遺傳算法與神經網絡結合預測低滲透油藏產油量——以寶浪油田為例
2011-11-09 00:29:34董玉安高立建張紅坡
石油地質與工程 2011年5期
董玉安,趙 蕊,葉 歡,廖 晶,高立建,張紅坡
(1.中國石化河南油田分公司石油勘探開發研究院,河南南陽473132;2.中國石化河南油田分公司第二采油廠;3.中國石化河南油田分公司第一采油廠)
遺傳算法與神經網絡結合預測低滲透油藏產油量
——以寶浪油田為例
董玉安1,趙 蕊2,葉 歡1,廖 晶1,高立建3,張紅坡3
(1.中國石化河南油田分公司石油勘探開發研究院,河南南陽473132;2.中國石化河南油田分公司第二采油廠;3.中國石化河南油田分公司第一采油廠)
基于遺傳算法的全局搜索能力和神經網絡算法的局部精確搜索特性,將遺傳算法和神經網絡算法有機結合,在提高油氣產量預測精度的研究中得到了很好的應用。對寶浪油田某區塊產油量的預測,驗證了這種方法的正確性,結果表明該方法預測精度明顯優于單純的BP算法,證明了這種方法的有效性和可靠性。
神經網絡;遺傳算法;寶浪油田;產量預測
新疆寶浪油田屬于典型低滲透砂礫巖儲層,油藏厚度大、Ⅲ級斷層較發育。寶浪油田自1997年注水開發以來,油田已進入中含水期,目前地下油水分布關系復雜,水驅效果差,產量遞減較快,剩余油識別難度大,導致生產效果變差。至2009年底,年自然遞減達20%左右,而且自然遞減還有加大的趨勢。按水驅開發趨勢推算,最終采收率只能達到20%左右,比標定采收率低5個百分點。因此,如何正確預測該區塊產油量,正確標定區塊采收率是油田亟待解決的問題。
在油藏工程領域,對于油田產量的預測方法較多,如產量遞減法、水驅特征曲線法、圖版分析法、廣義翁氏法、衰減曲線法、油藏數值模擬法、物質平衡法、遞減曲線法等等。由于各個油田物性、開發方式、地質特征等方面的差異,上述幾種預測方法都有一定的局限性[1-2]。因此,有必要從數學的角度出發,找出一種不拘泥于油藏性質的預測方法,并能成功應用于寶浪油田。
1 遺傳算法與BP算法簡介
人工神經網絡(ANN,A rtificial Neural Network)預測方法是對人類大腦的一種物理結構上的模擬,即利用計算機仿真的方法,從物理結構上模擬人腦,以使系統具有人腦的某些智能。在眾多的人工神經網絡模型中,多層前饋神經網絡模型是目前應用最為廣泛的模型。用逆向傳播網絡算法(BP算法,Back Propagation Nets)可以實現多層前饋神經網絡的訓練,BP算法具有簡單和可塑性的優點,能進行局部精確搜索,然而BP算法是基于梯度的方法,這種方法的收斂速度慢,而且受到局部極小點的困擾,而采用遺傳算法則可以克服BP算法的缺陷[3]。
遺傳算法 GA(Genetic A lgo rithm s)是20世紀60年代后期由美國M ichigan大學J.H.Holland教授首先提出的,它是模擬自然界生物的遺傳與長期進化過程發展起來的一種搜索和優化算法。它模擬了生物界“優勝劣汰,適者生存”的機制,用逐次迭代法搜索尋優。目前,遺傳算法已成為繼專家系統、人工神經網絡之后的又一個受人青睞的新學科[4-6]。
在對低滲油田產量的預測過程中,將BP算法的局部精確搜索能力和遺傳算法的全局搜索能力有機結合起來,能做到優勢互補,提高了預測的精度。
2 遺傳算法與BP算法結合的方法與步驟
人工神經網絡具有非常強的非線性映射能力,它不需要任何先驗公式就可以通過學習(或訓練)自動總結出生產歷史數據間的函數關系,在油氣產量預測中的應用非常有效。現有神經網絡學習算法(BP算法)存在一定缺陷,往往會降低預測結果的準確性,將遺傳算法與神經網絡有機結合,能較好克服BP算法的缺陷。
利用以下算法步驟來實現遺傳算法對神經網絡的連接權值的優化[7-8]:①確定初始輸入與輸出樣本集;②確定網絡權值的編碼形式(本文采用實數編碼),個體的位串長度;③選定遺傳算法操作,設置操作參數以及參數的調整算法;④設定種群規模為N,隨機產生初始種群;⑤譯碼種群中每一個體位串,求得N組網絡權值,得到具有相同結構的N個網絡;⑥由輸入樣本集經前向傳播算法,求得N組網絡權值對應的N個網絡輸出;⑦設定網絡的目標函數,將其轉換為適應度,對N個網絡進行評價;⑧依據適應度在遺傳空間進行選擇操作;⑨依據選定的交叉、變異及有關算法、參數,進行相應的操作,得到新一代種群;⑩返回步驟⑤,直到滿足性能要求,得到一組優化的權值。
3 應用實例
本文以新疆寶浪油田某區塊為例,區塊1997年至2009年生產指標見表1,這些歷史動態生產數據,在一定程度上本身就反映了某區塊實際的開發動態變化規律。
首先利用一般的三層(輸入層、隱含層和輸出層)BP網絡,結合遺傳算法建立了預測模型,對2010年寶浪油田某區塊產油量進行了預測。
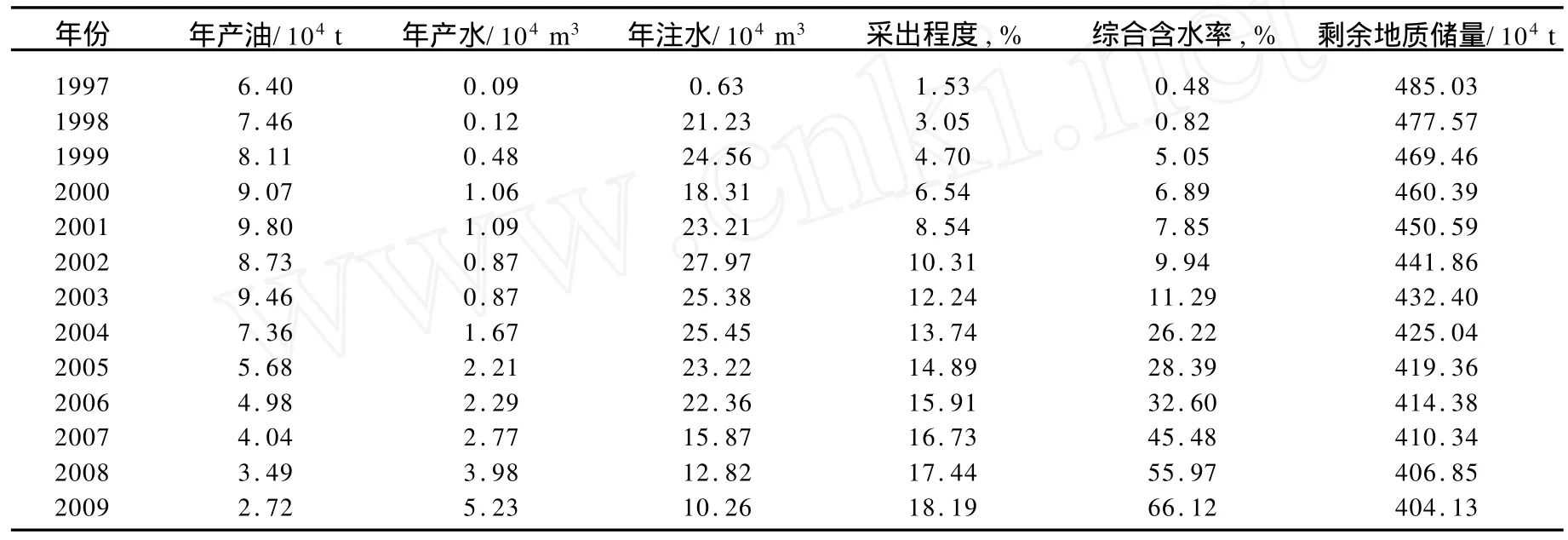
表1 寶浪油田某區塊歷年生產指標
3.1 設計BP網絡
設定輸入向量為:
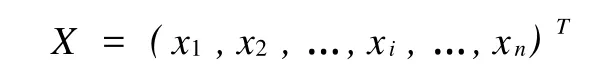
在油田開發指標預測過程中,x1可表示為當年的年產油量;x2可表示為當年的年產水量;x3可表示為當年的年注水量;x4可表示為油田當年的采出程度;x5可表示為油田當年的綜合含水率;x6可表示為油田的剩余地質儲量等。
隱含層輸出向量為:
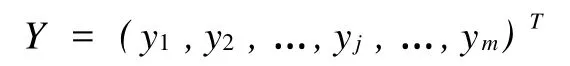
輸出層輸出向量為:
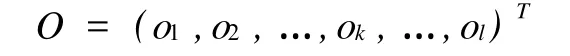
期望輸出向量為:D=(d),表示預測年份的產油量。輸入層到隱含層之間的權值矩陣用V來表示:
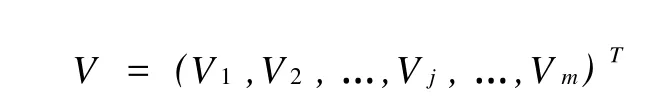
隱層到輸出層之間的權值矩陣用W來表示:
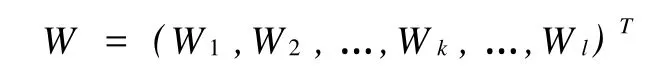
其中Wj為輸出層第j個神經元對應的權向量,BP網絡拓撲結構如圖1所示。接著分析分層信號之間的數學關系。
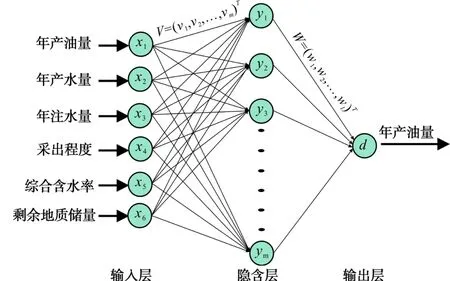
圖1 BP神經網絡拓撲結構圖

上面兩個式子中,轉移函數f(x)均為單極性Sigmoid函數,表達式如下:
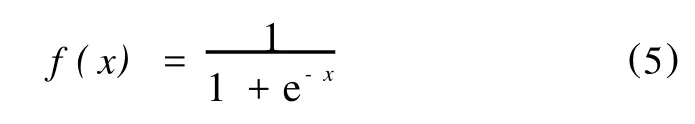
上述公式所建立的BP神經網絡通過遺傳算法學習,并按照離散時間方式運行。當網絡輸出層輸出向量與期望輸出向量不相等時,存在輸出誤差E,其定義表達式如下:
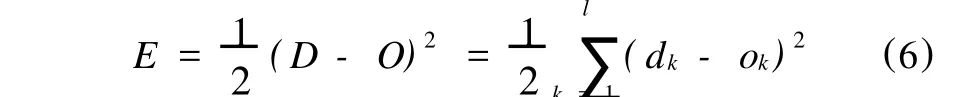
將上述誤差定義表達式展開到隱含層,則有:
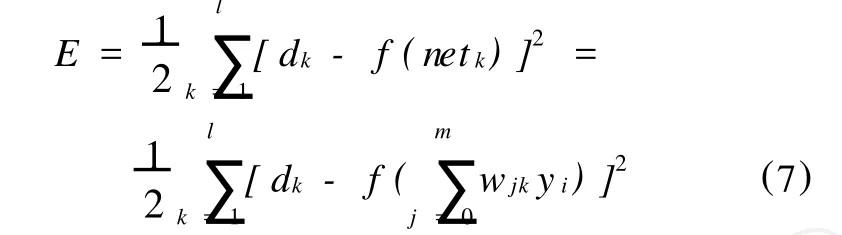
將誤差定義進一步展開至輸入層,則有:
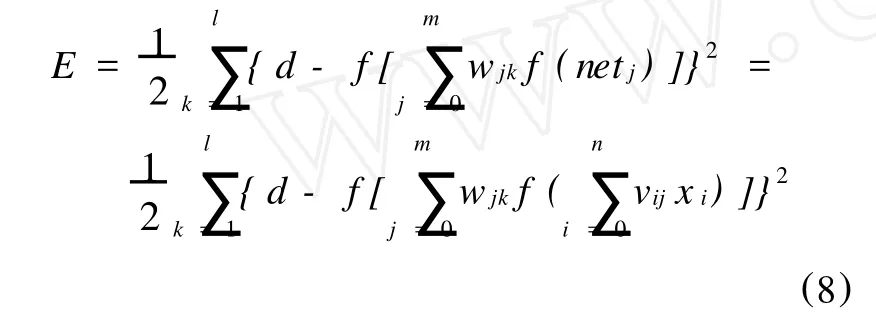
遺傳算法的目標函數可以定義為:在所有進化代中搜索網絡誤差最小的權重,相應的表達公式如下:
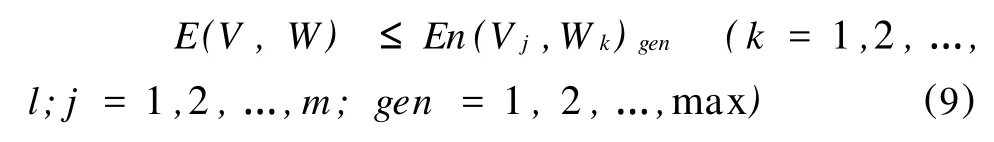
遺傳算法是以適應度函數作為進化目標的,且是朝著適應度函數值增大的方向進化,所以,適應度函數與目標函數之間要進行適當的轉換。由于進化中的網絡誤差是非零的正數,因此可以將目標函數的倒數作為適應度函數。為了保證適應度函數值不至于太小,引入一個較大的系數M,遺傳算法的適應度函數最終形式如下:
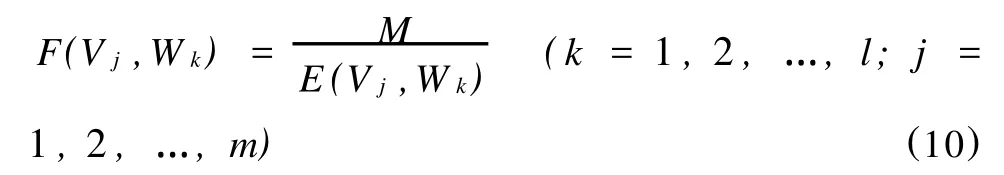
運用網絡誤差的倒數形式來表達適應度函數,這就表明遺傳算法是按照網絡誤差的隨機下降的趨勢來進化的,從而保證了遺傳算法是朝著適應度函數增大的方向進化的。
3.2 仿真步驟
本次對區塊產油量的預測過程中,應用了遺傳算法與神經網絡結合的仿真步驟,采用MA TLAB的神經網絡工具箱進行編程計算,具體步驟可分為如下10步(見圖2)。
3.3 仿真預測結果
應用上述仿真步驟和其他兩種方法(單純的BP算法和油藏工程方法),對寶浪油田某區塊產油量進行了預測(圖3),結果表明:BP與 GA結合的仿真模型效果要好于其他方法。
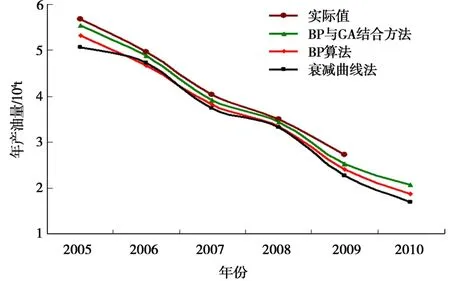
圖3 區塊年產油量預測曲線對比
4 討論
(1)利用人工神經網絡較強的非線性映射能力,建立了油氣產量預測模型,結合遺傳算法對神經網絡學習過程中的網絡連接值進行優化,取得了很好的效果,提高了油氣產量的預測精度。
(2)文中提出的方法,不但可以應用于油氣產量的預測,同時也可在油氣田開發中對其他動態指標進行預測,得到的預測值精度較高。
(3)遺傳算法作為一種新型的全局優化搜索算法,不存在求導和函數連續性的限定,在人工神經網絡的應用上展現了其獨特的優勢。隨著理論研究的深入以及計算機模擬工具的發展,遺傳算法與神經網絡結合模型將會在許多實際問題中的得到廣泛應用。
[1] 李銘,李璗.三種預測油氣田產量數學模型的比較[J].西安石油大學學報(自然科學版),2004,19(3):26-28.
[2] 吳新根,葛家理.應用人工神經網絡預測油田產量[J].石油勘探與開發,1994,21(3):75-78.
[3] Maniezzo V.Genetic evolution of the topology and weight distribution of neural netwo rks[J].IEEE Trans On Neural Netwo rks,1994,5(1):39-53.
[4] 董明,席裕庚.基于遺傳算法的干擾試井解釋方法[J].石油大學學報(自然科學版),1997,21(4):33-36.
[5] 王光蘭,賈永祿,柯益化,等.遺傳算法在油田產量預報中的應用[J].西南石油學院學報,2000,22(2):34-35.
[6] 欒國華,何順利,舒紹屹,等.應用人工神經網絡方法預測氣井積液[J].斷塊油氣田,2010,17(5):575-578.
[7] 段永剛,陳偉,黃誠,等.有限導流垂直壓裂井混合遺傳自動試井分析[J].西南石油學院學報,2000,22(4):41-43.
[8] 劉鐵男,陳廣義,劉延力,等.模擬生物種族形成的進化算化與多峰函數優化[J].控制與決策,1999,14(2):185-188.
TE319
A
1673-8217(2011)05-0060-03
2011-05-19;改回日期:2011-06-19
董玉安,油藏工程師,1960年生,主要從事低滲透油氣藏開發方案編制、動態分析等研究工作。
編輯:吳官生
