基于平穩時間序列模型的開都河年徑流量預報
2012-01-18 16:14:48楊昕馨
地下水 2012年3期
關鍵詞:模型
楊昕馨
(新疆宏昌水利規劃設計公司,新疆烏魯木齊830000)
基于平穩時間序列模型的開都河年徑流量預報
楊昕馨
(新疆宏昌水利規劃設計公司,新疆烏魯木齊830000)
提供一個具有較好的適應性和預報精度的模型預報應用程序。運用C#語言設計實現模型的建立及年徑流量的預報,通過新疆開都河大山口水文站年徑流量時間序列的應用表明,該模型的預報精度滿足要求。
平穩時間序列分析;自回歸模型;年徑流量;開都河
平穩時間序列分析在預報中已有多年的應用,把水文要素隨時間的變化作為一個隨機過程來研究,將某一水文隨機過程離散化以后可得到一個水文時間序列,在一定條件下,可分析出水文要素前后期演變情況的統計規律,并可應用這一統計規律由前期水文要素的數值作出后期要素的預報。
1 時間序列分析基本原理
平穩時間序列分析是研究具有平穩性的一個時間序列在不同時間間隔之間自身線性相關關系的方法,所建立的模型稱為自回歸方程。其表達式為
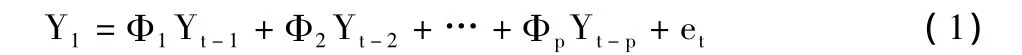
式中:p為自回歸模型的階數,原則上p可為任意非負整數;Yt、Yt-1、Yt-p分別為時間序列在 t、t- 1、t- p 時的觀測值;Ф1,Ф2,…,Фp為自回歸模型的參數;et為誤差或偏差,表示不能用模型描述的隨機因素。
自回歸模型是在各態歷經平穩的假定下來進行預報的。但是,在水文數據不能根據簡單的物理考慮作出是否接受平穩性假設時,可對時間序列先進行零均值化、差分平穩化等處理,使其滿足模型前提條件。零均值化處理,是指對均值不為零的時間序列中的每一項數值都減去該時間序列的平均數,構成一個新的均值為零的時間序列,即

式中:Y均是原時間序列的平均數。
差分平穩處理是指對零均值的非平穩時間序列進行差分,使之成為平穩的時間序列。即對序列Yt進行一階差分,得到一階差分序列▽Yt。
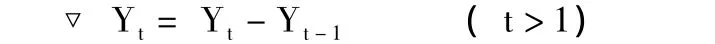
對一階差分序列▽Yt再進行差分,得到二階差分序列▽2Yt。
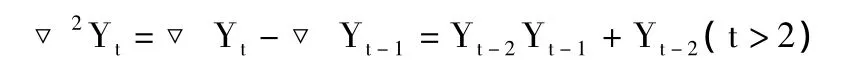
依此類推,可得到n階差分序列。一般情況下,非平穩序列在經過一階差分或二階差分都可以實現平穩化。模型中的自相關系數與偏相關系數對識別時間序列的特性具有重要的作用。一般地,Yt-k是其滯后k時數據形成的序列。時間序列相差k個時期的兩項數據序列之間依賴程度或相關程度可用自相關系數rk表示:
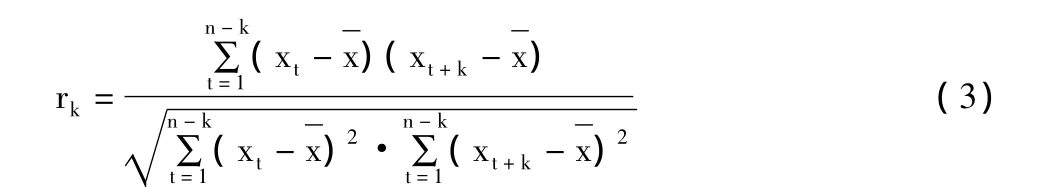
式中:表示第t時段觀測值;表示時段平均值;n為序列長度;k為滯時,k=1,2,…,m。
偏自相關是時間序列 Yt在給定了 Yt-1,Yt-2,…,Yt-k+1的條件下,通過剔除其它各期的影響,Yt與滯后k時間序列之間的條件相關。它用來度量當其它滯后1,2,3,…,k-1時間序列的作用已知的條件下,Yt與Yt-k之間的相關程度。這種相關程度可用偏自相關系數來度量Φkk,可用偏自相關系數來初步判定模型的階數,偏相關系數可用遞推法求解,其計算公式為:
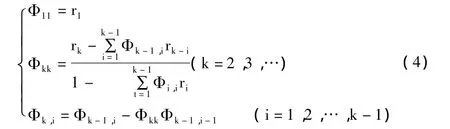
模型的階數識別對自回歸模型來講甚為重要,可用FPE(最終預報誤差)準則來識別:
FPE(k)=(1+k/n)(1-k/n)δ2(k)
式中:δ2(k)=r(0)- ∑B(k,i)r(i),其中 i=1,2,…,k。
當k分別取1,2,…,n-1時,可求得不同的 FPE(k)值,其中最小FPE(k)對應的k值即為模型階數的估計值。另據經驗分析,模型階數k可取值于n/10與n/4之間。如果n≥50時,可取k<n/4,常取k在n/10左右;如果n<50時,可取k在n/4左右。
2 自回歸模型的編程實現與預報
模型建立采用面向對象的編程方法來實現,程序設計語言采用C#。C#是一種最新的、面向對象的編程語言。它可快速地編寫各種基于Microsoft.NET平臺的應用程序。最重要的是C#使得C++程序員可以高效地開發程序,而絕不損失C/C++原有的強大功能。應用程序采用3層設計:①數據層,該層提供了對時間系列數據的提取訪問,對系列的特征值、模型各項參數的存儲功能等,本系統采用Microsoft Access數據庫;②事務邏輯層:該層是程序的核心部分,完成模型的構建與求解等功能。該層包含的模塊有數據序列的平穩化,可根據用戶需要選擇一種或一種以上的數據系列平穩方法,使系列滿足模型的前提條件,系列特征值求解、自相關系數求解,自回歸系數求解,求預報值,誤差統計,擬合度檢驗等;③表示層,該層提供應用程序與用戶的接口,也就是用戶界面。主要實現與用戶的交互,如數據序列的選擇、模型參數的選擇,自回歸系數、偏相關系數的顯示,顯示歷史擬合曲線圖等。
3 模型應用
開都河位于新疆巴音郭楞蒙古自治州境內,發源于天山南麓中部的伊連哈比爾尕山,流經巴州和靜、焉耆、博湖三縣,最終流入全國最大的內陸淡水湖——博斯騰湖。河流全長525 km,多年平均徑流量32.89億 m3,天然落差1 843 m,水能資源理論蘊藏量1 420 MW。
選用新疆開都河大山口水文站1961~2002年共42 a年徑流量序列,用平穩時間序列進行分析計算,并對2003~2007年年徑流量進行預報。運行平穩時間序列分析程序,從數據庫導入上述數據做為預報系列,根據對系列的分析選擇相應的平穩方法使其滿足模型要求,輸入模型參數,這里采用FPE來識別模型階數,進行預報。
模型對開都河年徑流量的模擬與預測值見圖1。
根據時間序列模型求得開都河2003~2007年徑流量預測值(見表1)。模型擬合效果統計值見表2。從以上模型計算與檢驗的結果來看,所建立的自回歸模型對于預報開都河徑流量具有一定的實用價值。
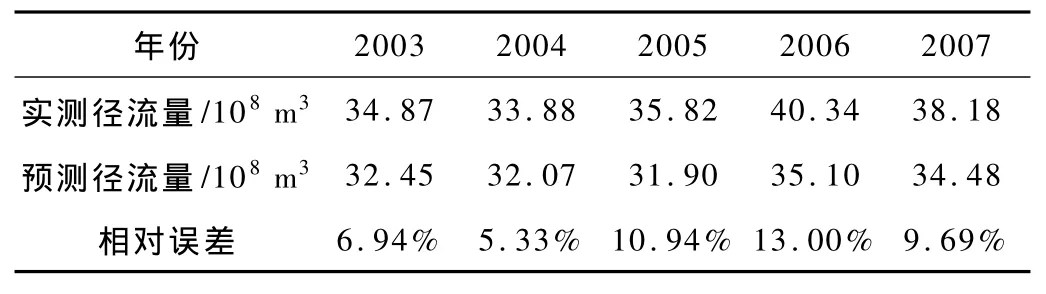
表1 模型預測誤差分析

表2 模型模擬樣本擬合效果分析
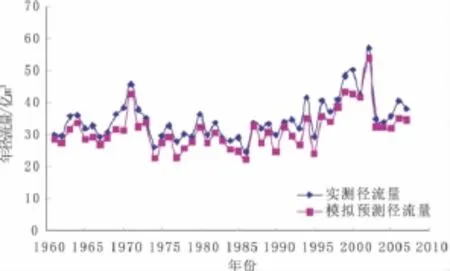
圖1 開都河年徑流量實測值與模擬值對比
4 結語
采用平穩時間序列分析的方法,對預報系列進行差分、零值化、濾波處理等,消除了異常值的影響,預報過程清晰簡單,可很快給出中期較為合理的預測值,為水文長期預報提供了一個方便且較為可靠的預測方法。但在建模過程中,由于選用的參數修正方法不夠合適,使得模型在擬合過程中存在較大誤差,為此需要選用更好的參數修正方法以得到更精確的模擬和預測。
[1]Karli Watson.C#入門經典[M].北京:清華大學出版社.2002.
[2]何書元.應用時間序列分析[M].北京:北京大學出版社.2002.
[3]SL250-2000,水文情報預報規范[S].
P338
B
1004-1184(2012)03-0140-01
2012-02-03
楊昕馨(1980-)女,新疆庫爾勒人,工程師,主要從事水利工程規劃設計工作。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
網絡安全與數據管理(2022年1期)2022-08-29 03:15:20
導航定位學報(2022年4期)2022-08-15 08:27:00
中學生數理化·中考版(2022年8期)2022-06-14 06:55:24
新世紀智能(數學備考)(2021年9期)2021-11-24 01:14:36
成都醫學院學報(2021年2期)2021-07-19 08:35:14
新世紀智能(數學備考)(2020年9期)2021-01-04 00:25:14
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
光學精密工程(2016年6期)2016-11-07 09:07:19
