語音情感識別中特征參數的研究進展*
2012-07-25 05:36:16李杰,周萍
傳感器與微系統 2012年2期
李 杰,周 萍
(1.桂林電子科技大學計算機科學與工程學院,廣西桂林 541004;2.桂林電子科技大學電子工程與自動化學院,廣西桂林 541004)
0 引言
隨著計算機技術的高速發展和人類對計算機依賴性的不斷增強,人機交流變得越來越普遍,人機交互能力也越來越受到研究者的重視,語音情感識別就是人機交互與情感計算的交叉研究領域。語音中的情感之所以能夠被識別與表達,是因為語音特征在不同情感狀態下的表現不同。因此,很多研究者對特征與情感類別之間的對應關系產生了濃厚的興趣并進行了深入的探討。Murray I和Amott J L完成的實驗得出了基頻、能量、時長等韻律特征,以及語音質量特征與情感之間的定性關系[1],使得韻律學特征成為語音情感識別的常用特征。此后,研究者又加入了共振峰參數和語音學特征,如MFCC,使得韻律學特征與語音學特征結合識別情感。通常在利用這些基本特征進行研究時,還需要求出其派生特征和各種統計特征,如范圍、均值和方差等,并把它們組成特征向量。由于到目前為止,聲學特征與情感狀態的對應關系缺乏統一的結論,為了盡可能保留有意義的信息,研究者只能在研究中保留這維數少則幾十條多則上百條的特征向量。但根據模式識別的理論,高維特征集合不僅不會提高識別率,還會造成“維數災難”[2]。大量的研究表明:語音情感識別的關鍵就在于從數量眾多的特征中求得高效的情感聲學特征組,這就需要用到特征降維技術。
目前,已有數篇綜述文獻總結了語音情感識別的研究成果[3~6],但主要都是針對識別算法的研究進展進行綜述。本文從模式識別的角度對目前語音情感識別研究中所采用的特征降維技術進行總結,并對近幾年提出的情感特征參數進行闡述。
1 語音情感識別系統的概述
基于語音的情感識別大致分為預處理、特征提取和情感分類三步,大致框架如圖1所示。特征提取作為情感分類的前向步驟,能直接影響到最終的識別效率,是從輸入的語音信號中提取能夠區分不同情感的參數序列。在提取特征數據時,為獲得最優特征子集還需進行對特征降維。
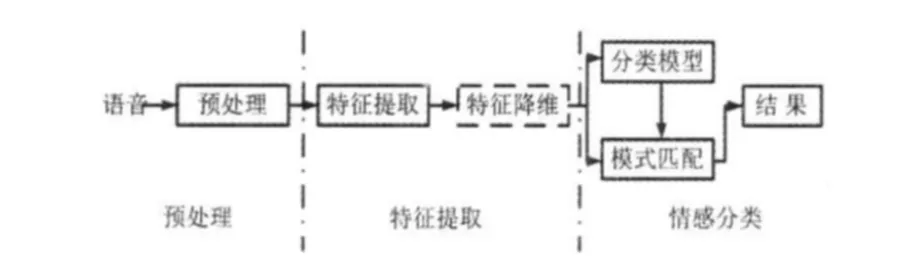
圖1 語音情感識別系統Fig 1 Speech emotion recognition system
2 語音情感特征參數
本文從發音語音學和聲學語音學兩方面出發,將語音情感分為基于發音特征參數和基于聲學特征參數。
2.1 基于發音特征參數
此類特征按照語音信號生成的數學模型不同,分為線性激勵源—濾波器(source-filter)語音生成模型特征和非線性語音生成模型特征。
2.1.1 線性激勵源—濾波器語音生成模型特征
在激勵系統中,聲門每開啟和閉合一次的時間就是基音周期,其倒數稱為基頻,決定了語音的音調高低。由于語音是聲門激勵信號和聲道沖激響應的卷積,直接對語音提取基音周期將受到聲道共振峰的影響,所以,需要先求出聲門激勵信號(聲門波)。獲得聲門波的常用方法有線性預測法和倒譜分析法,都是基于聲道建模,通過逆濾波消除共振峰的影響得到聲門波。由于這2種方法只是對聲道傳輸特性的近似,故通過逆濾波得到的聲門波差分波形頻譜都會不可避免地帶有“波紋”。為了準確估計聲門波參數,研究者提出了對聲門波進行參數建模的方法,其中LF[7]模型最常用。趙艷等人[8]將通過該方法提取的音質參數運用到情感識別中去,取得了不錯的識別率。
歸一化振幅商(normalized amplitude quotient,NAQ)是由文獻[9]提出的,一種新的用來刻畫聲門激勵特性的時域參數。Airasm A P[10]和白潔等人[11]分別比較了連續語音中單一元音的較短片段、整句及元音段NAQ值的情感識別效果,實驗表明了元音段的NAQ值是一種具有判別力的語音情感特征。
共振峰是當聲音激勵進入聲道引起共振產生的一組共振頻率。不同情感的發音可能使聲道有不同的變化,因此,共振峰是反映聲道特性的一個重要參數。提取共振峰參數的方法主要有倒譜法和線性預測法(LPC)。
2.1.2 非線性模型特征
傳統的線性聲學理論認為,聲音的產生取決于聲帶的振動和聲道內的激勵源位置。而Teager H等人[12]認為聲源是聲道內非線性渦流的交互作用。為度量這種非線性過程產生的語音,文獻[12]提出了能量操作算子(teager energy operator,TEO)。隨著TEO的提出,許多基于TEO的特征被用于識別語音中的情感。文獻[13]將多分辨率自帶分析與TEO結合,提出一種新的特征參數TEOCEP,其識別性能優于使用短時能量的自帶倒譜參數。高慧等人[14]結合小波分析將不同形式的TEO與MFCC結合提出了5種非線性特征,當與文本有關時,這些特征語音情感識別的效果優于MFCC。林奕琳[15]將基于TEO的非線性特征用于帶噪語音情感的識別,證明了上述特征具有較高魯棒性。
2.2 基于聲學特征參數
2.2.1 聽覺模型特征
研究者發現人耳在嘈雜的環境中之所以仍能正常地分辨出各種聲音,耳蝸是其中的關鍵所在。耳蝸相當于一個濾波器組,在低頻區呈線性關系,在高頻區呈對數關系,從而使得人耳對低頻信號更敏感。根據這一原則,研究者根據心理學實驗得到了類似于耳蝸作用的一組濾波器組——Mel頻率濾波器組。研究者又利用這一原理和倒譜的解相關特性提出了Mel頻率倒譜系數(Mel frequency cepstrum coefficient,MFCC)。MFCC在語音情感識別領域已經得到廣泛的應用。
2.2.2 非基于模型特征
這類特征通常不假設語音模型,如語速、短時平均過零率、發音持續時間和能量等,文獻[5]對這些特征進行了詳細的敘述。研究者發現以往常被用于診斷喉部疾病的諧波噪聲比(HNR)可以有效評估說話人嗓音嘶啞程度,余華[16],趙艷等人[8]已把HNR作為特征參數成功運用于語音情感識別當中。
3 特征降維
高維數據特征不僅可能造成維數災難,而且其可能存在較大的數據冗余,影響識別的準確性。為了有效地進行數據分析,提高正確識別率和降低計算工作量,特征降維就顯得異常重要。特征降維包括特征抽取和特征選擇。特征抽取是用全部可能的變量把數據變換(線性或非線性變換)到維數減少了的數據空間上。特征選擇是選出有用的或重要的特征,而去除其他的特征。
3.1 特征抽取
3.1.1 線性特征抽取算法
主成分分析(principal component analysis,PCA)和線性判別分析(linear discriminant analysis,LDA)是最常用的線性特征抽取算法。PCA因未能利用原始數據中的類別信息,降維后的數據有時反而不利于模式分類,直接用于語音情感識別時效果并不好。LDA考慮了訓練樣本的類別信息,強調了不同類別樣本之間的分離,用于語音情感識別時取得了良好的識別率[17]。文獻[2]針對PCA,LDA在不同性別、不同情感狀態有不同的識別表現,設計了結合PCA和LDA的分層次語音情感識別系統,取得了較高識別率。
3.1.2 非線性流形特征抽取算法
近年來,研究人員發現語音信號中的特征數據位于一個嵌入在高維聲學特征空間的非線性流形上,這使得流形學習算法開始被用于語音特征參數的非線性降維處理。
等距映射(isometric feature mapping,Isomap)和局部線性嵌入(locally linear embedding,LLE)算法是該類算法中較為常用的。Isomap和LLE都屬于非監督方式的降維方法,沒有給出降維前后數據之間的映射關系,新的測試數據并不能直接投影到低維空間,直接應用于語音情感識別時識別率都不高,甚至不如線性的PCA[18],因此,應用于語音情感識別時算法都需要進行改進。陸捷榮等人[19]在Isomap算法基礎上提出基于增量流形學習的語音情感特征降維方法,實驗表明具有較好的識別效果。Ridder等人使用考慮數據類別信息的監督距離修改LLE算法中的鄰域點搜索,提出了一種監督式的局部線性嵌入(supervised locally linear embedding,SLLE)算法,文獻[18]又在 SLLE基礎上提出了一種改進的監督局部線性嵌入算法(improved-SLLE),并用Improved-SLLE實現了對48維語音情感特征參數數據的非線性降維,提取相應的特征進行情感識別,取得了90.78%的正確識別率。
增強型 Lipschitz嵌入(enhanced Lipschitz embedding,ELE)算法是尤鳴宇[2]基于 Lipschitz嵌入算法[20]提出的一種新的特征降維算法。ELE主要對樣本點到樣本集合(各種情感)中各點的最短距離的求取和新加入測試點的投影方式進行補充完善。在ELE中,當有新進測試點需進行投影時,距離矩陣M被重新構造以包含新樣本點的信息,雖然這種方法需要消耗一定的計算時間,但卻可以最大限度地發揮算法的優勢,而且由于ELE算法較簡單,投影新測試點時并不需要重新構建距離矩陣M。ELE解決了Isomap和LLE所未解決的將新進測試樣本投影到目標空間的問題。同時,文獻[2,21]也證明了基于ELE的語音情感識別系統具有較高正確率,且對噪聲具有較高的魯棒性。
3.2 特征選擇
按照特征子集的生成方法,特征選擇可分為窮舉法、啟發式算法和隨機算法。
3.2.1 窮舉法
窮舉法是一種最直接的優化策略,對p個變量中選出d個變量,搜索nd=p!/(p-d)!d!種可能的子集。盡管該方法確定能找到最優子集,但是,由于計算開銷過大,實用性不強。
3.2.2 啟發式算法
啟發式算法是使用啟發式信息得到近似最優解的算法。它是一個重復迭代而產生遞增或遞減的特征子集的過程,從當前特征子集出發,搜索下一個增加或刪除的特征時,需要通過一個啟發函數來選擇代價最少的方案。此類方法不需要遍歷所有特征組合,就可以估計出一個較為合理的特征子集,具有實現過程簡單、運行速度快等優點。語音情感識別中常用的啟發式算法有順序向前選擇(SFS)、順序向后選擇(SBS)、優先選擇(PFS)、順序浮動前進選擇(SFFS)和逐步判別分析法(SDA)等。Kwon O W等人[22]采用SFS和SBS兩種方法進行特征選擇,建立了聲學特征的情感判別力強弱排名的二維等級圖,指出基頻、對數能量和第一共振峰對語音情感識別的重要性。Lugger M等人[23]使用SFFS先從韻律特征和嗓音特征中分別選取4個特征參數,而后又從混合特征集中選取8個特征,其中包括6個韻律特征和2個嗓音特征。謝波等人[24]針對普通話情感語音特征分別用PFS,SFS,SBS和SDA進行特征選擇,分析了特征個數和特征選擇方法對平均準確率的影響,最后進行了特征選擇的有效性分析。
3.2.3 隨機算法
隨機算法可分為完全隨機與概率隨機兩類,前者指純隨機產生子集,后者指子集的產生依照給定的概率進行。目前,被運用于語音情感識別的有遺傳算法(genetic algorithm,GA)和神經網絡分析法等。
遺傳算法是一種以遺傳和自然選擇的進化論思想為啟發的算法,通過選擇并遺傳適應環境的特征得到所需特征子集。首先,選取適應性函數值最大的若干個特征組成初始特征集,并從該集合中選取2個特征,被選中的機率與其“適應能力”呈正比。在這2個特征間使用“交配”算法和“突變”算法,再從得到的特征中選取“適應能力”強的幾個加入特征子集。重復前兩步,直到獲得所需的分類特征子集。王穎[25]提出了一種改進的自適應遺傳算法語音情感識別方法,實驗結果表明,改進后的算法具有良好的識別效果。
神經網絡分析法是王小佳[26]利用神經網絡的貢獻原理選出有效特征的方法。王小佳將其提取的101個語音情感特征通過神經網絡貢獻分析進行選擇,通過聚類性分析驗證了所選擇特征的有效性。
4 結束語
1)研究者們已分析了多種類型的特征,但就特征提取而言,不同的提取方法會產生不同的特征精度,如基頻的提取目前仍是一項開放的研究課題。因此,需要研究出更加精確的特征提取方法。
2)由于語音情感變化會造成諸多語音特征發生變化,將多種特征融合起來可以更全面地表現情感。多類特征組合是特征獲取的一個新興研究方向,目前已有少部分學者開始研究。
3)對語音情感進行高效識別,必須對特征降維方法進行更針對的研究,目前,特征降維應用于語音情感識別還只是一個起步階段,需要更多的研究和嘗試。
[1]Murray I,Amott J L.Towards the simulation of emotion in synthetic speech:A review of the literature on human vocal emotion[J].Journal of the Acoustic Society of American,1993,93(2):1097 -1108.
[2]尤鳴宇.語音情感識別的關鍵技術研究[D].杭州:浙江大學,2007.
[3]余伶俐,蔡自興,陳明義.語音信號的情感特征分析與識別研究綜述[J].電路與系統學報,2007,12(4):77 -84.
[4]林奕琳,韋 崗,楊康才.語音情感識別的研究進展[J].電路與系統學報,2007,12(1):90 -98.
[5]趙臘生,張 強,魏小鵬.語音情感識別研究進展[J].計算機應用研究,2009(2):428 -432.
[6]章國寶,宋清華,費樹岷,等.語音情感識別研究[J].計算機技術與發展,2009(1):92-96.
[7]Fant G,Liljencrants J,Lin Q.A four-parameter model of glottal flow[J].STL-QPSR 4,1985,26(4):1 -13.
[8]趙 艷,趙 力,鄒采榮.結合韻律和音質參數的改進二次判別式在語音情感識別中的應用[J].信號處理,2009(6):882-887.
[9]Paavo A,Tom B,Erhhi V.Normalized amplitude quotient for parameterization of the glottal flow[J].Journal of the Acoustical Society of America,2002,112(2):701 -710.
[10]Airasm A P.Emotions in short vowel segments:Effects of the glottal flow as reflected by the normalized amplitude quotient[C]//Proceedings of Tutorial and Research Workshop on Affective Dialogue Systems,2004:13 -24.
[11]白 潔,蔣冬梅,謝 磊.基于NAQ的語音情感識別研究[J].計算機應用研究,2008,25(11):3243 -3258.
[12]Teager H,Teager S.Evidence for nonlinear production mechanisms in the vocal tract[C]//Speech Production & Speech Modeling,1990:241 -261.
[13]Jabloun F.Large vocabulary speech recognition in noisy environments[D].Ankara,Turkey:Bilrent University,1998.
[14]高 慧,蘇廣川.情緒化語音特征分析與識別的研究進展[J].航天醫學與醫學工程,2004,17(5):77-80.
[15]林奕琳.基于語音信號的情感識別研究[D].廣州:華南理工大學,2006.
[16]余 華,黃程韋,金 赟,等.基于改進的蛙跳算法的神經網絡在語音情感識別中的研究[J].信號處理,2010(9):1295-1299.
[17]Go H,Kwak K,Lee D,et al.Emotion recognition from the facial image and speech signal[C]//Proceedings of Annual Conference of SICE,2003:2890 -2895.
[18]張石清,李樂民,趙知勁.基于一種改進的監督流形學習算法的語音情感識別[J].電子與信息學報,2010(11):2724-2729.
[19]陸捷榮.基于流形學習與D-S證據理論的語音情感識別研究[D].鎮江:江蘇大學,2010.
[20]Bourgain J.On lipschitz embedding of finete metric spaces in hilbert space[J].Journal of Mathemetics,1985,52(1 -2):46 -52.
[21]劉 佳.語音情感識別的研究與應用[D].杭州:浙江大學,2009.
[22]Kwon O W ,Chan K,Hao J.et al.Emotion recognition by speech signals[C]//Proceedings of Eurospeech,Geneva,2003:125 -128.
[23]Lugger M,Yang B.The relevance of voice quality features in speaker independent emotion recognition[C]//IEEE International Conference on Acoustics,Speech and Signal Processing,Honolulu,HI,2007:17 -20.
[24]謝 波,陳 嶺,陳根才,等.普通話語音情感識別的特征選擇技術[J].浙江大學學報:工學版,2007(11):1816-1822.
[25]王 穎.自適應語音情感識別方法研究[D].鎮江:江蘇大學,2009.
[26]王小佳.基于特征選擇的語音情感識別研究[D].鎮江:江蘇大學,2007.
猜你喜歡
數學小靈通·3-4年級(2024年2期)2024-05-15 02:02:28
中國生殖健康(2020年5期)2021-01-18 02:59:48
世界科學技術-中醫藥現代化(2020年2期)2020-07-25 02:05:36
家庭醫學(下半月)(2020年4期)2020-05-30 12:42:50
北極光(2019年12期)2020-01-18 06:22:10
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
小太陽畫報(2019年10期)2019-11-04 02:57:59
當代陜西(2019年10期)2019-06-03 10:12:04
中國生殖健康(2018年5期)2018-11-06 07:15:40
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
