基于混合聚類的層次教學模式分組實踐
2012-08-09 09:25:10張鐵軍賈銀江趙峻穎
東北農業大學學報(社會科學版) 2012年6期
張鐵軍 賈銀江 趙峻穎
(東北農業大學,黑龍江哈爾濱 150030)
本文采用混合聚類算法對學生進行分類分班,從而為分層次教學的實施提供保證和支持。
一、混合聚類分析方法
聚類是一種常見的數據分析工具,它的基本思想是根據對象間的相似程度進行類別的聚合。當前的聚類算法大多用于處理單種屬性的數據,如數值型屬性數據的處理,或者符號型屬性數據的處理。傳統的基于歐氏距離劃分的算法難以滿足此類混合屬性數據集聚類的要求。
由于在分層次教學分組過程中,采用的數據不僅是考試成績等數值型數據,還包括學生掌握計算機技能水平的差異等分類型屬性數據,所以選用K-prototypes混合聚類分析的方法。該法提出利用分類屬性簡單匹配相異度,將分類屬性轉化為數值屬性間基于距離的計算問題,從而解決混合屬性數據集聚類的問題。
K-prototypes算法定義了一個代價函數。對于含有m個屬性(mr個數值屬性,mc個分類屬性,且m=mr+mc)的n個數據對象,代價函數定義為:
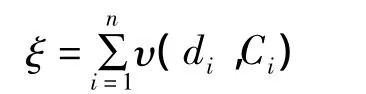
其中υ(di,Ci)是數據對象di到最近的聚類中心Ci的距離。υ(di,Ci)定義如下:
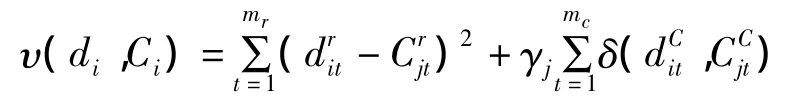
對混合屬性數據集聚類的過程就是求解代價函數ξ最小化的過程。
二、基于混合聚類分析的教學分組應用
1.數據收集
教學分組的數據收集是大學一年級學生在第一學期期末,在教務網站輸入自己的學號進行期末考試成績查詢時,以二值按鈕的方式讓學生對自己的計算機技能做真實評估。評估結果直接存儲到數據庫中作為教學分組的分類屬性數據,同時學生的《計算機基礎一》第一學期的考試成績也對應著學號轉存到同一數據庫表中作為教學分組的數值型數據。
學生的計算機技能由于經過一學期的基礎學習,對計算機各個方面的知識都有了一定的了解,本評估表主要注重學生的興趣取向,并綜合學生的計算機技能水平。

表1 計算機技能評估表
對于每個學生的自我評估表,當某一學生掌握了某種技能時,將該技能對應的屬性值定為1,否則設為0,共有6種屬性,即生成6位的二進制編碼。如表2所示,是根據本校2010級大學計算機基礎課程預處理后得到的數據。
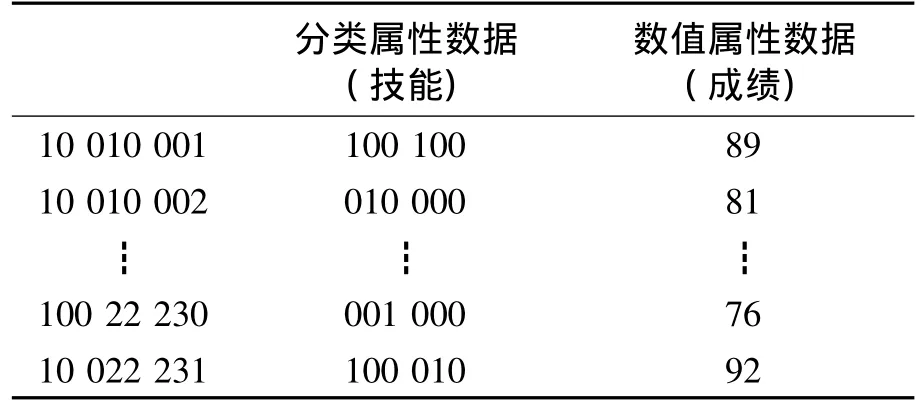
表2 2010級教學分組數據表
2.混合聚類分析實現
根據K-prototypes算法,用VC++6.0編程實現,實現步驟如下:
1)初始化聚類數目k和聚類中心C,即從數據集中隨機選取k個初始聚類原型;
2)按照定義的代價函數最小化公式,將數據集中的各個對象劃分到離它最近的聚類原型所代表的類中;
3)對于每個聚類,根據距離公式重新計算新的聚類原型;
4)計算每個數據對象對于新的數據原型的差異度,如果離一個數據對象最近的聚類原型不是當前數據對象所屬聚類原型,則重新分配這兩個聚類的對象;
5)重復 Step 3和Step 4,直到各個聚類中不再有數據對象發生變化時,算法結束。
3.聚類結果
對2010級大一學生進行聚類分組,設定權重=0.5,確定分為11類。在按類分班時,打亂原來的自然班,但在同類中還是以相同學科相同專業優先分班。通過對聚類結果進行分析比較,對于考試成績比較高,計算機技能掌握比較多的分組,他們對計算機知識有較大的學習興趣,并且有扎實的計算機基礎,這部分學生的培養可以在教學過程中針對他們所選擇的技能對教學內容進行擴充,以程序設計、數據處理、網絡應用為主,培養既懂專業又掌握計算機專業知識的復合型人才。對于考試成績較高,但掌握計算機技能較少的分組,主要采用啟發式教學方法,拓寬學生的視野,側重于提高與學生自己專業相關的計算機知識的學習興趣,為以后的工作科研做知識儲備。對于分組中學習成績中等及偏下的同學以加強基礎知識與動手實驗能力為主,運用多種教學手段提高學生的學習興趣,循序漸進地使學生能夠牢固掌握所學知識。
三、采用混合聚類方法對學生進行教學分組的實際意義
將K-prototypes聚類引入到分層次教學分組之中,把學生計算機技能的差異作為分類屬性,同時把計算基礎考試成績作為數值屬性,進行混合聚類分組,這樣既考慮到學生的學習能力,又兼顧了學生的學習興趣和取向,達到因材施教的教學要求。運用VC6.0++開發出基于混合聚類的教學分組計算機程序,該程序可以嵌入到教學管理系統當中,從而方便對學生的教學教務進行統一管理。
[1] 孫吉貴,劉杰,趙連宇.聚類算法研究[J].軟件學報,2008,16(1):48-61.
[2] Barbara D,Chen P.Using Self-similarity to Cluster Large Datasets[J].Data Mining and Knowledge Discovery,2003,7(2):123-152.
猜你喜歡
故事作文·高年級(2023年10期)2023-10-23 11:21:18
小學科學(學生版)(2021年7期)2021-07-28 06:44:42
甘肅教育(2020年14期)2020-09-11 07:57:50
科技傳播(2019年22期)2020-01-14 03:06:34
中國公路(2017年19期)2018-01-23 03:06:33
消費導刊(2017年20期)2018-01-03 06:26:40
東方教育(2017年19期)2017-12-05 15:14:48
學苑創造·A版(2017年6期)2017-06-23 14:10:46
唐山文學(2016年2期)2017-01-15 14:03:59
Coco薇(2015年11期)2015-11-09 13:03:51
