基于前綴擴展的三級索引路由查找算法
2012-08-08 00:51:32唐麗梅邢素霞陳天華
網絡安全與數據管理 2012年19期
關鍵詞:信息
唐麗梅 ,邢素霞 ,陳天華
(1.北京工商大學 計算機與信息工程學院,北京 100048;2.北京英瑞博系統技術有限公司,北京 100039)
隨著網絡的高速發展,Internet的網絡傳輸量每幾個月就增加一倍,這也給高速路由的設計帶來了挑戰,骨干網路由器接口速率已經達到Tb/s量級,IP路由查找操作已經成為路由器轉發性能乃至Internet整體性能的主要瓶頸之一。因此提高路由查找速度的關鍵是采用快速的路由查找算法。
路由器IP路由查找面臨巨大挑戰,主要表現在:(1)實現最長前綴匹配的路由查找算法設計困難[1];(2)路由表龐大,查找記錄條目極多;(3)路由更新頻繁,最高每秒更新條目達幾萬條;(4)接口速率越來越高,OC-768(40 Gb/s)以太網及更高標準要求。實現 100 Gb/s接口的線速轉發,包轉發率要達到150 Mb/s,每包處理時延小于 6.72 ns。
快速的路由查找技術一直是一個熱門課題,近年來提出了不少路由查找算法,傳統的基于軟件的路由查找算法已經不能滿足分組的線速轉發,目前高性能核心路由器基本上都采用基于硬件的路由查找算法。路由查表實現的主要功能就是最長前綴匹配 (LongestPrefix Matching)。基于前綴值的二分搜索、頁面壓縮等基于樹的搜索存儲空間占用少,利用率高,但由于算法實現復雜,硬件實現上不合適。TCAM (Content Addressable Memory)[2]采用保存關鍵字掩碼的方式來保存任意長度的關鍵字表項,并且使用并行比較,僅在一個時鐘周期內就可以完成一次查表操作,能夠實現高速查表。但是TCAM的路由表更新操作復雜、功耗大[6]、容量小且價格昂貴。這些缺點使研究人員考慮用基于SRAM的算法來實現LPM。
在基于SRAM的算法中,SRAM每比特存儲需要6個晶體管,功耗低,TCAM每比特的價格是SRAM的30倍。可見,一個好的基于SRAM的算法比TCAM更具吸引力。由于路由查表的速度和復雜性的需要,采用單一的查找算法達不到理想的速度和效率,因此應采用多種算法的綜合以及輔助策略。
本文介紹的路由查找算法利用前綴擴展的特性,構造三級索引表,并利用流水線并行方式查表,最少一次訪問存儲器,最多3次訪問存儲器就能查找到包轉發信息(輸出端口、下一跳IP地址等)。由于對數據結構作特定優化,能支持動態分配表項空間。對更新算法加入緩存的思想,大大減小了地址占用和申請的開銷。
1 查找算法原理
1.1 前綴擴展特性[3]
本算法主要利用前綴擴展的特性,采用特定的結構來構造索引表。前綴擴展是將長度不同的前綴集合中所有小于最長前綴長度的前綴統一擴展為不小于最長前綴長度的集合。例如,有前綴集合 P={0*,10*,111*,11001*},其中最長前綴長度為 5,把所有長度小于 5的前綴加以擴展,擴展結果如表1所示。經擴展后,集合P形 成 一 個 新 的 集 合 P={00000*,00001*, … ,10111*,11100*,11101*,11110*,11111*}。 前綴擴展的目的是把任意長度的前綴變成固定長度的前綴來簡化查找操作。

表1 前綴擴展方法
1.2 算法實現
三級索引[4]的具體結構如圖1所示,其中給出如下定義:
需要擴展的前綴為Prefix=P(如P=111000*),前綴長度為Prefix length=PL,該前綴對應的下一跳地址為next hop=NH,端口號 port number=No。
根據骨干網路由表前綴長度分布[1],可以發現,前綴長度幾乎分布在 8~32,而且分布極不均勻,長度在 16~32的前綴約占總數的99%;前綴長度為24的路由最多,約占總數的45%。可見路由前綴小于8和大于24的表項非常少,因此小于8或大于24的前綴長度擴展的前綴集合絕大多數索引集為空,造成索引表的利用率非常低,而且隨索引前綴長度增加以指數衰減。根據這一特性,在本算法中做劃分前綴改進。通過擴展存儲長度小于16的前綴構造一級索引表;通過擴展存儲長度不大于24的前綴二級索引表;對于長度大于24的前綴不進行擴展,由于其數量非常少,進行前綴擴展就顯得浪費空間。
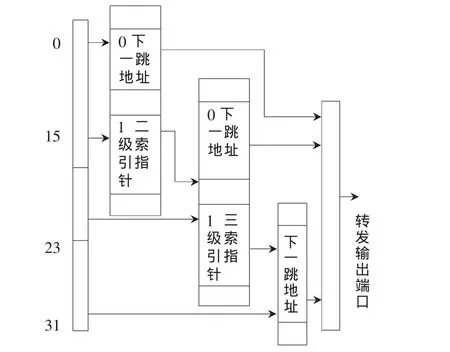
圖1 三級索引查表算法結構圖
本查找算法中對第3級索引表的查找方法進行改進。在二級索引表項中設置偏移量標志Rel。根據所有前綴中最大前綴長度為Lm,設IP地址的前24 bit相同的所有前綴中最大前綴長度為Lm,定義偏移量Rel為:
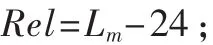
根據Rel的值動態分配一個獨立的SRAM用于儲存三級索引表項,最大需要地址空間為2Rel。這樣,整個路由表的大小將被控制在一個較小的規模,而不用引入復雜的位圖壓縮[5-6]來管理儲存空間。
動態分配二級表的存儲空間,根據一級表項中標志位1分配一個連續的256個SRAM地址空間,并將首地址作為基地址存儲在一級表中。對三級表分配獨立的SRAM。因此分別對3個表進行流水線查找,同時進行查找操作,使查表速度迅速提升。
第一級索引表地址從 0~32 767,一共有 32k個(215)地址空間,每個地址空間存儲的數據結構有兩種:下一跳信息或指向二級表的指針,Rel=24-Lm(前 16 bit中最大前綴長度)。其表項結構分別如圖2和圖3所示。
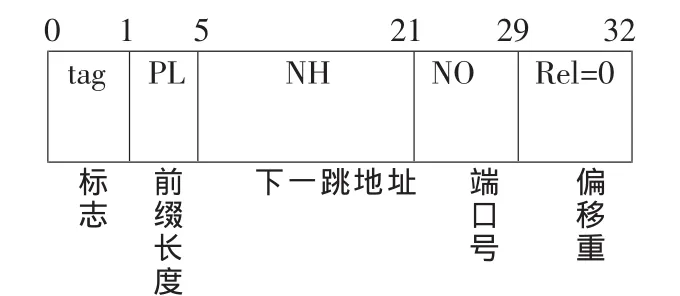
圖2 一級索引表中用于存儲下一跳信息的表項結構

圖3 一級表中用于存儲二級表指針信息的表項結構
每個一級表表項共有32 bit,第0 bit是指示標記(tag),用于指示該表項存儲的是路由信息還是指針信息,即當tag=0時表示該表項存儲的是下一跳路由信息(簡稱路由表項),包括路由前綴長度(PL)、下一跳 IP地址(NH)、端口號(No)以及偏移量信息,如圖 2所示;tag=1時表示該表項存儲的是指向二級索引表的地址索引信息,如圖 3所示。當 tag=0時,第 1~4 bit表示路由前綴長度,5~20 bit用于標記下一跳 IP地址,21~28表示輸出索引信息,29~32表示輸出端口號。考慮到長度在16~24 bit之間的前綴占99.93%,設置第二級索引表,擴展目的IP的第3字節,每個二級表從0到255,一共有256個地址空間。每個地址空間存儲的數據結構也有兩種(和一級表類似):下一跳信息或指向二級表的指針,其表項結構與一級索引結構類似。
對于長度小于16的路由前綴,根據一級索引表中的下一跳IP地址即可完成查找。對于長度大于16小于或等于24的路由前綴,需要同時對一級表和二級表進行存儲,首先在其前16 bit對應的一級表地址空間中存儲二級表的指針信息,而剩下的比特位則同樣通過前綴擴展的方法擴展到8 bit,然后再存儲到二級表中即可,擴展后在相應的表項中存儲的都是下一跳路由信息。二級表的表項結構如圖4所示。

圖4 二級表中用于存儲三級表指針信息的表項結構
對于長度大于24的路由前綴,需要同時對一級表、二級表和三級表進行存儲,首先在其前16 bit對應的一級表地址空間中存儲二級表的指針信息,而中間8 bit對應的二級表地址空間中存儲的是三級表的指針信息,對于剩下的比特位,根據其長度,根據二級索引表指針可在三級表的動態存儲空間中快速找到第三級地址,然后將路由信息存入其中,三級表中表項信息獲取完成后,查表過程結束。
2 路由表的更新
本算法的更新過程與查找過程都是先根據前綴對應的分段和索引查找到對應的子表,然后在其涉及的范圍內讀取各個表項,再根據表項的值確定是否用新的路由前綴信息覆蓋該表項。如果在查找該段前綴時,該表沒有相應的段空間,則需在儲存模塊中分配相應的存儲單元,當某段地址空間為空時,收回該儲存空間。路由表需要更新的時候,首先CPU根據前綴的長度進行擴展,送入FPGA進行判斷,根據路由表項信息完成插入和刪除操作。
2.1 一級索引表更新
對于長度不大于16的前綴Li,首先進行前綴擴展,得到 m個擴展前綴,在一級表中讀出以 Li(i=1,2,…,m)為地址的內容,若該內容是路由信息或是空白信息,則不作處理,將新的路由信息寫入一級表中的地址中即可;若該內容為二級表的指針信息,那么將該指針信息作為二、三路由表對應的SSRAM[7]中要釋放的地址塊號送到一級索引的SSRAM存儲空間管理模塊中。插入過程如圖5所示。

圖5 一級索引表更新
2.2 二、三級索引表更新
對于大于16的前綴長度的二、三級表更新算法,首先擴展到24 bit前綴。更新方式與一級索引表更新類似。此外,本算法引入Freeunit[2]來優化空間管理,改進更新操作。每種長度的地址前綴塊分配一個Freeunit,其容量根據前綴長度而定。較長的前綴塊對應的分配容量較大,反之,容量較小。Freeunit的實現可以采用堆棧或隊列等數據結構來實現。二、三級索引表更新前綴項進出緩存池過程如圖6所示。
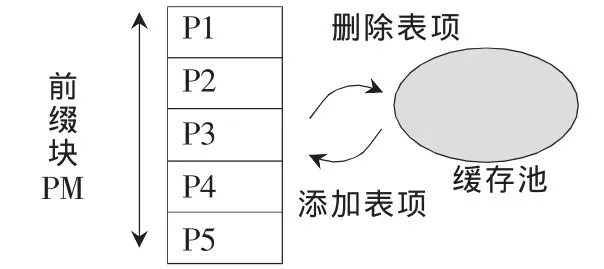
圖6 前綴項進出緩存池過程
把Freeunit作為一個緩沖池BP,當刪除一個表項時,只是單獨的將表項內容刪除,而不改變前綴塊和整個三級索引表項結構,同時將刪除的表項放入到Freeunit中;當添加新的表項時,從對應的 Freeunit中取出當前的空閑表項,直接添加,由此可以大大減少因為表項的添加和刪除而釋放地址空間所需時間,申請新的地址空間造成的時間開銷。
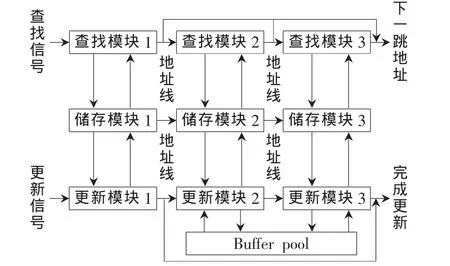
圖7 三級流水線并行處理算法硬件結構
硬件結構設計如圖7所示,三級索引結構包括3個流水線并行查找模塊和3個更新單元。每個表都需要一個單獨的SSRAM進行存儲,這樣,一共就使用6塊SSRAM。對于一級索引,有30 720個表項,每個表項有64 bit(8 B)存儲空間,則一個一級表就需要 237.5 KB大小的SSRAM,所以每個一級表選用了一個500 KB容量的SSRAM。第二級索引表和第三索引表的大小不能精確確定,選用了一個4 MB容量的SSRAM和2 MB容量的SSRAM。而對于第三級表,由于其容量很小,因此將三級表和二級表放在同一塊SSRAM里。每個查找模塊都可從輸入端或寄存器中讀取表項信息,解析IP地址位[8],訪問存儲器獲取數據,最后將數據寫入寄存器或者送到輸出端進行輸出轉發操作。

表2 算法查找速度比較表
3 實驗結果及算法比較
實 驗 環 境 為 :Celeron,500 MHz Windows XP,256 MB RAM。索引算法用FPGA實現,采用Xilinx公司的spartan-6系列芯片。它們可以提供豐富的片內SRAM資源,均以SRAM為儲存介質。為了測量性能,通過隨機數的方法產生隨機IP地址、掩碼和端口索引號,用數組記錄這些信息,在添加路由表前記錄系統時鐘,添加完成后又記錄一次系統時鐘,進行大量的插入操作后計算完成一次操作所用的時間。查找與刪除操作也采用同樣的方法來測量。通過對比可知,三級前綴劃分并改進第3級索引可有效提高地址空間利用率,減少空索引集數量,加入緩存的更新算法有效減少了更新開銷時間,從而提升查找速度。由于查找需要一個時鐘周期,而時鐘頻率為100 MHz,因此每秒可以完成100 M次查找,假設報文長度均為40 B,可以滿足20 Gb/s的鏈路速率。
算法查找速度比較表如表2所示,算法存儲容量比較表如表3所示。從實驗結果來看,當表項數目較小時,二進制trie樹查找[9]過程表項次數較多,相應的查找速度也較慢。隨著表項數目的增加,查找速度變化非常緩慢,已經不能適用于快速的路由查找。對于動態前綴樹查找方法,查找中表項比較的次數隨表項數目變化的速度比較緩慢,相應的查找性能變化比較平緩,基本維持在同一個數量級上,平均查找速度低。二級索引頁面壓縮算法查找速度隨查找表項的數目變化的速度較緩慢,相應的查找性能較好,由于壓縮處理,表項占用空間很小。缺點是壓縮算法[10]用硬件實現不合適。四級流水線查找速度快,訪存次數少,此算法使用的存儲容量比較大,特別是在表項數目較多的情況下。與三級索引SRAM快速查找RAM的查找算法相比,三級索引算法具有很快的查找速度,甚至當表項數目達到100 000時,仍然可以達到50 Mp/s多的查找速度。從存儲容量上來看,較四級流水線RAM查找存儲容量更小。由比較可知,三級索引SRAM快速查找在查找速度、儲存空間、更新速度方面都具有優勢。該算法非常適于需要高速報文轉發的網絡環境。
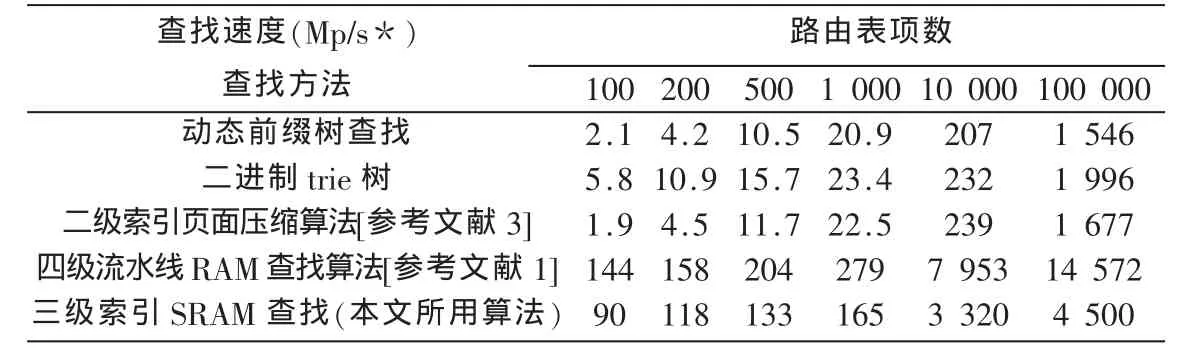
表3 算法存儲容量比較表
本文提出基于三級索引來實現路由查表算法,并利用前綴擴展和引入更新緩存的技術來實現優化。最快的查找只要一次訪問存儲器就可以找到端口索引,獲得下一跳信息需要2次訪問存儲器。最多3次訪問存儲器就可以獲得端口索引。在實現高速查找的同時,兼顧到存儲空間利用率和實現復雜度等多種因素,比單純使用四級流水線查找速度提高了15%;對第3級索引表采用動態管理,節省了30%儲存空間。
[1]王波.基于FPGA的快速路由查找算法研究及實現[D].西安:西安電子科技大學,2009.
[2]苗建松,丁煒.改進的TCAM路由更新方法與實現[J].微電子學與計算機,2006,23(10):144-149.
[3]劉亞林,劉東.基于前綴擴展的快速路由查找算法[J].計算機學報,2001,24(12):1272-1278.
[4]張毅,郭玲麗.基于 FPGA的高速路由查找算法[J].電子元器件應用,2009,11(9):22-27.
[5]彭元喜,唐玉華,龔正虎.基于壓縮 NH表的高速 IP路由查找算法的研究[J].電子學報,2002,(2):32-36.
[6]王利媛,馬躍,徐塞虹.對路由表結構和查找算法的研究[J].計算機應用,2004(11):10-12.
[7]MCEWAN A A,SAUL J.A high speed reconfigurable firewall based on parameterizable FPGA-based content addressable memories[J].The Journal of Supercomputing,2001,19(1):93-103.
[8]IOANNIDIS I, GRAMA A, ATALLAH M J.A-daptive data structures forIP lookups[J]. AlM Journalof Experimental Algorithmics, 2005(10):75-84.
[9]譚興曄,張勇,雷振明.基于快速搜索樹的路由查表算法[J].計算機應用研究,2005(7):231-235.
[10]徐恪,吳建平,吳劍.路由查找算法評價系統的設計與實現[J].小型微型計算機系統,2003,24(2):274-276.
猜你喜歡
中華手工(2017年2期)2017-06-06 23:00:31
中外會展(2014年4期)2014-11-27 07:46:46
大眾創業(2009年10期)2009-10-08 04:52:00
數字社區&智能家居(2009年7期)2009-09-29 08:16:48
數字社區&智能家居(2009年11期)2009-06-25 04:30:34
數字社區&智能家居(2009年3期)2009-04-21 03:09:04
數字社區&智能家居(2009年2期)2009-03-27 04:33:44
數字社區&智能家居(2009年12期)2009-02-03 07:50:48
建筑創作(2001年3期)2001-08-22 18:48:14
祝您健康(1987年3期)1987-12-30 09:52:32
