Winpcap的體系結構與性能研究*
2012-02-28 05:10:52楊虹,陳威
網絡安全與數據管理 2012年9期
楊 虹,陳 威
(重慶郵電大學,重慶 400065)
網絡分析軟件通常依賴底層調用抓取數據包,進行數據包監視或流量分析等。大多數的Unix系統都提供這些功能(至少是數據包抓取),而Windows提供的這些功能卻不令人滿意。Windows提供了一些與各種內核組件相關的API,但這些API存在嚴重的缺陷,如并不是所有的Netmon API都可用,而且其擴展存在很多限制。IP過濾驅動程序(IP filterdriver)只存在 Windows 2000及以上系統中,而且它只支持IP協議,雖然它能夠控制和丟棄數據包但卻不能監測和構造數據包。PCAUSA提供了一個商業產品,該產品含有數據包捕獲和BPF兼容的過濾器,然而它的用戶接口處于底層且沒有提供過濾器構造這樣的抽象方法。隨著原本在Unix系統上的應用不斷轉向Windows系統,這些特性的缺失成了不可忽視的問題。
本文主要介紹一個強大可擴展的Win32平臺的網絡監聽框架系統Winpcap的結構及其功能。該體系結構填補了Unix和Windows間網絡監聽能力的間隔,使得Unix應用到Windows的移植更簡單,而且Winpcap把性能放在最首位,使其能滿足更苛刻的需求。
1 Winpcap的體系結構
Winpcap的基本結構如圖1所示,由1個過濾引擎、2個緩沖區(內核層與用戶層)以及一系列供開發人員使用的組件庫組成。盡管Libpcap具有穩固的結構并且功能強大,但Winpcap在結構和數據捕獲上仍然有自己獨到的地方,而且甚至可以認為是對Libpcap的創新。
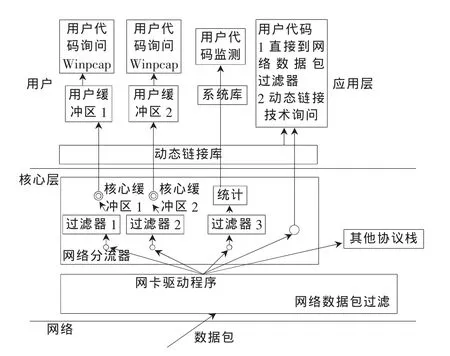
圖1 Winpacp的體系結構
Winpcap的過濾可從用戶層開始(與Libpcap兼容),開發人員可以自定義包過濾條件 (如picks up all udp packets);Winpcap會把它們編譯成一些虛擬指令 (如 if the packet is ip and the protocol type field is equal to 17,then return true),同時把這些虛擬指令發送到過濾引擎,并且激活這些功能。要實現這些目的,內核模塊必須能夠執行指令,因此需要一個“虛擬BPF”用來在每個接收的數據包執行這些虛擬代碼。其中內核層的過濾引擎是獲得高性能的關鍵。
NPF與BPF在體系上最大的不同是對循環緩沖區的使用選擇[1]。Winpcap每次復制一部分數據包,Winpcap的緩沖區不再是固定大小 (Libpcap的內核緩沖區與用戶緩沖區都是32 KB),而且在將數據包從內核緩沖區復制到用戶緩沖區的過程中對數據包進行更新,而不是復制完后更新。在復制過程中,將已經傳送的數據包所占用的空間立即釋放,因為盡管Winpcap工作在較高的優先級并且可能一直壟斷CPU,但內核層的捕獲程序可能會中斷復制過程。只要交換緩沖區允許占用一般的內存,Winpcap的緩沖區就可以存放大量的數據包。
內核緩沖區僅通過一個read函數就可以完全復制,這可以減少大量的系統調用并且避免程序在內核層與用戶層之間頻繁切換。因為環境的切換之前必須保存任務狀態(CPU描述符與任務狀態大約有幾百個字節),頻繁切換會導致CPU使用率下降。
Winpcap的內核緩沖區比 BPF的要大(為 1 MB),因為較小的內核緩存也會帶來一些問題,特別是當程序無法與捕獲數據包的驅動程序的速度保持一致情況下,這種情況在將數據發往硬盤或網絡數據量激增的情況下很常見。相反,用戶緩沖區需要小一些,通常情況下為256 KB。內核緩沖區與用戶緩沖區都可以在運行時調整。
用戶緩沖區的大小至關重要,因為它決定了僅通過一個調用最多可以從內核讀多少數據,同時,一次從內核中至少應該讀多少數據也很重要。如果給出一個較大的值,則內核可以在數據送往用戶緩沖區之前等待足夠多的數據包到達,這可以減少一些系統調用。如果給出一個較小的值,則意味著內核可以將數據包盡快送往用戶緩存。這對那些實時性要求比較高的應用來說很重要,一個好的捕獲引擎會在兩者之間做出好的平衡。NPF是可配置的,讓用戶選擇程序具有好的執行效率或快速的反應。而Winpcap提供了一組函數可以設置數據包讀延時和數據包拷貝的最小值。當讀延時或內核緩沖區獲得的數據包數據量滿足了最小值,數據都會被送往用戶緩沖區。延時默認設置為1 s,最小數據量設置為16 KB,這種功能被稱之為“延遲寫入”。
1.1 統計模式
包捕獲與網絡分析會過多占用CPU,因為有大量的數據需要處理和拷貝。提高執行速度最常用的方法是提高過濾引擎的速度與一次拷貝結構,這種方法是通過將內核緩沖區映射到程序內存來實現。一次拷貝的操作會減少數據的拷貝,但并不會減少內核層與用戶層之間的系統調用。如果用戶一次讀一個數據包,環境切換的代價會抵消一次拷貝所帶來的好處。
一種新的方法是監視時并不將數據包送往用戶層,而是Winpcap將監視的功能放在內核層,這樣就可以避免數據送往用戶層。Winpcap提供了一種嵌入在NPF過濾引擎中的可編程的統計模式,可以使過濾器成為強大的分類器而不僅僅是過濾器。應用程序可以使用這個模塊監視任意的網絡行為(如網絡下載、兩臺主機間的網絡流量、每秒鐘的網頁訪問數量),并且可以在預先設定的時間間隔獲得這些結果。
統計模式避免了數據拷貝,并且實行0拷貝模式(統計行為在數據包到達網卡驅動的存儲區時執行,之后數據包被丟棄),所以不需要緩沖區。統計模式是監視網絡的一種極為有效的方法,且能在高速網絡中表現出良好的性能。
Winpcap為開發人員提供了一組高層調用可以很容易地使用統計模式,對那些習慣了Libpcap的開發人員來說很容易掌握。
1.2 數據包注入
BPF與NPF都提供了直接發送原始包的功能,可以將數據包直接發送到網絡中。但是Libpcap并沒有使用這些調用,而BPF也并不是用于此目的。大多數Unix系統都提供了直接發送原始包的功能,而Windows只有2000才提供了此功能,且功能受限。因此,Winpcap是Win32平臺上第一標準的而且可靠的發送原始包的類庫。NPF提供了許多新的函數可以發送多個數據包而只在內核層與用戶層之間切換一次。
Winpcap雖然提供了很多函數可以去開發這些新的功能(但并沒有直接提供這些功能),它需要開發人員手工構造數據包或利用已有的工具。而用戶可以使用Libnet Packet Assembly Library(即在 Winpcap上加了一層功能),就可以構造數據包并發送到網絡中。
2 性能分析
主要是對Winpcap的性能進行測試,用Winpcap在Windows98與Windows2000下的表現與Libpcap/BPF在FreeBSD下的表現進行比較。
圖2為兩臺主機直接相連,以排除外部數據包的干擾,使實驗結果更精確。一臺主機是Windows2000操作系統,使用基于Winpcap的工具產生大量的數據包發送到網絡中,并保證高速率。數據包的大小選擇,是以保證每秒所產生的數據包都能夠達到一個極限值。

圖2 測試中使用測試平臺
操作系統安裝在同一臺主機上的不同硬盤分區上,以避免由于硬件原因帶來的差異。數據包被發送到不同的主機上,這樣可以使兩臺主機之間不用進行交互。接收端的主機網卡設置為混雜模式,根據測試主題的不同而用不同的工具捕獲數據包。根據測試需要,數據包收到后或丟棄、或傳送給應用程序、或存儲在硬盤中。
FreeBSD的CPU負載可以在TOP PROGRAM查看,Windows2000可以通過任務管理器查看,Windows98則可以用CPUMETER查看(可以從網上獲得)。
被測試的軟件都是最新的發行版,Winpcap的內核緩沖區為1 MB,Libpcap的緩沖區被設置為2個512 KB大小的空間(默認為32 KB)。
這些實驗將努力避免其他軟件對實驗結果的影響,但是結果并不能準確地表現出單獨組件的性能,因為不同的組件不交互基本上是不可能的。
2.1 發送實驗
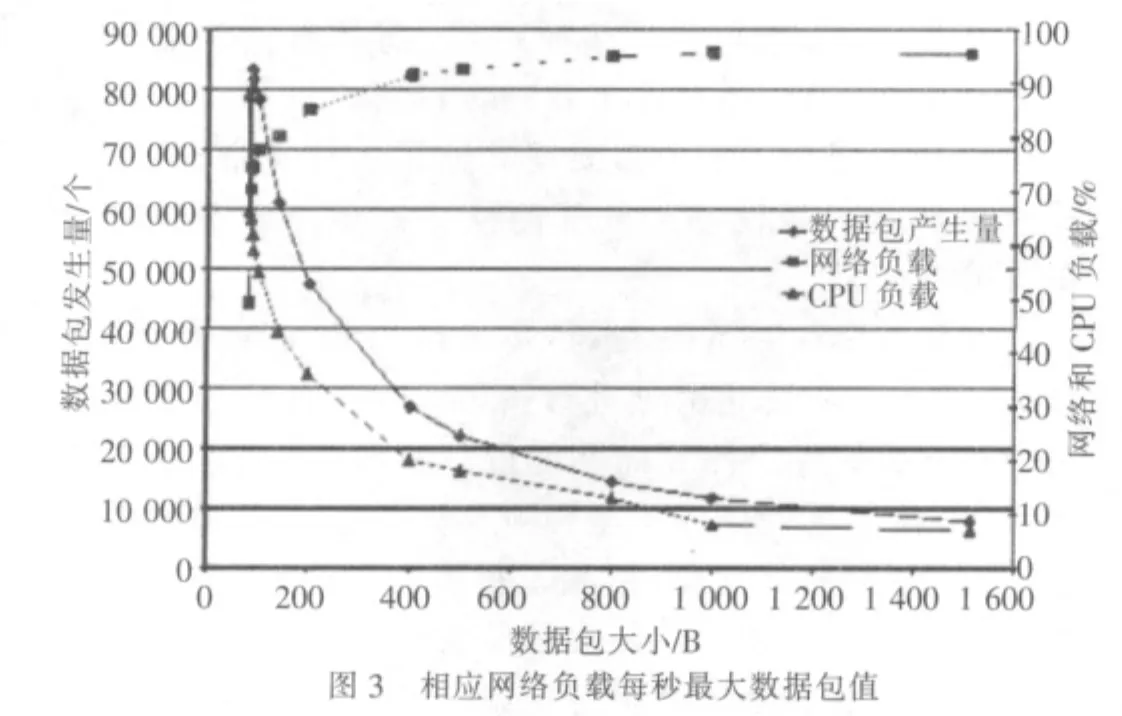
發送實驗是測試發送性能,只在Windows2000下進行(95/98沒有對這個功能做優化)。圖3顯示了當每個包都為88 B的情況下達到每秒發送的最大值 (原認為在每個包為64 B的情況下會達到最大值),這出乎意料。因為測試并不依賴NPF,CPU的負載始終沒有達到100%,這也說明了NPF并不是瓶頸所在。當數據包為400 B時網絡達到全速。
經實驗發現發送能力更多依賴于網卡,當更換網卡、并在相同情況下進行測試時,發送速度只能達到每秒30 000個包。
2.2 接收與過濾實驗
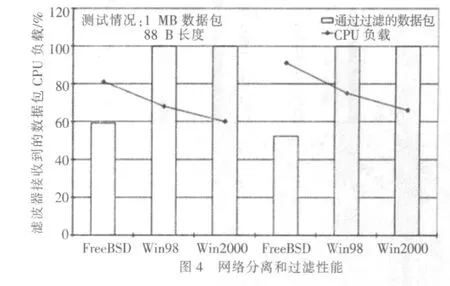
接收與過濾能力實驗測試:數據包被網絡接口接收并被過濾器檢查,如果所有的包都不會滿足過濾條件,它們將在檢查后被丟棄(不會被拷貝)。
測試在兩種情況下進行:第一種使用3條BPF虛擬指令;第二種使用13條復雜的BPF虛擬指令。
圖4為網絡分離和過濾性能,幾乎所有的包都被接受并沒有被過濾器檢查。Windows98的CPU負載明顯高于Windows2000(但是也在可以接受的范圍內)FreeBSD表現很差,只捕獲大約一半的數據包,而且CPU負載始終較高。
2.3 向應用程序傳送數據包的測試
測試應用程序從Winpcap接收數據包的能力 (收到后直接丟棄,并不做進一步的處理),檢驗整個Winpcap體系的功能,包括數據從網卡復制到內核緩沖區再到用戶緩沖區,而且將不使用過濾功能。圖5為測試結果,Winpcap幾乎可以將所有從網絡接口獲得的數據全部送至應用程序,沒有數據包在內核緩沖區被丟棄。而FreeBSD并不能做到這些,特別是在高數據率的情況下,大部分的數據包在沒有到達過濾器之前已被丟棄。
無論在Windows2000還是FreeBSD中,CPU的負載都隨著數據包容量的增大而降低,Windows98因為沒有延遲寫入的能力而表現一般。

2.4 程序性能實驗
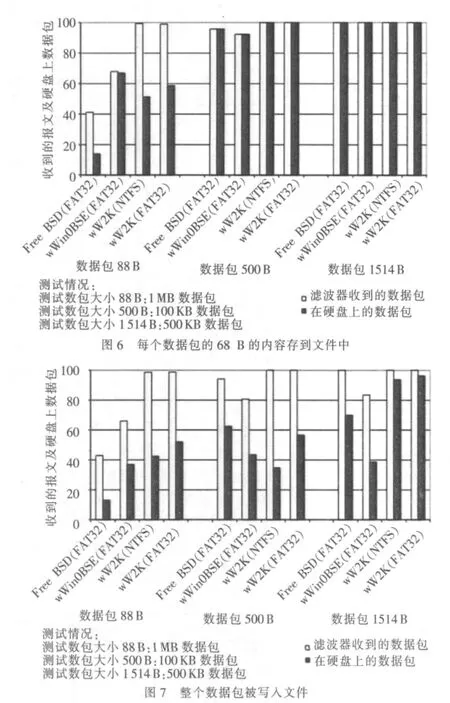
實驗將使用基于Winpcap的工具將獲得的數據包轉存在文件中,結果如圖6所示。程序將每個數據包的68 B的內容存到文件中。所有的系統在高數據率的情況下都會丟失一些數據包:一部分是因為恪守CPU時間(當一個數據包到達時,程序卻還在處理前面的包);另一部分則因為內核緩沖區沒有足夠的空間去存放數據包。圖7為整個數據包被寫入文件時的結果。
監視實驗在AD-HOC網絡上進行。實驗結果表明CPU負載一直維持在較低的水平,而且結果與圖4相類似。圖5顯示了在用戶層監視的代價遠高于內核層,這些多余的代價會給用戶層監視的性能帶來折扣。另外,用戶層的監視需要大容量的緩沖區。
3 Winpcap的改進意見
根據實驗結果與體系結構的特點,采取了如下相應的改進措施:
3.1 過濾引擎改進
因為采用動態代碼生成技術對BPF進行改進,使BPF性能取得明顯效果,因此對NPF也進行了類似的改進,采用 JIT(Just In Time)技術,將過濾代碼翻譯成X86的二進制代碼,這項改進使整體的捕獲性能提高了約8%。
3.2 內存拷貝
因數據包從網卡到程序需要進行兩次拷貝過程,而第一次拷貝(從網卡到內核緩沖區)的代價明顯高于第二次拷貝,一個重要的原因是 NdisTransferData()函數進行了額外的操作。但是同時,在研究過程中也注意到一些網絡控制器(尤其是一些大型的網絡適配器)是在通知網卡驅動之前將數據包拷貝到內存中的,因此NPF驅動可以在同一內存區接收數據包。在這種情況下,可以使用C標準庫的函數來實現這個功能。
3.3 時間戳
用于產生微妙級精確度時間戳的KeQueryPerformanceCounter函數可以被Inter處理器中集成的 TSC(Time Stamp Counter)取代,TSC的精度與 CPU頻率相同。X86的指令集提供了一條指令來取得時間戳(rdtsc),這項改進可以使整體性能提升27%左右。但是標準的NPF發現版并沒有使用這項改進,因為這項指令需要硬件支持 (只在Inter處理器或與Inter處理器兼容的處理器上才能運行)[2]。
3.4 Tap函數優化
Tap函數中同樣用到了 NdisTransferData()函數,而該函數運行時要求分配一塊存儲區去使某個數據結構可以用來存放要傳送的數據包,這個操作在數據包傳送完畢時可能會導致回調函數的調用中斷。同樣也可以用C標準庫的函數替代它。這項改進可以使整體性能提升5%左右。
3.5 硬件優化
由于很多開銷是在捕獲過程之外產生的,這就存在硬件優化的可能性,如NEW ZEALAND BASED公司推出有專用于網絡捕獲的芯片。該芯片避免了過多地與操作系統的交互,它可以產生時間戳,而且直接將數據包傳送到系統內存,用硬件來管理緩沖區。這樣應用程序可以直接取得數據而不需要同其他層次打交道。因此,硬件的優化可以使基于軟件的捕獲程序性能得到較大的提升。
本文主要針對Winpcap的體系結構及其性能進行研究,并對可能的優化措施進行探討。文中的實驗主要是對Winpcap的各個部分的性能進行測試,與一般的看法不同,過濾和緩沖區并不是影響整體性能的最重要的部分。對這兩部分的優化,引起了很多的關注,但是針對它們的改進相對整體的性能提升并沒有明顯的幫助,特別是在數據包比較小的情況下。經一系列實驗說明,真正的瓶頸在那些隱藏的地方,如設備驅動程序、應用程序與操作系統的交互、操作系統與硬件之間的交互。
數據捕獲是由很多組件配合完成的工作。所以,在對其性能進行優化這個問題上,要從全局考慮,而不應該僅僅局限在某個組件。實驗說明了一些大量優化操作都集中在沒什么提升潛力的地方(如過濾引擎和緩沖區優化),而真正值得關注的地方卻并沒有引起足夠的重視。同時,即使所有涉及到的技術都很成熟,但性能提升還是有很大的空間,希望本文能給同行提供一些新的視角。
[1]DEGIOANNI L, BALDI M, RISSO F, et al.Profiling and optimization of software-based network-analysis applications proceedings[C]. The 15thIEEE Symposium on Computer Architecture and High Performance Computing (SBAC-PAD 2003) Sao Paulo, Brazil, November 2003:3-5.
[2]RISSO F,DEGIOANNI L.An architecture for high performance network analysis[C].Proceedings of the 6th IEEE Symposium on Computers and Communications (ISCC 2001), Hammamet,Tunisia, July 2001:2-7.
猜你喜歡
中華詩詞(2022年6期)2022-12-31 06:41:24
小獼猴智力畫刊(2022年9期)2022-11-04 02:31:42
小哥白尼(趣味科學)(2019年6期)2019-10-10 01:01:50
中國科技論壇(2017年7期)2017-07-25 08:49:53
商用汽車(2016年11期)2016-12-19 01:20:16
發明與創新(2016年38期)2016-08-22 03:02:52
太空探索(2016年5期)2016-07-12 15:17:55
商用汽車(2016年6期)2016-06-29 09:18:54
商用汽車(2016年4期)2016-05-09 01:23:12
創業家(2015年5期)2015-02-27 07:53:25
