淺析Web元搜索引擎排序算法
2012-07-04 13:34:02桑秀芝
合作經濟與科技 2012年5期
文/桑秀芝
(南京航空航天大學金城學院 江蘇·南京)
一、序言
Internet上的信息量已呈爆炸性趨勢增長,據研究報告顯示,Internet上的網頁目前已超過數百億,如何從浩如煙海的信息中查找需要的信息成為人們最關心的事情。搜索引擎就是為了幫助人們解決這一問題而開發出的一種高效的信息檢索工具,它已經成為Internet中最重要的部分。然而,目前還沒有哪個獨立的搜索引擎能夠覆蓋整個網絡,而且由于所采用機制、算法與適用范圍等的不同,導致同一搜索請求在不同搜索引擎中獲得的查詢結果的重復率不足34%,而每一個搜索引擎的查準率不到45%。因此,要想獲得一個比較全面、準確的結果,需要同時使用具有不同數據搜索范圍的搜索引擎,在多個檢索結果列表之中挑選對自己有用的內容,這就增加了檢索的不便。Web元搜索引擎的出現,在一定程度上解決了這些問題。Web元搜索引擎是集成多個搜索引擎的特殊搜索引擎。用戶輸入查詢后,系統將查詢詞發送給成員搜索引擎,各成員搜索引擎開始檢索。檢索完畢后,系統將各部分結果集合在一起,整理后采用一定的排序方式返回給用戶。將多個搜索引擎的查詢結果集合在一起,這樣可以擴大檢索面,提高查詢率。然而,面對如此海量的結果數據,系統本身就需要提供一套比較適用的排序算法,將用戶最想要的結果盡可能地展現在前幾頁。因此,排序算法是影響元搜索引擎性能的關鍵技術之一。
二、Web元搜索引擎搜索流程
Web元搜索引擎(簡稱元搜索)通過一個統一用戶界面幫助用戶在多個搜索引擎中選擇和利用合適的搜索引擎來實現檢索操作,是對分布于網絡的多種檢索工具的全局控制機制。其搜索流程如圖1所示。(圖1)可以看出,首先用戶通過一個統一界面輸入查詢詞,任務分配器將檢索詞分配給合適的多個獨立搜索引擎;各獨立搜索引擎接收到查詢詞后,立即進行相關文件查詢,并按照相關度高低順序將結果文件排列,然后反饋到結果集成中心;結果集成中心接收到給定的各獨立搜索引擎發回的結果文件序列后,就將按照一定的排序算法對所有結果文件匯總重新排序,最后輸出一個結果文件序列給用戶。這期間,針對不同的獨立搜索引擎將用戶的提問做不同轉換,以適應相應索引數據庫的調用;需要強調的是,元搜索是基于獨立搜索引擎結果的二次加工,元搜索引擎的結果基于獨立搜索引擎的查詢結果,少數簡單的直接調用原始的結果頁面,但這都實現了對獨立搜索引擎查詢結果的二次加工,如重復結果的刪除、結果的再度排序等。在定制結果輸出形式的元搜索引擎中,檢索結果一般都標明記錄的來源搜索引擎及其相關度。
三、Web元搜索引擎排序機制
Web元搜索引擎排序是指對其調用的多個成員搜索引擎所返回的結果進行收集、去重處理,然后按照一定的準則排序,最終將排序結果按一定順序展現給用戶的過程。由于調用的成員搜索引擎可以各式各樣,其收集的查詢結果組成也形式多樣,歸納起來其結果主要是由網址(URL)、網頁標題、內容摘要、相關度等信息組成。因此,元搜索引擎排序可以在利用成員搜索引擎排序的基礎上,從網頁標題、內容摘要等方面著手考慮。總的來說,其排序方法可以從以下三方面來闡述:
1、引用排列。指直接采用搜索引擎提交的結果順序,依次將不同來源的結果顯示出來。這種方式無需進行結果去重而只需完成格式轉換,因此顯得簡單易行,而且它有利于用戶了解哪些搜索引擎對自己所需的信息不能提供或提供很少,以后再查詢時可將它們從自己的引擎組合中刪除。但這種方式也很有可能致使一個搜索引擎的不相關結果排在另一個搜索引擎相關結果之前,使用戶錯過重要信息。
2、重新排列。這種排序的方法比較單一,相當于把成員搜索引擎搜索的結果融合到一起再重新選擇一種方法排序。這種方法僅僅提高了查全率,對于一些重要的信息,可能會排在比較靠后的位置而不易被用戶檢索到,準確率也不高。早期的元搜索引擎通常使用這種算法思想。基于此類算法思想的方法主要有直接合并、根據響應速度排序、摘要排序等。
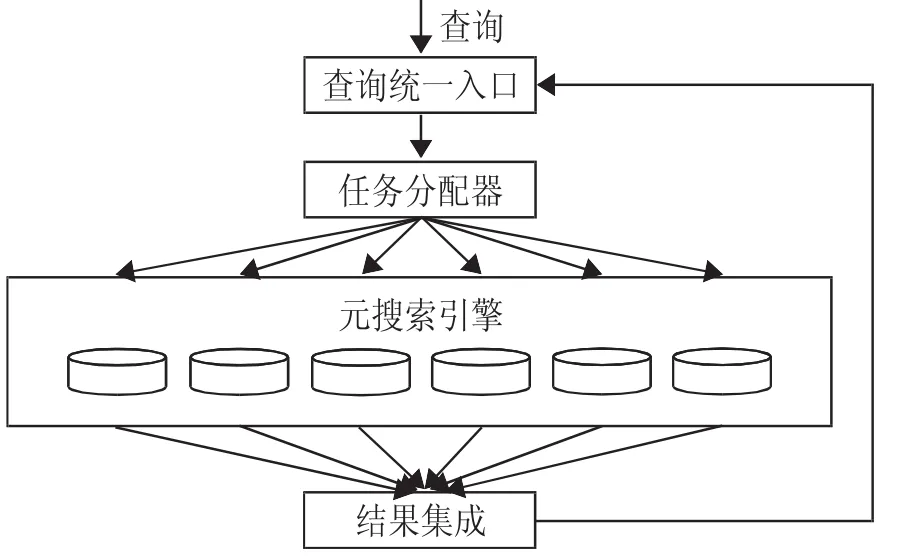
圖1 Web元搜索引擎搜索流程圖
3、利用搜索引擎排序信息排序。將各個成員搜索引擎所返回的結果集中在一起重新排序,這樣就打亂了原來搜索引擎的排序信息,而這些信息也是非常重要的排序依據。盡管有些成員搜索引擎的排序方法未知,但是它肯定是按查詢結果與查詢詞的相關程度大小排序的,只不過不同的搜索引擎所側重的因素不同。若是能充分利用各成員搜索引擎的排序信息,在其基礎上進一步地合成,則能夠將查準率進一步提高。輪詢法、星星排序、Borda排序、貝葉斯概率模型排序、位置排序等方法就是基于此基礎上的。
4、相關分值融合。相關分值融合也是充分利用各個成員搜索引擎的排序信息。針對某個查詢,各成員搜索引擎對自己搜索的所有結果均根據不同的情況分配一定的相關分值,對于同一結果在多個搜索引擎中出現的,將它們的相關分值進行融合后再排序。相關分值融合的方法有很多種,其中以Comb融合法(六種)、SDM融合法、MEM融合法、CORINET排序等最為常見。
四、Web元搜索引擎排序算法改進建議
鑒于目前元搜索引擎開發技術不同,且內部算法也存在重大差異,很難用統一的標準要求和衡量搜索結果的優劣。但對于元搜索引擎排序算法方面,其改進的方法主要體現在以下幾方面:
1、直接將兩種或者兩種以上的基礎算法進行綜合,這是比較常見的改進方法。摘要/位置排序法就是將摘要排序法和位置排序法綜合在一起的。元搜索引擎Ixquick、Metor等的結果排序方式都是基于相關度與星星評價指標相結合排序算法。
2、根據加權平均(簡稱WM)算法的原理,針對成員搜索引擎性能的不同分配一定權重,權重值與所引用的搜索引擎名稱、個數有關,這樣能夠突出成員搜索引擎之間的差異。加權輪詢法、加權規范分法、加權Comb排序等均是在基礎算法的基礎上為搜索引擎分配權值得到的。
3、依據信息集結算子的原理,首先確定所有成員搜索引擎搜索結果的文件序列;然后確定最終顯示的文件名稱和總個數,系統會按照確定的文件名稱和文件數統計各文件在每個序列位置出現的次數;接著系統按從大到小順序排列每個文件在序列中出現的次數;最后根據搜索引擎的個數和信息集結程度,運用信息集結算子計算每個位置的權重,權重和排序后(降序)的文件在序列中出現的次數相乘,得到最終集結結果,系統把每個文件最終的集結結果按從大到小順序排列,該順序即為元搜索引擎關于每個文件最終的順序。針對成員搜索引擎檢索的每個文件在序列中每個位置出現次數如何確定權重,目前國內外相關成熟的算法也比較多,如加權有序平均(OWA)算子、模糊語言量詞、尤其是規范單調遞增(RIM)量詞。
4、綜合2和3算法的原理,首先賦予每個元搜索引擎一定的權重,然后再對最終結果文件序列每個位置賦予一定的權重,當然這兩個權重值和算法各不相同。然后利用集結算子原理,計算每個文件在所有元搜索引擎中的最終集結值;再把檢索結果文件按集結值降序排列,該順序即為元搜索引擎關于每個文件最終的順序。針對這兩種權重的確定方法,目前國內外相關成熟的算法還不是很多,比較成功的算法有加權有序、加權平均(簡稱WOWA)算子。
此外,雖然目前排序算法眾多,但隨著新的搜索引擎的出現、搜索技術的改進及外界環境的變化,筆者認為還需要定期對元搜索引擎排序結果進行測評,主要指標包括查全率和查準率。對于查全率,由于元搜索引擎作為一種特殊的搜索引擎,對于一個固定的查詢,它的結果來自于成員搜索引擎。因此,整體查全率是由成員搜索引擎所確定的;而對于查準率,搜索引擎本身提供的排序算法就是將相關度較大的結果盡可能排在前面,即提高查準率,它是衡量元搜索引擎性能的一個重要尺度。因此,要想使用戶在最短的時間內檢索到最需要的文件信息,必須不斷優化元搜索引擎技術和元搜索引擎排序算法。
五、元搜索引擎排序算法展望
目前,搜索引擎技術逐漸趨于成熟階段,尤其是在查全率和查準率方面都有了較大的改進,時效性也有較大的改善。而元搜索引擎在國內尚處于起步階段,但其還是具有自己獨特的生存優勢的,因為它集合了多個搜索引擎,具有較高的查全率,這些都是其他搜索引擎不能具備的。但由于不同的搜索引擎在收集信息的數量、范圍、排序方法等方面有較大的差異,再加上搜索引擎技術的隱蔽性,設計者很難獲取它們的技術細節。對于元搜索引擎來說,無論采取哪種排序方式,總不盡如人意。實際上,對某元搜索引擎來說(排序方法已定),不同的查詢,它的查準率和查全率也有不同;對于同一個查詢,不同的排序方式也會引起很大的差別,導致這種問題的主要是信息重疊率的不同。Wu Sheng-li和McClean經過研究表明,當信息重疊率不同時,各種排序算法差異顯著。所以,要想從排序算法上提高元搜索引擎的查準率和查全率,除了對基礎算法進行改進外,還要根據不同的查詢選擇不同的算法。專業搜索引擎的出現對元搜索引擎來說可以是一個借鑒,即將專業搜索引擎綜合實現專業元搜索引擎;或者將元搜索引擎更進一步的智能化。針對用戶輸入的查詢串自動地進行分類,然后根據類別選擇最佳的排序方法。當然,對于某個固定的元搜索引擎,還可以通過科學的統計方法來檢測成員搜索引擎的技術細節,盡管檢測出來的技術細節不是很精確,但卻能夠在一定程度上反映出該成員搜索引擎的技術情況。綜合這些技術給出一個統一排序方法對所有結果進行重新排序,這樣勢必能夠提高用戶的滿意度。
[1]彭喜化,張林.基于agent的元搜索引擎結果優化技術 [J].計算機應用,2003.12.
[2]文坤梅,盧正鼎,鄧曦等.元搜索引擎中檢索結果排序的優化方法[J].華中科技大學學報,2003.3.
[3]徐寶文,張衛豐.搜索引擎與信息獲取[M].北京:清華大學出版社,2002.
[4]張強弓,喻國寶,廖湖聲等.一種元搜索引擎的查詢結果處理模型[J].華南理工大學學報(自然科學版),2004.32.Z1.
猜你喜歡
中學生數理化·七年級數學人教版(2022年11期)2022-02-14 07:14:12
科普童話·學霸日記(2020年1期)2020-05-08 16:45:11
小天使·一年級語數英綜合(2019年2期)2019-01-10 11:57:30
兒童繪本(2018年5期)2018-04-12 16:45:32
中華手工(2017年2期)2017-06-06 23:00:31
中國衛生(2015年12期)2015-11-10 05:13:38
中外會展(2014年4期)2014-11-27 07:46:46
新疆大學學報(自然科學版)(中英文)(2014年2期)2014-11-06 07:49:12
技術經濟與管理研究(2014年11期)2014-03-11 17:02:44
計算機應用文摘(2009年17期)2009-04-29 00:44:03
