即插即用的分布式云端視頻處理系統(tǒng)
2012-01-25 07:52:42劉智慧苗耀鋒
制造業(yè)自動化 2012年12期
劉智慧,周 媛,苗耀鋒
(西安外事學(xué)院 現(xiàn)代教育技術(shù)中心,西安 710077)
0 引言
近年來,數(shù)字監(jiān)控設(shè)備的普及使得所需儲存的數(shù)字視頻內(nèi)容大量增加,從這些視頻內(nèi)容中分析取得重要的信息與事件將依賴于視頻處理的技術(shù):人臉識別、車牌識別、對象檢索及移動檢測等技術(shù)。由于視頻處理運(yùn)算的復(fù)雜度是相當(dāng)高的,有此需求的個人、商家、公司或政府等單位,都要花費(fèi)很大的成本去購置高性能的設(shè)備來進(jìn)行復(fù)雜視頻處理運(yùn)算。而云計算平臺具有并行化運(yùn)算及集中式資源共享的特性,剛好可以解決這樣的問題[1]。如何將視頻處理模塊進(jìn)行云端化的架構(gòu)及流程即是本文探討的主要問題。
1 分布式視頻處理系統(tǒng)架構(gòu)
1.1 視頻處理云端化的可行方案
要將視頻處理模塊功能整合到云端平臺中,可采用下列三種方式:1)視頻處理模塊直接執(zhí)行:等同于在單臺個人計算機(jī)執(zhí)行一支視頻處理程序,無法有效利用云端資源。2)替原本的視頻處理模塊,重寫工作分配程序:在租賃的多臺虛擬主機(jī)上,自行重寫Client/Server程序及負(fù)載平衡機(jī)制,來分派視頻處理工作到這些主機(jī)上,并以Socket方式進(jìn)行虛擬主機(jī)間的溝通。3)使用某種PaaS的平臺,利用它提供的框架,修改視頻處理算法:例如使用Hadoop,利用Hadoop提供的應(yīng)用程序開發(fā)接口,采用如Java/C/C++語言修改既有的視頻處理模塊,以實(shí)作Hadoop的MapReduce機(jī)制。

圖1 云端視頻處理平臺的系統(tǒng)架構(gòu)與運(yùn)行流程
1.2 系統(tǒng)架構(gòu)
本論文以Hadoop并行化架構(gòu)為基礎(chǔ),著重PaaS層的中介平臺開發(fā),開發(fā)一套云端視頻處理平臺來作為視頻處理與云端平臺的媒介。
我們提出的平臺架構(gòu)及其運(yùn)作流程如圖1所示,系統(tǒng)的前端用戶接口采用GWT工具[2]所開發(fā),是一個網(wǎng)絡(luò)桌面系統(tǒng)。系統(tǒng)主要包含三個功能:1)Web Server;2)Hadoop;3)VA Server。Web Server服務(wù)器端程序采用GWT工具開發(fā),主要將前端用戶所傳來的視頻分析要求和參數(shù)轉(zhuǎn)送給Hadoop系統(tǒng)。Hadoop系統(tǒng)主要分為二個部份,第一部份是MapReduce,主要是處理分布式并行運(yùn)算;第二個部份是HDFS,用來進(jìn)行分布式儲存和備份系統(tǒng)的數(shù)據(jù)及分析結(jié)果。VA Server安裝有多種視頻處理模塊VA-1,VA-2,…,VA-N,當(dāng)它接收到VA Client所傳送過來的task時,會利用VA loader加載需要的視頻處理模塊,然后由Processor模塊進(jìn)行分析,再將分析的結(jié)果回傳給VA Client,然后由VA Client直接將分析結(jié)果寫入HDFS。
接下來,我們將介紹整個系統(tǒng)的運(yùn)作流程,每個流程都用帶括號的數(shù)字表示。
使用者利用前端網(wǎng)絡(luò)桌面系統(tǒng)的使用者接口來啟動某個云端視頻處理應(yīng)用程序,并輸入需要的分析參數(shù),這個request將被傳送給后端的Web Server。
1)Web Server依據(jù)request的需求,自動產(chǎn)生Hadoop系統(tǒng)執(zhí)行所需要的input config files,然后將input config files儲存在HDFS,以供Hadoop MapReduce platform使用。
2) Web Server開始啟動Hadoop系統(tǒng)的Map-Reduce程序。
3)由HDFS讀取需要的input config files,針對requested job的MapReduce運(yùn)作,作需要的配置,并且將此job分割為許多較小的tasks,然后分散到TaskTrackers,然后每個TaskTrackers再傳送task給自己的VA Client模塊。
4)VA Client模塊將此task,傳送給自己的VA Server。
5)VA Server根據(jù)task的參數(shù),讀取要分析的live/stored video sources。
6)VA loader加載要使用的VA模塊,然后Processor開始對接收到的視頻進(jìn)行分析,再將所得到的分析結(jié)果,回傳給VA Client。
7)VA Client將分析結(jié)果寫入HDFS。
8)Web Server周期性去讀取儲存于HDFS的分析結(jié)果。
9)Web Server將分析結(jié)果回傳給前端網(wǎng)絡(luò)桌面系統(tǒng)的使用者接口來顯示。
2 系統(tǒng)設(shè)計
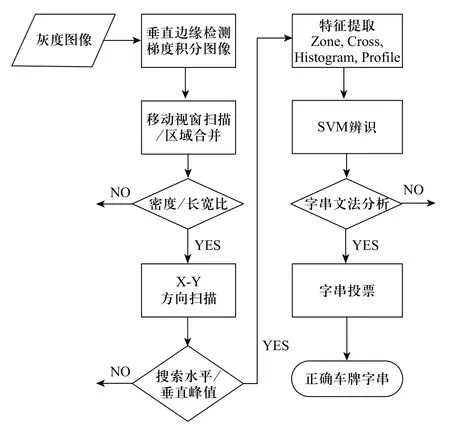
圖2 車牌識別系統(tǒng)流程圖
2.1 視頻處理模塊—車牌識別
本文的車牌識別方法主要有三個步驟:車牌定位、字符切割與字符識別,個別模塊分述如下。
1)車牌定位:采用垂直方向的影像梯度做前處理,利用預(yù)先設(shè)定大小的移動窗口快速掃描整張影像,同時利用統(tǒng)計的車牌樣本的邊緣密度、長寬比、最小長寬等信息,檢查掃描區(qū)域是否為影像中的車牌候選區(qū)域。
2)字符切割:字符切割采用X-Y切割的方式[3],首先針對車牌候選區(qū)塊做X方向掃描以定出字符區(qū)域的最高及最低的水平位置。接著對Y方向進(jìn)行掃描,以車牌候選區(qū)塊的1/6高度為搜尋區(qū)域,找出垂直灰階投影的區(qū)部峰值,并針對峰值間以最符合字符區(qū)塊長寬比為原則進(jìn)行區(qū)塊合并。
3)字符識別:步驟2)求得車牌字符后,將每個字符影像進(jìn)行正規(guī)化,并擷取局部特征為Zone、Cross、Histogram和Profile等四大類。
2.2 云端視頻處理演示平臺
我們使用了八臺e-Box主機(jī)(Atom 1.8GHz)來構(gòu)建一個小型的實(shí)驗性云計算平臺,我們的云端視頻處理系統(tǒng)安裝于此云計算平臺。在前端的行動攝影機(jī)部份,此行動式攝影機(jī)可通過3G/WiMax/WiFi的無線網(wǎng)絡(luò)上傳實(shí)時取得的影音信息到中央服務(wù)器組以進(jìn)行視頻及分析。我們的云端視頻處理平臺,將針對行動式攝影機(jī)取得的實(shí)時影音數(shù)據(jù)流,作并行化的視頻處理運(yùn)算,來驗證此云端平臺的可行性及有效性。
在網(wǎng)絡(luò)桌面系統(tǒng)的實(shí)作部份,我們使用了Ext GWT[4]來加以實(shí)作,Ext GWT是一個以GWT為基礎(chǔ)的因特網(wǎng)應(yīng)用程序框架,可幫助程序設(shè)計者快速開發(fā)GWT的使用者接口。如圖3所示,是我們的前端網(wǎng)絡(luò)桌面的畫面,為了同時分析四個行動式攝影機(jī)所傳送過來的實(shí)時影像,我們同時開啟四個分析窗口,當(dāng)開始車牌識別分析時,這些分析要求會被傳送給后面的云端視頻處理平臺,然后將這些分析工作,分散給不同的云端主機(jī)進(jìn)行運(yùn)算,最后再回傳結(jié)果并顯示在前端的應(yīng)用程序窗口,如圖3的(1)所顯示的車牌號碼6797QD,即為視頻中所行駛的車輛所掛的車牌號碼。此外,我們的網(wǎng)絡(luò)桌面可實(shí)時顯示目前每個云端主機(jī)的CPU使用率,來觀察每個云端主機(jī)目前的負(fù)載情況,如圖3的(2)所示,并證明分析工作有被分散到多個云端主機(jī)上,所以每個云端主機(jī)的CPU使用率都很低,表示分析工作并沒有集中到同一個云端主機(jī),而造成某個主機(jī)過高的CPU使用率。
2.3 實(shí)驗結(jié)果
我們使用了八臺e-Box主機(jī)來測量車牌識別的執(zhí)行時間,來觀察多臺主機(jī)并行化視頻處理的效能。總共的執(zhí)行時間(Total Time)分為:
1)從儲存裝置讀取要分析的影像數(shù)據(jù),然后通過網(wǎng)絡(luò)傳輸?shù)皆贫酥鳈C(jī)的時間(Query Time);
2)將識別出的車牌號碼通過網(wǎng)絡(luò)傳輸,寫入到儲存裝置的時間(InsertResult Time);
3)作車牌檢測及識別的時間(VA Time)。
本次實(shí)驗總共測量處理1000 frames所需的時間,frame的大小為352×240,并且每張frame都具有車牌,所以每張frame都會被檢測并且識別出正確的車牌號碼。Query Time和InsertResult Time在不同的云端主機(jī)個數(shù)的實(shí)驗結(jié)果如圖4所示,VA Time和Total Time在不同的云端主機(jī)個數(shù)的實(shí)驗結(jié)果如圖5所示。如同所預(yù)期的,當(dāng)可以并行作車牌識別的云端主機(jī)個數(shù)增加時,InsertResult Time、VA Time、Total Time都隨之減少,尤其是占最大比例計算時間的VA Time,當(dāng)主機(jī)個數(shù)呈倍數(shù)增加時,VA Time即呈倍數(shù)減少。
然而,Query Time卻沒有隨著主機(jī)個數(shù)的增加而減少,這是因為受限于網(wǎng)絡(luò)的頻寬,存取影像數(shù)據(jù)的I/O速度和主機(jī)間互相競爭存取網(wǎng)絡(luò)和儲存裝置所導(dǎo)致,即使有多臺主機(jī)的并行化處理,仍然無法減少Q(mào)uery Time。當(dāng)主機(jī)個數(shù)增加到3臺時,是能夠減少Q(mào)uery Time的,但是當(dāng)主機(jī)個數(shù)過多時,由于大家同時競爭存取網(wǎng)絡(luò)和儲存裝置,而導(dǎo)致Query Time小量增加。然而這個問題應(yīng)該可以通過增加云端平臺局域網(wǎng)絡(luò)的頻寬及使用高速且分布式的儲存裝置來加以改善。然而,Query Time只占了整體執(zhí)行時間的一小部份,因此并不會嚴(yán)重地影響到執(zhí)行的效能,整體的執(zhí)行時間仍然依賴于VA Time,當(dāng)視頻分析的主機(jī)個數(shù)增加時,確實(shí)大量地減少所需要的VA Time來提升效能。
3 結(jié)論
本論文提出了一個云端視頻處理平臺,可通過云端化的程序及流程將視頻處理模塊整合到云端平臺上,以進(jìn)行有效率的并行化運(yùn)算。對于需要云端化視頻處理平臺的公司而言,如保安公司,此平臺可簡便地云端化即有的視頻處理模塊。對具有大型云端主機(jī)出租的供貨商,如中國電信、中國聯(lián)通,此平臺可為供貨商提供的云端硬件資源,構(gòu)建應(yīng)用程序云端化的架構(gòu)。對制造視頻處理模塊的廠商而言,可讓設(shè)計者不需要考慮云端化應(yīng)用程序設(shè)計實(shí)作的復(fù)雜度,仍然用原來的概念及方式來編寫應(yīng)用程序。
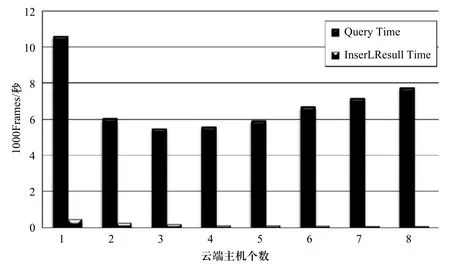
圖4 Query和InsertResult Time的執(zhí)行時間
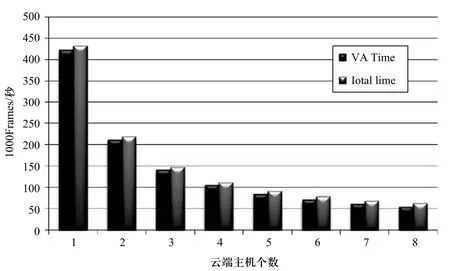
圖5 車牌識別時間(VA Time)和總執(zhí)行時間
[1]祝家鈺,肖丹,等.云計算下負(fù)載均衡的多維QoS 約束任務(wù)調(diào)度機(jī)制[J].計算機(jī)工程與應(yīng)用,2012,25(3): 90-95.
[2]曾誼暉,鄂加強(qiáng),等.基于Berkeley DB和GWT的對象持久性研究[J].微計算機(jī)信息,2011,27(2):195-150.
[3]王睿,李斌,等.基于形狀上下文識別算法的車牌識別研究[J].計算機(jī)仿真,2011,28(11): 343-345.
[4]胡曉紅,付永軍,等.基于策略的Web服務(wù)安全解決方案研究[J].微計算機(jī)信息,2008,16(3): 93-94.
猜你喜歡
工業(yè)設(shè)計(2022年8期)2022-09-09 07:43:20
軍民兩用技術(shù)與產(chǎn)品(2021年10期)2021-03-16 06:05:30
民用飛機(jī)設(shè)計與研究(2020年4期)2021-01-21 09:15:02
北京測繪(2020年12期)2020-12-29 01:33:58
裝備制造技術(shù)(2019年12期)2019-12-25 03:06:46
中國洗滌用品工業(yè)(2019年4期)2019-05-11 09:27:34
電子制作(2018年18期)2018-11-14 01:48:24
家庭影院技術(shù)(2017年9期)2017-09-26 03:41:45
山東工業(yè)技術(shù)(2016年15期)2016-12-01 05:31:22
中國中醫(yī)藥現(xiàn)代遠(yuǎn)程教育(2014年11期)2014-08-08 13:23:44
