基于S4框架的并行復雜事件處理系統
2012-08-07 09:42:38陳皓李瑜虎嵩林梁英
通信學報 2012年1期
陳皓,李瑜,虎嵩林,梁英
(1. 中國科學院 計算技術研究所,北京 100190;2. 中國科學院 研究生院,北京 100049)
1 引言
當今社會是一個信息爆炸的社會。由于離散數據源的增加,如標簽、微博、傳感技術等的發展,使得信息處理系統所需要進行處理的數據量大大增加。另外,社交網絡、高頻交易、實時搜索等新應用的出現,對處理速度的要求達到了傳統處理系統的極限。由于海量數據是具有時效性的,最佳的解決方法不是先把數據在數據庫中緩存起來再一批一批地處理,而是每當數據出現時便進行一次處理,實時地處理數據。復雜事件處理技術[1,2](CEP, complex event processing)作為信息處理系統的新興技術,具有高吞吐量、短延遲和復雜計算的特點。它采用以事件驅動為基礎的架構,可處理不同事件源、不同類型的事件。它通過分析事件間的關系,利用過濾、關聯、聚合、排序等技術,將輸入簡單事件同其他事件聯系起來進行檢測,在特定的上下文中分析計算,最終由簡單事件產生輸出復雜事件。
復雜事件處理系統所需處理的數據流量往往非常大,然而用戶卻希望實時地得到結果。面對海量而關系復雜的信息,系統還須進行快速地計算繼而快速決策,這對系統的吞吐量提出了很高的要求,單一節點的處理速度往往難以滿足需要。
MapReduce[3,4]是目前應用極為廣泛的并行軟件構架。它使用鍵值對描述數據,將復雜的運算分成“Map(映射)”和“Reduce(化簡)”2個獨立步驟進行處理。Map和Reduce都是對其輸入數據中的元素進行獨立地操作,所以這2個運算步驟都是可以并行的,但Reduce操作要等待所有Map操作完成才能開始。MapReduce模型可以很容易地將多個通用批處理任務和操作在大規模集群上并行化。但MapReduce是批量處理數據的,它將輸入數據切成小的片段,每隔一個周期就啟動一次MapReduce任務。處理任務不是常駐服務,數據也不是實時流入,任務的分割難以滿足數據流實時處理的需求。因此,MapReduce框架不是并行CEP的合理方案。
Storm[5]是一種分布式實時計算系統框架,它由一個主節點和多個工作節點組成。主節點用于分配代碼、布置任務和故障檢測。工作節點用于監聽工作、開始并終止工作進程。它以有向圖定義系統的邏輯拓撲結構,每個節點將以指定的進程數動態分布在集群中,而事件消息按照預定義的分組方式分發至邏輯節點對應的處理進程。作為編程框架,它實現了事件驅動的實時處理,但未提供對復雜事件處理中事件關系處理的支持,需要用戶根據場景自行開發,其并行方式也需要用戶按照經驗自行配置,普通用戶難以使用。
本文針對復雜事件處理對吞吐量的需求,將通用CEP系統搭建在使用S4[6]并行處理框架的集群上,使用基于操作符的負載分流方法,將事件流分散到多處理節點上并行處理。既方便了普通用戶對CEP系統的配置,又提高了CEP系統的處理效率。
2 并行CEP系統
復雜事件處理通常按照應用場景的需求,由一系列的事件生產者、處理代理、事件消費者組成。邏輯上是一個有向圖,事件按照邊進行傳遞,每個代理表示對于事件的一個操作。事件從生產者處被生產出來,最終流到了消費者,從而完成了處理過程。
把操作符看做對于復雜事件處理的基本功能單位。各種操作符組合,以共同完成對于復雜時間的處理。將事件處理中的處理邏輯抽象出來,組合成一個一個的事件代理,而不是按照具體應用程序定制處理過程,這種方法更為實用和強大。設計了14種操作符,這些操作符可過濾事件,對事件進行多種變形和提供流上的模式識別功能以及一些簡單的系統輔助功能。不僅使單個操作符的功能具有實用性,而且使多個操作符組合后能夠滿足對于事件分析的需求。在操作符的基礎上進行CEP場景建模,使普通業務人員也能高效地定義配置CEP系統。
S4(simple scalable streaming system)是一個去中心的、分布式的、可擴展的流式處理系統。類似于Storm的消息分組策略,S4框架通過對流事件的關鍵字進行散列計算,得到處理事件的節點編號,再將事件發送到對應節點進行處理。通過修改S4框架的事件分流機制,基于操作符的不同,使用不同的分流策略,實現了并行的通用CEP系統。圖1描繪了其系統結構。圖中箭頭方向為事件流向。處理節點通過網絡連接在一起,單個處理節點由CEP引擎、事件接收器、事件發送器和事件分流器組成。
事件接收器用于接收其網絡層發來的或處理節點內部的事件消息,它將按照事件流名稱將事件放入不同的流中,交給CEP引擎處理;CEP引擎以操作符為基本運行單位,事件根據其流的類型交由特定的操作符處理,處理結果將發往分流器;分流器應用負載分流策略,基于目標操作符和事件內容進行運算,決定該事件由哪個節點處理。如果是本地節點,事件將進入本地的接收器,重新發送給CEP引擎;如果是其他節點,將送至事件發射器,通過網絡發送給其他節點;發射器負責將事件發送給集群上的其他節點。S4初始版本只支持UDP的發送方式,將其改為帶有隊列的TCP方式,雖然增加了集群內部連接數,但防止了事件的丟失。
該系統通過分流器,將事件分流至不同的處理節點,使得事件流得以在集群中多機并行處理,提高了系統整體吞吐。在系統節點部署時,各個CEP引擎中使用相同的操作符配置。節點部署的物理機器可手工配置,也可通過Zookeeper[7]協同自動分配。通過提供備用節點,還可提高系統的可靠性。

圖1 并行CEP結構(4節點)
3 基于操作符的負載分流優化方法
當面對高速數據流時,如果能將負載均勻地分流到集群的各個節點,并行地處理事件流,則可以增加系統的吞吐量。然而復雜事件處理的特殊性在于事件往往不是孤立地存在,在處理中需要根據事件流上下文或其他事件流進行決策,單純地拆分數據流到不同節點,會影響事件間的關系,導致處理出錯。
基于操作符的負載分流方法,根據目標操作符的不同,使用不同的分流策略,實現動態分流。本節將給出6種操作符的分流方案。
操作符的輸入流和輸出流均是由事件組成的,將事件表示為(K,V)的集合。輸入流事件表示為(Ki,Vi),輸出事件流表示為(Ko, Vo),中間結果表示為(Km,Vm)。每個操作符都是在輸入流上進行計算,這個計算過程可以用函數operator來表示,最終將產生的結果放入輸出流。操作符的這一處理過程用如下的表達式來表示
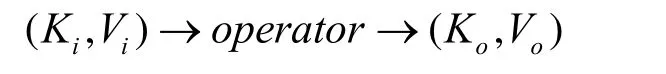
1) 過濾操作符。首先使用分流器輸入分散到各處理節點,然后每個處理節點分別進行原本的過濾操作,最后合并結果。這一分流過程可表示為
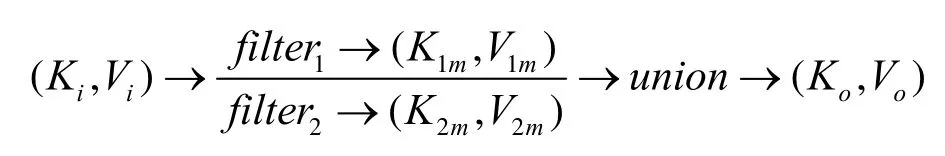
2) 映射操作符。首先使用分流器輸入分散到各處理節點,然后每個處理節點分別進行原本的映射操作,最后將結果合并。這一分流過程可表示為

3) 分裂操作符。首先使用分流器輸入分散到各處理節點,然后每個處理節點分別進行原本的分裂操作,最后須按原分裂目標合并結果,這一分流過程可表示為

4) 合并操作符。首先使用分流器輸入分散到各處理節點,然后每個處理節點分別進行原本的合并操作,最后將結果合并,這一分流過程可表示為
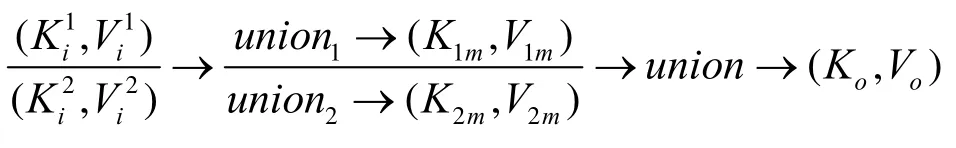
5) 查詢操作符。查詢表和物化窗口都屬于輔助表操作符,它們在內存中建立一塊數據的緩存,供一個或者多個查詢操作符進行插入、查詢、更新或刪除操作。分流的方案是將插入表的輸入流數據通過分流器分散到各處理節點,在每個節點上建立表,其他操作的輸入流需要復制到每個節點, 最后將結果合,并這一分流過程可表示為

6) 聚集操作符。它根據2個及2個以上輸入流的屬性值相等性進行連接操作。使用分流器將輸入流上鍵值屬于同一個范圍的事件分流到相同節點上,各節點再分別進行聚集操作最終將結果合并。這一分流過程可表示為

在實際應用中,不需要將結果進行和并,因為操作符是連續進行流水線作業的,結果直接通過分流器進入下一個分流階段。對于無法分流的操作符,如依據事件到達順序進行計算的操作符,仍可配置分流器分流到指定的節點。
基于操作符特點進行動態地分流,既使分流工作對用戶透明地自動完成,也使分流工作有針對性,有助于減輕處理節點的負載,整體上提高系統效率。
4 實驗結果與分析
為了驗證并行CEP系統的性能,在8臺機器構成的集群上進行了實驗,每臺機器的配置為主頻1GHz,8核處理器,8G內存。
4.1 實驗配置
實驗主要測試的是事件處理吞吐量。它反應了系統在單位時間內能處理的事件的規模,用每秒鐘處理的事件數量來量化表示。計算的方法是用總共處理的事件數量除以處理的時間。
數據來自國家電網智能園區的用電數據來模擬輸入的事件流。事件輸入流包括電表電量流、電價流和企業信息流3個。其中最重要的是電表電量流,它是每10s采集一次的電表讀數。使用了200塊電表一天內采集的所有讀數,共1 728 000條數據。實驗的方法是在是持續不停地向并行CEP系統中發送電表數據,在輸出端進行吞吐量的度量。
4.2 實驗結果
實驗實時計算指定時間間隔內各個企業的電費。采用了1~8臺機器對輸入流進行相同邏輯的復雜事件處理。3個查詢所包括的操作符如圖2所示,所測得的系統的吞吐量如圖3所示。

圖2 查詢所包含的操作符數量

圖3 不同節點數的事件吞吐量
由圖2和圖3可見,查詢一、查詢二和查詢三在節點數目增加的情況下吞吐量有顯著的提升。并且,吞吐量當到達峰值后,由于節點的數目的增加會大大增加消息傳遞的通信開銷,吞吐量會減少。由于吞吐量同查詢的復雜程度相關,可見查詢一的峰值吞吐量最大,而查詢三的峰值吞吐量最小。而由于處理節點數目越多,節點間的通信開銷所占比重越大。并且,受限于集群的網絡環境,通信開銷極大地影響了系統的吞吐量。所以,當節點的數目繼續增加時,查詢三的吞吐量減少得更為明顯。
對6種操作符的負載分流性能進行了評測。對于每個操作符,分別在不同分流的數目情況下進行了實驗。以下實驗結果均是在4個節點的分布式環境下得到的。
圖4顯示了不同的操作符所設計的分流方案所包含的操作符個數。圖5顯示了實驗所測得的不同操作符在不同的分流方案下運行所得的吞吐量。由圖4和圖5可知,在分流的數量增加的情況下,系統的吞吐量有所提升。而由于分流數量增加,事件的通信開銷會增加,所以當分流數量進一步增加的情況下,系統的吞吐量會降低。由于所涉及的操作符的運算開銷相差不大,所以各個操作符的實驗結果無明顯區別。
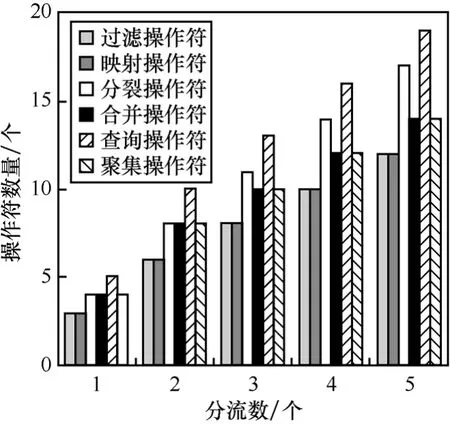
圖4 負載分流后所得的實際操作符數

圖5 操作符在不同的負載分流方案下的吞吐量
實驗結果表明,并行CEP系統的吞吐量在一定范圍內隨著集群處理節點數的增加線性增長,數倍于單機的處理能力。
5 結束語
本文針對復雜事件處理系統要求處理海量事件、進行復雜計算和簡易直觀建模的需求,設計了14種操作符給出了6個操作符的負載分流方案,然后在S4框架下搭建了并行CEP系統的方法,實驗證明并行CEP系統能有效地提高系統的吞吐量。進一步工作將深入分析其他操作符的分流方案,提高系統的并行率。
[1] LUCKHAM D C, VERA J. An event-based architecture definition language[J]. IEEE Transactions on Software Engineering, 1995, 21(9):717-734.
[2] LUCKHAM D C. The Power of Events: An Introduction to Complex Event Processing in Distributed Enterprise Systems[M]. Boston: Addison-Wesley Professional, 2002.
[3] DEAN J, GHEMAWAT S. Mapreduce: simplified data processing on large clusters[J]. Commun ACM, 2008, 51(1): 107-113.
[4] CONDIE T, CONWAY N, ALVARO P, etal. Map reduce online[A].Proceedings of the 7th USENIX Conference on Networked Systems Design and Implementation[C]. Berkeley, San Jose, CA, USA, 2010. 21.
[5] Storm wiki[EB/OL].http://github.com/nathanmarz/storm/wiki,2012.
[6] NEUMEYER L, ROBBINS B, NAIR A, etal. S4: distributed stream computing platform[A]. The 10th IEEE International Conference on Data Mining Workshops[C]. Sydney, Australia, 2010. 170-177.
[7] Zookeeper[EB/OL]. http://zookeeper.apache.org/,2012.
猜你喜歡
小獼猴智力畫刊(2022年9期)2022-11-04 02:31:42
工業設計(2022年8期)2022-09-09 07:43:20
中學生數理化·中考版(2022年11期)2022-02-16 07:01:20
軍民兩用技術與產品(2021年10期)2021-03-16 06:05:30
北京測繪(2020年12期)2020-12-29 01:33:58
裝備制造技術(2019年12期)2019-12-25 03:06:46
小哥白尼(趣味科學)(2019年6期)2019-10-10 01:01:50
中國洗滌用品工業(2019年4期)2019-05-11 09:27:34
家庭影院技術(2017年9期)2017-09-26 03:41:45
發明與創新(2016年38期)2016-08-22 03:02:52
