有4類目標:一類是安全頂板,另3類是3種危險頂板 (浮石、剝層和斷裂)。信號的采樣頻率是20 000 Hz,每個樣本長度為4 096個點。安全頂板、浮石頂板、剝層頂板和斷裂頂板的樣本數目分別為2 000、200、500、150。 由于受到實驗數據采樣頻率(20 000 Hz)的限制,本文只在20~10 000 Hz頻率范圍內 (即前 22個臨界頻帶內)提取了4類頂板的敲擊聲信號的聽覺譜特征。
3.2 實驗
在分類實驗中,訓練樣本數目和測試樣本數目的比值是1﹕4,提取樣本的聽覺譜特征后,分別用SVME算法和單個SVMC對4類目標進行頂板狀態診斷實驗。為了避免樣本選取的隨機性對實驗結果帶來的誤差,實驗分別進行了20次,最終結果為20次實驗結果的平均值。檢測結果如表1所示。
從表1可以看出,支持向量機集成算法可以有效識別安全頂板和危險頂板,并進行狀態診斷,而且其識別4類目標的正確識別率都比單個SVMC要高。特別是本文所提出的算法對危險頂板的正確識別率比單個SVMC提高了2.57%~3.22%。實驗結果證明,本文提出的支持向量機集成(SVME)算法是有效的,可以應用于煤礦頂板狀態識別和故障診斷中。

表1 四類頂板檢測結果
本文提出了支持向量機集成(SVME)算法,采用了深度優先搜索對支持向量機集成參數進行優化,并結合敲擊聲信號的人耳聽覺譜特征用于頂板狀態的分類識別。實驗證明,本文所提出的SVME算法識別率較高,可以滿足現場檢測的要求,為煤礦頂板狀態診斷提供了新的方法。
[1]VAPNIK V.The nature of statistical learning theory[M].New York: Springer-Verlag, 1999.
[2]楊宏暉,孫進才.基于支持向量機集成的水下目標自動識別系統[J].測控技術, 2006, 25(12).
[3]ZWICKER E,FASTL H.Psychoacoustics facts and models[M].NewYork: Springer-Verlag,1999.
[4]HERMANSK H.Perceptual linear predictive(PLP)analysisof speech[J].Journal of the Acoustical Society ofAmeri-ca,1990, 87(4): 1738-1751.
[5]楊宏暉,侯宏,曾向陽.基于聲信號人耳聽覺譜特征的風機故障診斷[J].儀器儀表學報,2009,30(1).
[6]李立紅,許元飛.深度優先搜索的支持向量機參數優化算法[J].計算機仿真,2011,28(7):216-219.
猜你喜歡
房地產導刊(2022年5期)2022-06-01 06:20:14
建材發展導向(2021年12期)2021-07-22 08:06:48
建材發展導向(2021年7期)2021-07-16 07:07:52
數學小靈通(1-2年級)(2021年4期)2021-06-09 06:25:56
中學生數理化(高中版.高二數學)(2021年12期)2021-04-26 07:43:48
電子制作(2019年15期)2019-08-27 01:12:00
中學生數理化·七年級數學人教版(2019年4期)2019-05-20 10:06:32
中學生數理化·七年級數學人教版(2018年6期)2018-06-26 08:36:06
初中生世界·七年級(2017年9期)2017-10-13 22:27:46
中國生物醫學工程學報(2017年6期)2017-02-10 05:11:45
