從語料庫文體學的視角看培根Essays的文體特征
2011-12-28 02:02:06張榮梅
通化師范學院學報 2011年11期
周 琨,張榮梅
(江蘇科技大學 外國語學院,江蘇 鎮江 212003)
從語料庫文體學的視角看培根Essays的文體特征
周 琨,張榮梅
(江蘇科技大學 外國語學院,江蘇 鎮江 212003)
采用實證的研究方法,從語料庫文體學的視角出發,建立一個包含培根隨筆集Essays的小型語料庫,并借助于WordSmith軟件,詳細比較Essays和參照語料庫Flob的部分文體特征,發現Essays具有詞匯豐富,句式靈活多變等鮮明的特點,驗證了語料庫的方法在文體學研究中的有效性。
語料庫文體學;培根隨筆集;文體特征
20世紀60年代以來,隨著語料庫語言學的迅速發展,基于語料庫的研究方法逐漸為人們所認識并采用,成為一種重要的研究范式。語料庫語言學與文體學相結合而催生的語料庫文體學(Corpus Stylistics)是一個新興的研究領域,旨在借助語料庫的工具提供一種新的途徑來描述語篇中的言語、寫作和思想表達形式,以實證的方法對文本的文體特征進行定量和定性的研究。[1]
弗朗西斯·培根(1561-1626)是英國文藝復興時期著名的哲學家和文學家,Essays是其主要文學著作,在世界文壇享有不朽的文學聲譽。該書包括58篇散文,內容非常豐富,涉及哲學思想、倫理探討、處世方法以及藝術欣賞等。培根的論述見解獨到,且文筆優美,簡潔老練,警句迭出,被奉為散文史上的杰作,因而備受推崇,重印不衰,并被譯成各國文字廣為流傳。
一、Essays語料庫的建立及相關分析軟件
Leech和Short(1981)提出了一個文本分析模式,用來分析文本的文體特征。他們將考察的對象按層次整理,并列出了一個詳盡的清單,包括詞匯特征、語法特征、修辭手段、語境和銜接四大類,每一大類下面又具體分了各小類。[2]75-80本文將用語料庫的方法來研究Essays的詞匯特征和語法特征。
1.語料庫的建立
國內外有多家出版社都出版了Essays這部作品,但基本都是忠實于原著,沒有進行什么刪改。作者以目前較為流行的外語教學與研究出版社1998年4月的版本為依據,將全書58篇文章電子化,并對書中的標題、段落以及句子等基本信息進行初步的標注(annotation)。在此基礎上,利用CLAWS標注系統對其進行詞類賦碼(tagging)并進行后期的手工校對,改正自動賦碼過程中的少量錯誤。這樣,一個簡單Essays語料庫就建成了。
2.參照語料庫
Flob (Freiburg-Lob Corpus of British English)語料庫是Lob語料庫的更新版本,收錄了20世紀90年代英國英語語料。該語料庫的庫容為100萬詞左右,包含500個各類文體的文本,每個文本大約2000詞,是一個很好的參照語料庫。
3.WordSmith 5.0
WordSmith是一款功能非常強大的語料庫軟件,目前的最新版本是5.0,由利物浦大學的Mike Scott博士開發。它具有很強的詞語索引和統計功能,能提供多項統計數據,如形符、類符、類符/形符比、標準化類符/形符比、詞頻、平均詞長、平均句長等。
二、Essays的詞匯特征和語法特征
本文所采用的WordSmith 5.0軟件在分析過程中將所考察的部分詞匯和語法范疇交叉在一起,例如表1同時包含詞匯和句子的分析數據,而其中句長等概念在Leech和Short的清單中則屬于語法范疇;表4中包含的各個詞類則依實詞和虛詞的區分被分別歸入了詞匯和語法范疇。因此,為了方便討論,在下面的研究中筆者也把這兩大類特征放在一起考察。
1.形符、類符、類符/形符比和標準化類符/形符比
運行WordSmith 5.0,分別打開Essays和Flob語料庫,利用軟件中的“Wordlist”功能,經簡單計算后可以得到如下的統計數據:
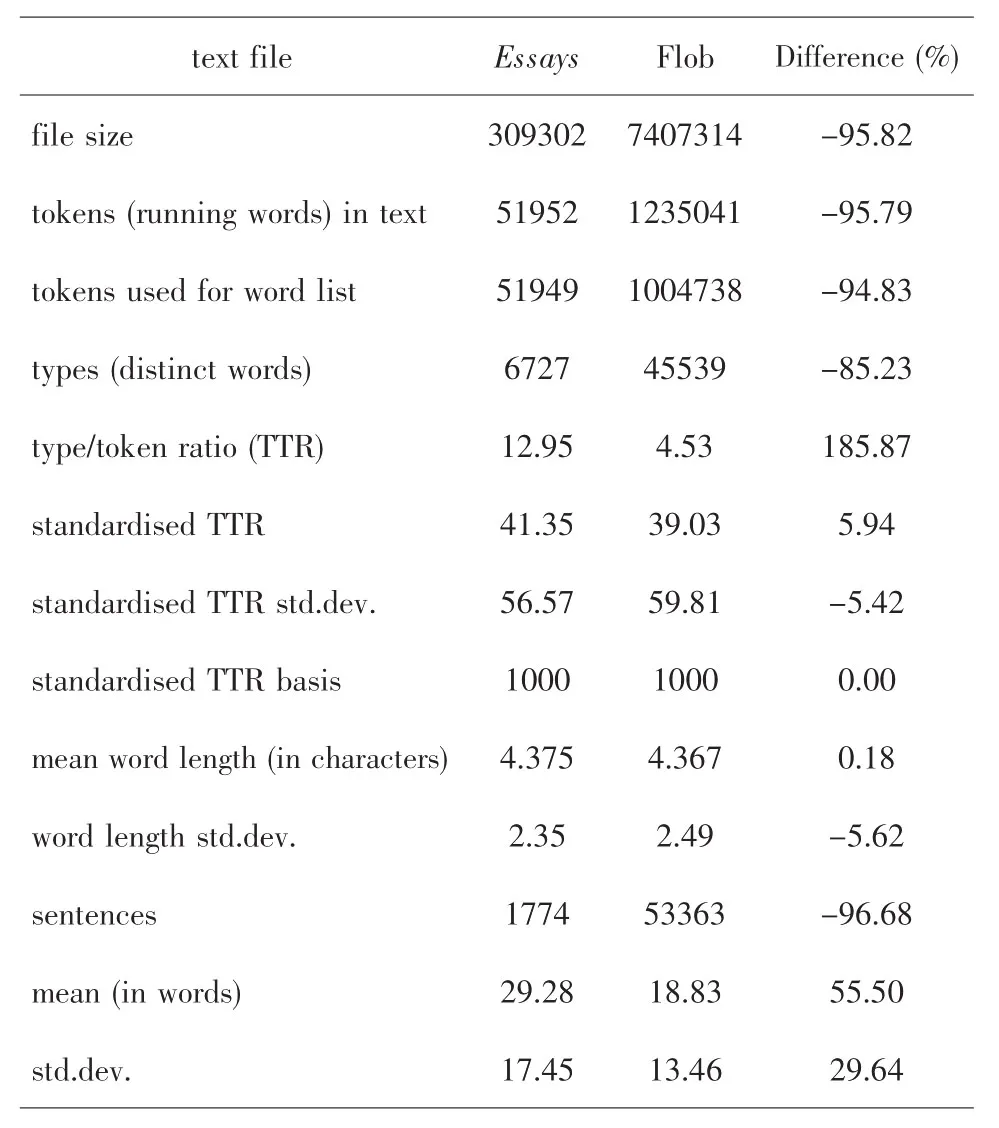
表1 Essays和Flob基于Wordlist功能的主要統計數據
形符(tokens)是一個語言單位,類似于我們日常說的“詞”。[3]9形符數是語料庫容量的最常用的測量單位,一個文本的形符數就是該文本的長度。比如,一個1億詞的語料庫就是指這個語料庫有1億個形符。從表1可以看出,Essays的總形符數為51,952,去除文本中的阿拉伯數字以后的形符數為51,949;Flob 的總形符數為 1,235,041,去除阿拉伯數字后的形符數為1,004,738,因此這兩個語料庫從容量上來說相差近20倍。
類符(types)指不重復計算的形符數,重復出現的形符只能記作一個類符。[3]9一個文本的類符數就是該文本不同形符的數量。例如,一個100詞的文本中,如果有80個不同的單詞,那么這個文本的形符數為100,類符數為80。如表1所示,Essays和Flob的類符數分別為為6,727和45,539。
類符/形符比(TTR,type/token ratio)是衡量文本中詞匯密度(lexical density)的常用方法。[3]9從表1的數據來看,兩個語料庫的TTR存在巨大差異:Essays為 12.95,而 Flob僅為 4.53,但這并不表示Essays的詞匯密度達到Flob的三倍之多,而主要是由于兩庫的庫容相差巨大,TTR不能準確反映其詞匯密度水平。這種情況下我們可以借助標準化類符/形符比的概念來進一步考察兩庫的詞匯密度情況。
標準化類符/形符比 (STTR,standardised type/token ratio)是按一定長度分批計算文本的TTR,然后計算所有TTR的平均值所得的結果。比如,Wordsmith默認設置長度設為1000(可根據文本的長度進行適當的調整),則在運行過程中會計算文本中每1000個形符的TTR,然后計算出所得的所有TTR的平均值,得到的數值就是該文本的STTR。這種方法可以彌補用TTR來計算不同長度文本詞匯密度的不足。因此我們來看一下這兩個語料庫的STTR 值:Essays為 41.35,Flob 為 39.03,Essays高于Flob 5.94%。這組數據應該是比較理性和可靠的,它們說明相對于參照語料庫來說,Essays的詞匯密度較大,也就是說Essays的詞匯使用更加靈活,詞匯量更為豐富。
2.詞長分布及平均詞長
詞長 (word length)即一個單詞所包含的字母數。通過Wordsmith的Wordlist功能,我們還可以得到語料庫中有關詞長的數據。
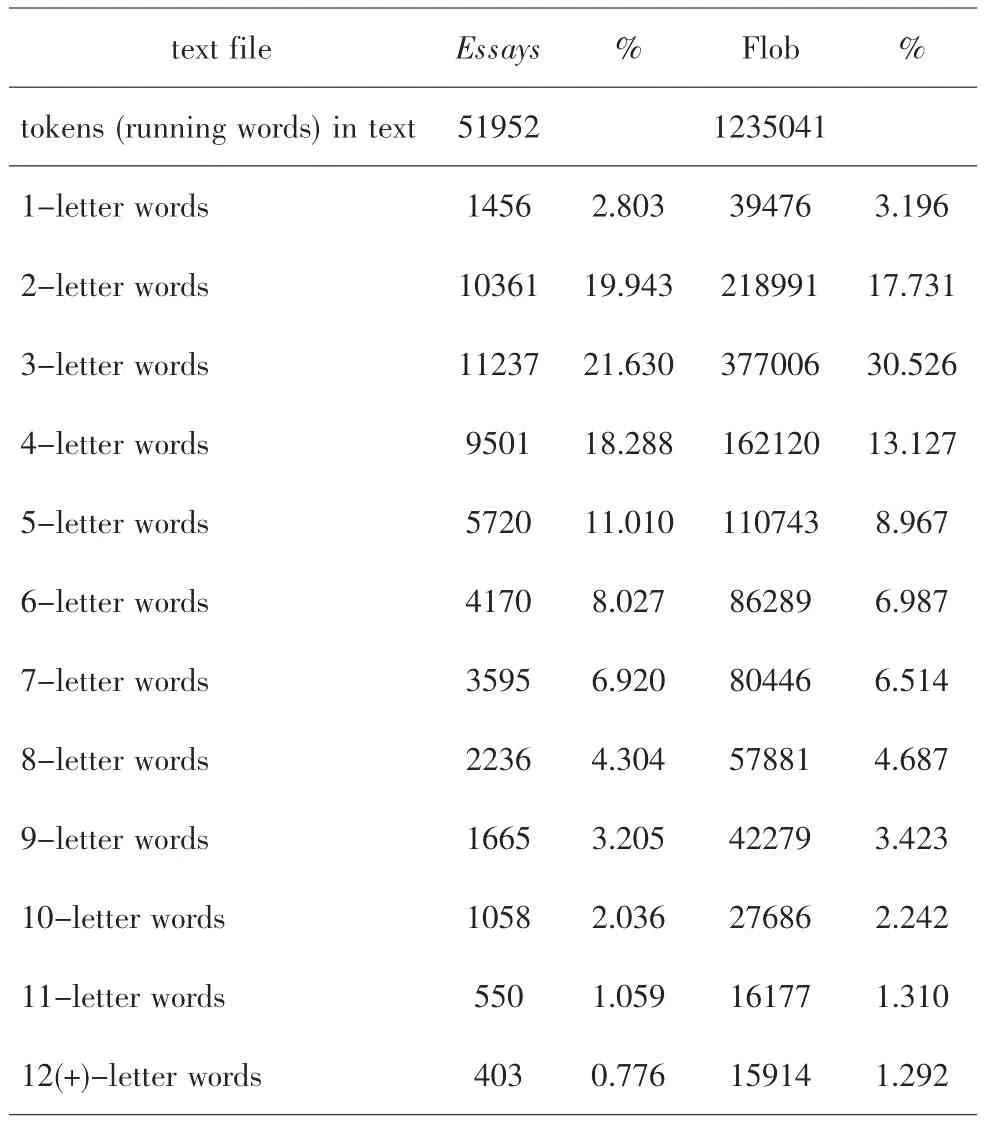
表2 Essays和Flob的詞長分布情況
觀察表2的數據我們可以發現,Essays和Flob中四個字母以下的單詞均占較大的比重,所不同的是,Essays的雙字母單詞和四字母單詞的比例大于Flob,而單字母單詞和三字母單詞的比例則小于Flob。另外,Essays中包含5-7個字母的單詞所占比重均高于Flob,而8個及以上字母構成的單詞則比重較小。
平均詞長(average word length)指文本中單詞的平均長度。一般來說,一個文本的平均詞長反映該文本中詞匯的復雜程度和難易程度。從表1的數據來看,Essays的平均詞長為4.375,略高于Flob的4.367,這說明整體而言,Essays中用詞的復雜程度和難度略高。
3.平均句長及其標準差
平均句長(average sentence length)指文本中句子的平均長度。一般來說,一個文本的平均句長越長,則說明該文本的句子越復雜,反之則越簡單。根據表1的數據,Essays的平均句長達到每句29.28個單詞,大大高于Flob的平均每句18.83個單詞,這充分說明培根在Essays中使用了大量較長的語句。
標準差(std.dev.,Standard Deviation)是一個統計學概念,指一個數據集中各數據偏離該數據集平均數的距離的平均數,能反映該數據集的離散程度。就句長標準差而言,如果一個文本的句長標準差較大,則表示該文本的句長偏離平均句長較大,也就是說該文本中各個句子間的長度差異較大;反之則說明該文本中各個句子的長度比較一致,相差較小。觀察表1中的數據發現,在Essays中,句長標準差為17.45,高出Flob近30%,可以看出培根在Essays中的語言使用富于變化,句式靈活,既有大量的長難句,也運用了一些簡潔的短句,增加了語言的表現力。
4.詞頻
詞頻(word frequency)指一個單詞在文本中出現的次數。詞頻可用于觀察、比較不同單詞的使用頻率,并從文本中出現的一些高頻詞中發現作者的用詞習慣。
用Wordsmith分別運行Essays和Flob,觀察各自的frequency列表,我們可以發現,Essays中詞頻超過1%的高頻詞有13個 (如表3所示),Flob有8個;而Essays中詞頻超過0.1%的有120個,Flob有97個。從表3中還可以看出,在這13個高頻詞中,只有a和the這兩個冠詞在Essays中出現得比Flob少,特別是the,少了近1%,這說明培根在Essays中冠詞使用偏少。另外,Essays中部分連詞的使用則明顯多于 Flob,如 and,that,but等,這也符合 Essays中句式比較復雜,長難句較多的特點。
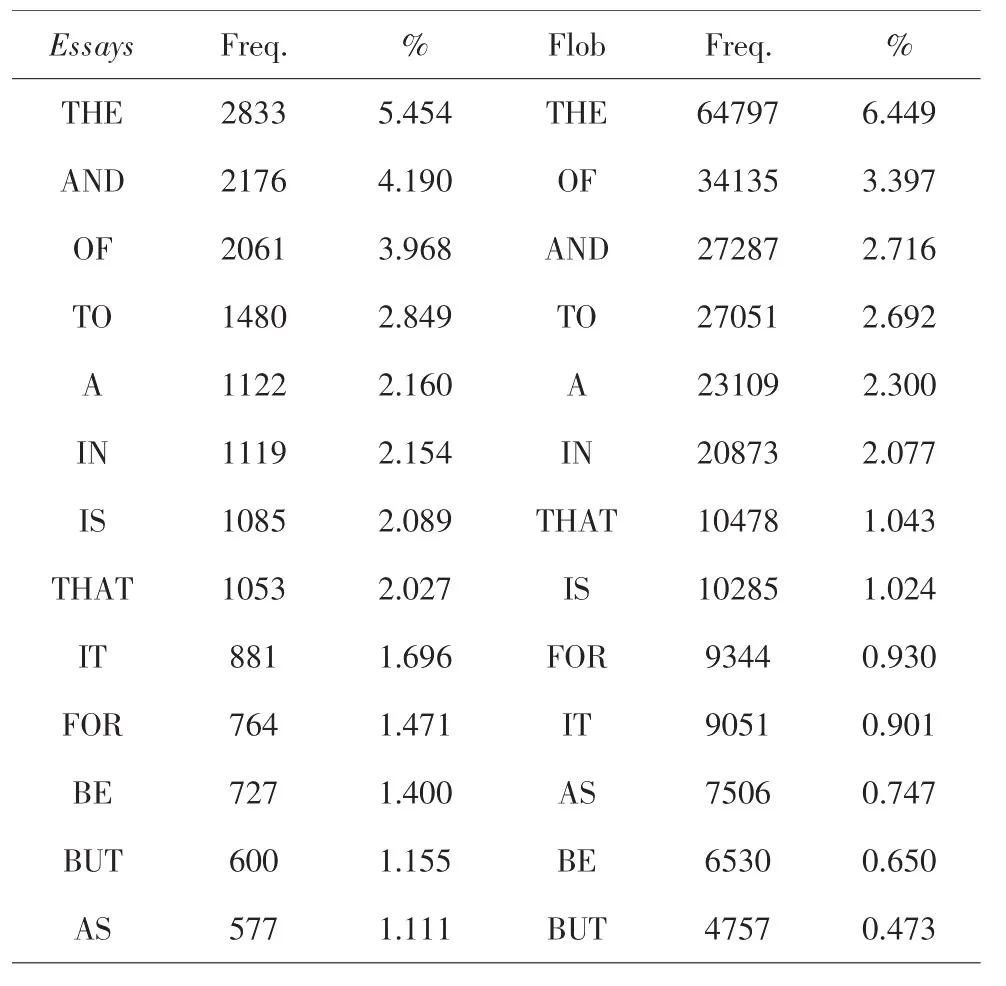
表3 Essays和Flob中的部分高頻詞
5.詞類分布
運用Wordsmith的Concord功能對Essays和Flob分別進行檢索,并對檢索結果進行簡單的計算,可以獲得這兩個語料庫中主要詞類的使用情況,如表4所示:
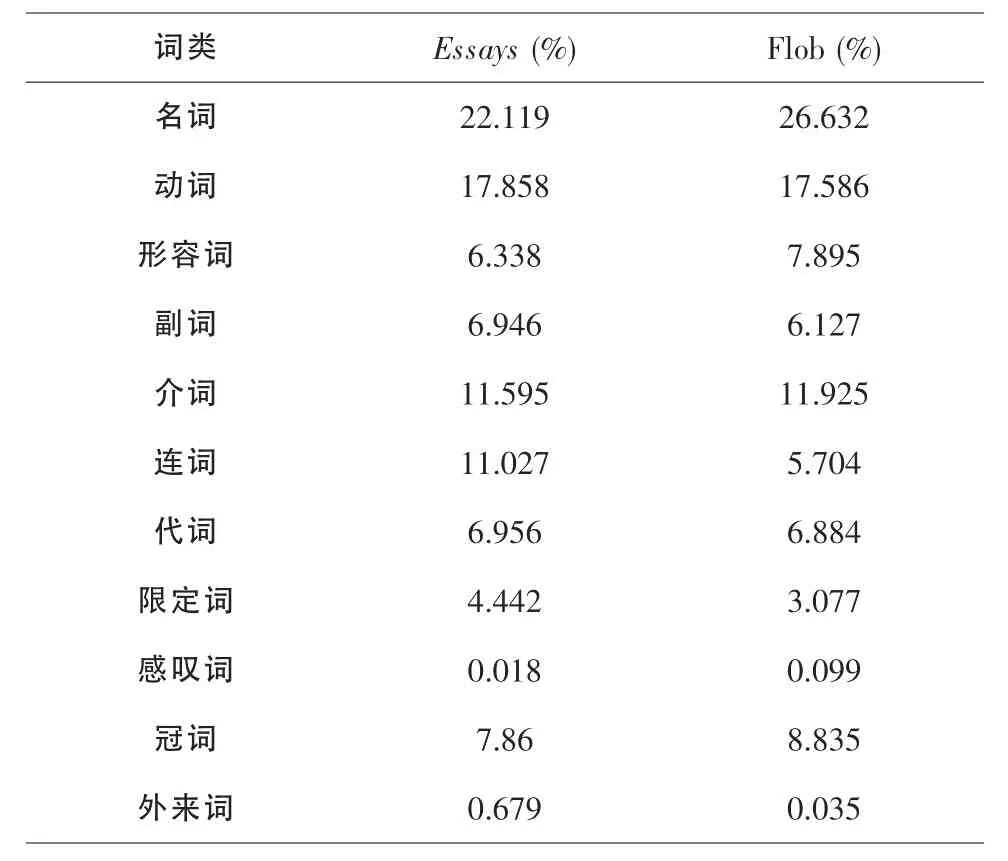
表4 Essays和Flob的詞類分布情況
表4的數據顯示,兩個語料庫在詞類的構成上總體相當,差別不是太大。主要區別有以下幾點:(1)Essays的名詞使用量較少,相應地,主要用來修飾名詞的形容詞和冠詞的使用量也偏少;(2)Essays中的連詞使用較多,所占比例幾乎接近Flob的2倍,使得語句更加流暢、豐滿,同時也增加了句子的長度和難度;(3)Essays中很少使用感嘆詞,感嘆詞在文本中所占的比例大約相當于Flob的1/5,這說明口語化的表達在Essays中很少出現,而基本上是以書面語為主;(4)Essays中大量使用了外來語,如拉丁語、希臘語及法語等,外來詞匯的使用比例幾乎達到了Flob的20倍之多,這是該作品的一個顯著特色。
三、結語
從以上的分析中可以看出,Essays在詞匯和語法方面都具有較為鮮明的特色,如詞匯豐富,句式靈活多變等。這一結果和讀者在閱讀這部作品時的主觀感受相一致,同時也驗證了語料庫在文體分析中的有效性。然而,由于語料庫文體學畢竟還是一個比較年輕的學科,其本身還存在一定的不足,尤其是文本分析與計算機技術的結合,還有待進一步的研究和完善,如語料的深層次自動標注和相關分析軟件的研制等。筆者堅信,隨著計算機技術的不斷發展,語料庫文體學將會在語言學和文學的研究中發揮更大的作用。
[1]劉 靖,黃立波.《語料庫文體學》述介[J].外語教學與研究,2010,(3):236.
[2]Leech,G.N.,Short,M.H.Style in Fiction:A Linguistic Introduction to English Fictional Prose[M].London:Longman,1981.
[3]梁茂成,李文中,許家金.語料庫應用教程[M].北京:外語教學與研究出版社,2010.
Stylistic Features of Bacon's Essays:A Corpus Stylistic Perspective
ZHOU Kun,ZHANG Rong-mei
(School of Foreign Languages,Jiangsu University of Science and Technology,Zhenjiang,Jiangsu China,212003)
From the perspective of Corpus Stylistics,the author constructs a small corpus composed of Bacon's Essays,compares some stylistic features of Essays and Flob,a reference corpus,and finds that Essays has very striking lexical and grammatical features.The results of the research also confirm the validity of the corpus-based approach in stylistics studies.
Corpus Stylistics;Bacon's Essays;stylistic feature
H315
A
1008—7974(2011)11—0059—04
江蘇科技大學人文社科項目“曹明倫譯《培根隨筆集》的文學文體學研究”階段性成果。項目編號:2009WY124J
2011—08—20
周 琨(1976-),安徽合肥人,江蘇科技大學外國語學院講師,碩士;張榮梅(1978-),女,江蘇南通人,江蘇科技大學外國語學院講師,碩士。
林凡)
猜你喜歡
中華胰腺病雜志(2021年1期)2021-02-26 11:28:36
山東醫藥(2020年34期)2020-12-09 01:22:24
閱讀(快樂英語高年級)(2020年8期)2020-01-08 02:21:16
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
中華胰腺病雜志(2019年4期)2019-08-29 08:52:20
當代陜西(2019年10期)2019-06-03 10:12:04
智慧少年·故事叮當(2018年11期)2018-05-14 11:48:18
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
意林(繪英語)(2017年5期)2017-05-15 02:17:23
河南科技(2014年23期)2014-02-27 14:19:15
