基于Hadoop的海量電信數據云計算平臺研究
2012-03-12 05:16:46黎宏劍黃廣文
電信科學 2012年8期
黎宏劍,劉 恒,黃廣文,卜 立
(中國移動通信集團廣東有限公司中山分公司 中山 528403)
1 引言
隨著3G時代的來臨,移動業務日益豐富,用戶在使用移動業務過程中產生的各類數據以TB級速度增長。面對激烈的市場競爭,如何快捷、高效、安全地管理和分析海量的業務數據,深度挖掘業務特征,實行精確營銷策略,成為電信運營商確保競爭優勢的關鍵舉措之一。
目前,面對海量的業務數據,電信運營商存在管理和分析難的問題。業務數據的管理要求高效存儲、高效讀取、高可用性及高擴展性架構,業務數據每天以TB級速度增長,基于傳統關系型數據庫的數據管理難以滿足其要求,或需付出高昂的成本代價實現。對業務特征的挖掘分析,往往涉及網絡域和業務支撐域的大數據以及這些大數據之間的關聯。傳統的關系型數據庫對這些大數據的運算需要搭配高性能的機器,運算時間長,分析結果存在嚴重滯后性,直接導致錯過了對相應行為采取有效措施的最佳時機。
Hadoop分布式技術的發展為解決上述問題提供了技術手段。Hadoop是一個在集群上運行大型數據庫處理應用程序的開放式源代碼框架,采用MapReduce編程模型對海量數據進行有效分割和合理分配,以實現高效并行處理,并行程序編寫簡單,節省時間。Hadoop分布式云計算平臺對硬件配置要求不高,具有可伸縮性和高容錯性,實施成本低。本文在研究云計算和Hadoop的基礎上,設計并部分實現了基于Hadoop的海量電信數據云計算平臺。
2 相關技術簡介
2.1 云計算
云計算基于互聯網相關服務的增加、使用和交付模式,是并行計算、分布式計算、網格計算綜合發展的結果。它將計算任務分布在大量計算機構成的資源池上,使各種應用系統能夠根據需要獲取計算力、存儲空間和信息服務,具有數據安全可靠、可共享、擴展性強、規模大、價格低廉等特點。按照提供服務的不同,云計算分為SaaS(software as a service,軟件即服務)、PaaS(platform as a service,平 臺 即 服務)和 IaaS(infrastructure as a service,基礎設施即服務)3類。云計算以數據為中心,在并行數據處理、編程模式和虛擬化等方面具有獨特的技術。
2.2 Hadoop
Hadoop是由Apache基金會組織開發的分布式計算開源框架,利用低廉設備搭建大計算池,以提高分析海量數據的速度和效率,是低成本的云計算解決方案。其模仿和實現了Google云計算的主要技術,包括HDFS(Hadoop distributed file system,Hadoop 分布式文件系統)、MapReduce、HBase、ZooKeeper等,分別對應于Google成熟商用云計算平臺的GFS(Googlefilesystem,Google文件系統)、MapReduce、BigTable、Chubby,支持通過 Google的MapReduce編程范例創建并執行應用程序。
Hadoop是相關子項目的集合,核心是Hadoop Common、HDFS和MapReduce,其他子項目提供補充性服務。Hadoop技術棧如圖1所示,具體介紹如下。
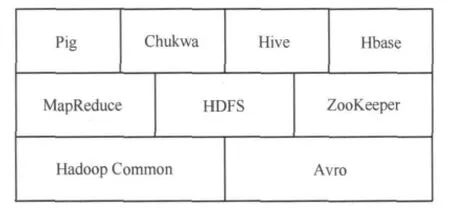
圖1 Hadoop技術棧
Hadoop Common:支撐Hadoop的公共部分,是最底層的模塊,為其他子項目提供各種工具。
HDFS:是一個主從 (master/slave)結構,由一個NameNode(名稱節點)和若干個 DataNode(數據節點)構成,NameNode管理文件系統的元數據,DataNode存儲實際數據。
MapReduce:處理海量數據的并行編程模型和計算框架,采用“分而治之”思想,包括分解任務的map函數和匯總結果的reduce函數,MapReduce任務由一個JobTracker和若干個TaskTracker控制完成,JobTracker負責調度和管理TaskTracker,TaskTracker負責執行任務。
Pig:SQL-like語言,是在MapReduce上構建的一種高級查詢語言,以簡化MapReduce任務的開發。
Hive:數據倉庫工具,提供SQL查詢功能。
Hbase:基于列存儲模型的分布式數據庫。
ZooKeeper:針對分布式系統的協調服務。
Chukwa:分布式數據收集和分析系統。
Avro:提供高效、跨語言RPC的數據序列系統,持久化數據存儲。
Hadoop具有可擴展、高容錯、經濟、可靠、高效的優點,被廣泛應用在云計算領域,在Yahoo、Facebook、支付寶、人人網等大型網站上都已經得到了應用,是目前應用最為廣泛、成熟的開源云計算平臺。
3 基于Hadoop的海量電信數據云計算平臺設計
目前,電信運營商對海量電信數據的分析都是基于傳統的關系型數據庫,這種分析方法依賴于高性能機器,分析時間長、效率不高,直接影響了業務決策時機。
針對這些問題,結合海量電信數據的特點,本文提出利用Hadoop云計算技術對海量電信數據進行分析的方法,該方法通過構建基于Hadoop的海量電信數據云計算平臺,采用MapReduce編程模型加強對數據的管理,提高數據分析的速度和效率,解決了電信運營商對海量電信數據管理和分析難的問題。
3.1 平臺設計的目標與原則
海量電信數據云計算平臺的設計目標是利用Hadoop基于低廉設備的海量數據處理優勢,利用一批下線的低端PC服務器搭建Hadoop云計算平臺,支撐海量電信數據的分析需求,提高數據分析的速度和效率,達到為業務決策提供即時、準確信息的目的,同時為公司節約投資成本。
平臺的設計原則包括:經濟原則,充分利用現有資源搭建平臺基礎設施,根據Hadoop對硬件要求不高的特點,采用一批下線低端PC服務器搭建Hadoop集群;高效原則,充分利用云計算平臺的特性,提高海量電信數據的處理效率;安全原則,在平臺設計過程中,必須充分考慮平臺的自身安全和信息安全,采取必要措施,規避安全風險。
3.2 平臺框架結構
結合海量電信數據自身的特點,海量電信數據云計算平臺在設計上采用分布式、分層結構,可以劃分為數據層、模型層、應用層3層結構,如圖2所示。
(1)數據層
海量電信數據包括網絡域數據和業務支撐域數據。其中,網絡域數據包括Gb口數據、A口數據、WLAN數據等;業務支持域數據包括客戶信息、客戶業務訂購數據、客戶消費數據等客戶基本數據。數據層通過Hadoop的HDFS存儲這些數據,然后利用 Hbase、Hive、Pig、ZooKeeper等數據處理和管理工具,用類SQL語言定義統計指標,動態生成MapReduce任務進行計算和聚合,對海量電信數據進行高效處理,處理結果仍以文件格式存儲在HDFS中,并可導出為所需格式。
客戶會上,美豐加藍同與會客戶探討了市場情況、生產技術、售后服務等方面內容。今年,美豐加藍創新設置了“推廣之星”“潛力之星”和“銷量之星”等三個獎項,對在合作過程中表現突出的優秀客戶進行表彰獎勵。
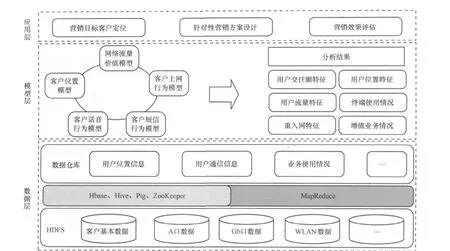
圖2 海量電信數據云計算平臺框架結構
(2)模型層
模型層利用數據層對海量電信數據進行基于Hadoop的ETL處理輸出的匯總數據,建立分析模型,如客戶位置模型、客戶上網行為模型、客戶短信行為模型、客戶話音行為模型等基礎模型,實現客戶位置、客戶離網預警、客戶交往圈等分析應用。
(3)應用層
應用層是利用模型分析得出的結果,如生活軌跡特征、增值業務使用情況、用戶的交往圈特征等,精確定位營銷目標客戶,設計針對性營銷方案,并對營銷效果進行評估分析。
3.3 平臺功能模塊
海量電信數據云計算平臺的功能模塊包括用戶管理、數據管理、任務管理、集群管理4個模塊,如圖3所示。
·用戶管理模塊:包括賬號開通、身份認證、權限管理、交互控制。
·數據管理模塊:包括數據的上傳和下載、刪除。
·任務管理模塊:包括任務申請、資源申請、結果反饋。
·集群管理模塊:包括Hadoop集群狀態和任務進度、節點管理。
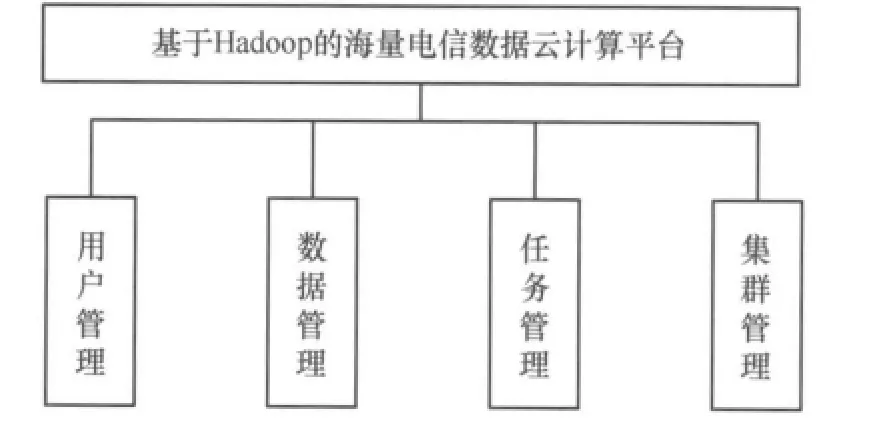
圖3 海量電信數據云計算平臺的功能模塊
3.4 網絡拓撲結構
Hadoop集群局域網由 1臺 NameNode服務器、1臺Secondary NameNode服務器、1臺JobTracker服務器和多臺從服務器組成。
·NameNode服務器負責管理海量數據文件的分割、存儲以及監控DataNode的運行情況。應用程序需要讀取數據文件,首先訪問NameNode服務器,獲取數據文件在各DataNode上的分布,然后直接與DataNode通信。一旦發現某個DataNode宕機,NameNode將通知應用程序訪問宕機節點各數據塊的副本,并在其他DataNode上增加宕機節點各數據塊的副本,以保證平臺的可靠運行。
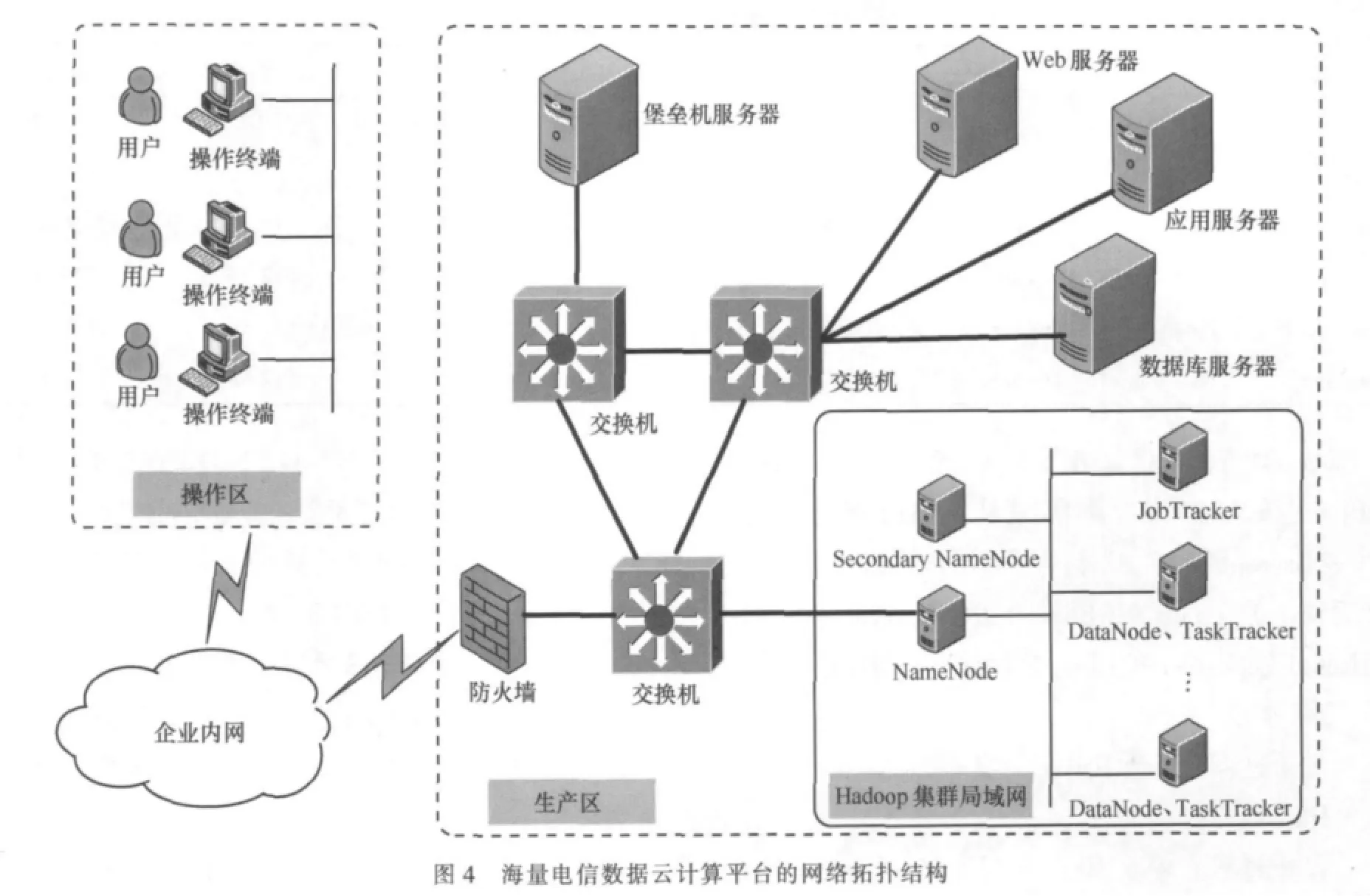
·Secondary NameNode服務器用來監控HDFS狀態,與NameNode進行通信,以便定期保存HDFS元數據的快照,若NameNode發生問題,其作為備用NameNode使用。
·JobTracker服務器負責管理計算任務的分解和匯總,負責監控各TaskTracker節點的運行情況,一旦某個任務失敗,JobTracker自動重新啟動這個任務。
·從服務器承擔了DataNode和TaskTracker兩種角色,分別負責數據塊的存儲和數據計算的map、reduce任務的運行。
3.5 平臺安全機制
由于Hadoop集群節點之間是互通的,對Hadoop集群節點操作的賬號是統一的,同時電信數據屬于敏感數據,Hadoop本身的機制難以對數據進行有效的安全控制,在一定程度上存在安全問題。為規避安全風險,防范安全事故的發生,必須采取相應的安全機制加強對平臺和數據的安全管理。平臺采取的安全機制包括平臺自身安全管理、賬號安全管理和數據安全管理。
(1)平臺自身安全管理
將Hadoop集群網絡劃分為內部局域網,通過設置防火墻策略與其他網絡進行隔離,NameNode作為唯一出口負責與外部進行通信,內部其他節點通過NameNode進行訪問。同時,將NameNode加入堡壘機,將其操作的任何記錄均保存在堡壘機服務器中。
(2)賬號安全管理
嚴格控制平臺管理員賬號,定期更換口令;將操作Hadoop集群的賬號和用于數據傳輸的賬號分離,嚴格控制其訪問權限;保存各賬號的操作記錄,定期審計。
(3)數據安全管理
電信數據屬于敏感數據,必須加強敏感數據的保密工作,主要通過記錄數據進出、分開存放、傳輸加密和記錄人員對數據的操作、定期審計等措施,對數據進行安全管理。
4 平臺的部分實現及其效果
由于時間和精力有限,本文僅對海量電信數據云計算平臺的底層Hadoop集群部署進行實現,并通過實驗論證本文提出的方法及設計平臺的有效性、可行性。
4.1 底層Hadoop集群部署的實現
底層 Hadoop集群包括 1個 NameNode服務器、1個JobTracker服務器和4個DataNode服務器,設備配置信息見表 1。
底層Hadoop集群采用Hadoop-0.20.2版本,操作系統為Linux CentOS 5.6,Hadoop運行需要JDK環境,本文選擇的是jdk1.6.0_31。
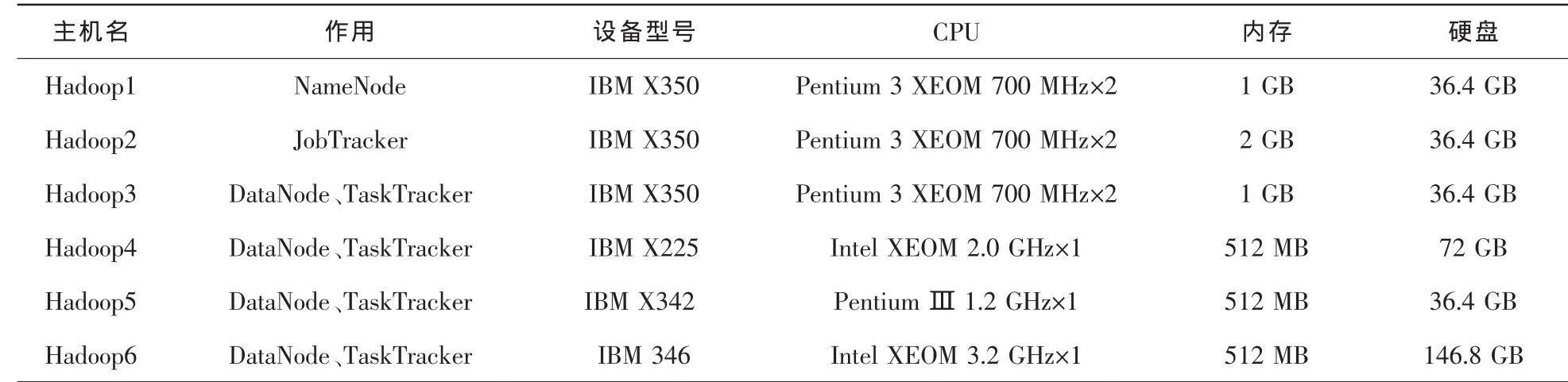
表1 集群設備配置信息
Hadoop的安裝過程為:配置host文件、新建Hadoop目錄和用戶、安裝JDK及配置環境變量、配置SSH免密碼登錄、安裝Hadoop及配置。此外,為了增強平臺的擴展性,分別安裝了 Hive-0.8.1、Pig-0.9.2、Hbase-0.20.6、Zookeeper-3.3.3。其中,Hadoop、ZooKeeper和Hbase之間的啟動和停止有順序要求,介紹如下。
·啟動過程:啟動Hadoop→啟動 ZooKeeper→啟動Hbase。
·停止過程:停止Hbase→停止ZooKeeper→停止Hadoop。
4.2 實驗結果
在部署好的平臺中進行相關實驗,驗證本文提出的基于Hadoop的分布式云計算方法在海量電信數據分析方面是否存在優勢。
在分布式和非分布式環境下,計算全網客戶的位置信息,主要字段為:IMSI、CGI、時長、時間切片標識。實驗數據為網分A口數據文件,包括話音數據call_20120316.txt(2.2 GB)、短信數據 SMS_20120316.txt(600 MB)和位置數據location_20120316.txt(3.3 GB)。實驗的前提條件是假設各實驗采用的機器設備在配置上都是相同的。
實驗一:采用非分布式計算(Oracle數據庫),在Oracle環境下的計算時長大約為4 h。
實驗二:采用分布式計算,利用單數據節點進行MapReduce計算,Hadoop配置信息為 1個 NameNode、1個JobTracker和1個DataNode。運行日志如圖5所示,運行時長大約為63 min。
實驗三:采用分布式計算,利用兩個數據節點進行MapReduce計算,Hadoop配置信息為 1個 NameNode、1個JobTracker和2個DataNode。運行日志如圖6所示,運行時長大約為37 min。
通過對比實驗一和實驗二的運算結果得出,在大運算量上,利用Hadoop分布式計算可以大大提高計算速度和效率,本次實驗縮短了3 h以上;通過對比實驗二和實驗三的運算結果得出,Hadoop的數據節點數影響到Hadoop的整體性能,本次實驗采用2個數據節點比1個數據節點的運算時間快了近1倍。

圖5 實驗二的MapReduce計算過程

圖6 實驗三的MapReduce計算過程
可以看出,與傳統的數據分析方法相比,本文提出的針對海量電信數據的分布式云計算方法,即基于Hadoop的海量電信數據云計算平臺,有效地提高了海量數據分析的速度和效率。
5 結束語
本文針對傳統數據分析方法面對海量電信數據存在分析效率不高的問題,提出了基于Hadoop的分布式云計算方法,設計了基于Hadoop的海量電信數據云計算平臺,并對平臺的部分功能進行了實現。實驗表明,本文提出的方法是有效和可行的,為進一步研究Hadoop在海量電信數據分析方面的應用做出了指引,在下一步的研究中,重點討論MapReduce編程模型改進和數據節點的擴展問題,以進一步提高海量數據的運算效率。
1 Wbite T.Hadoop:the Definitive Guide.O’Reillly Media,Inc.,2009
2 張建勛,古志民,鄭超.云計算研究進展綜述.計算機應用研究,2010,27(2):429~433
3 施巖.云計算研究及Hadoop應用程序的開發與測試.北京郵電大學碩士學位論文,2011
4 Hadoop官方網站.http://hadoop.apache.org,2012
5 劉鵬,黃宜華,陳衛衛.實戰Hadoop——開啟通向云計算的捷徑.北京:電子工業出版社,2011
猜你喜歡
小獼猴智力畫刊(2022年9期)2022-11-04 02:31:42
今日農業(2022年15期)2022-09-20 06:56:20
中學生數理化·中考版(2022年11期)2022-02-16 07:01:20
小哥白尼(趣味科學)(2019年6期)2019-10-10 01:01:50
建材發展導向(2019年10期)2019-08-24 06:26:30
建材發展導向(2019年10期)2019-08-24 06:26:20
發明與創新(2016年38期)2016-08-22 03:02:52
太空探索(2016年5期)2016-07-12 15:17:55
雜文月刊(2016年1期)2016-02-11 10:35:51
現代企業(2015年8期)2015-02-28 18:54:47
