混合遺傳算法求解車間作業調度問題
2011-10-16 05:30:28周海峰
赤峰學院學報·自然科學版 2011年9期
關鍵詞:作業
周海峰
(江蘇廣播電視大學,江蘇 南京 210017)
混合遺傳算法求解車間作業調度問題
周海峰
(江蘇廣播電視大學,江蘇 南京 210017)
所謂生產調度問題,其實質如何分配資源使其更優化.這里我們所講的資源指的是車間生產所需的設備資源.對車間生產作業調度問題進行求解,其目的就是要找出一個能夠將一組工件更為科學、合理的安排到機器上從而實現最優化的生產作業方案.本文采用一種啟發式算法和遺傳算法相結合的混合遺傳算法,在運用過程中給出其應用方法.
啟發式算法;遺傳算法;車間作業調度
1 生產調度問題
調度就是指對共同使用的資源進行統一的時間分配,其作用是為了實現某一目的.而本文所提出的車間作業生產調度,則是指利用一組機床在加工一組零件時,對每臺車床加工工件的順序進行合理的安排,實現諸如總加工時長、總加工成本或相對加工時長等指標的最優化.通常若干不同工序組成了零件的整個加工過程,并且該過程要滿足對應的約束關系.在車間作業調度過程中,約束條件的內容與數量會隨著作業環境及作業要求的變化而變化,比如加工設備條件或者零件的加工工藝要求等等.
本文定義n個工件的集合為:P={P1,P2,…,Pn};而m臺加工車床的集合則為:M={M1,M2,…,Mm};工件Pi加工工序數目定義為Ki;則其加工工序定義為:Pi1(Ji1),Pi2(Ji2),…,PiKi(JiKi)(Ki∈Z+,i=1,2,…,n)這其中Z+為正整數,零件Pi在進行第Ki道工序表示為JiKi,(JiKi∈M);而被加工零件經過第Ki道工序加工的開始時間表示為STiKi;被加工零件Pi在進行第Ki道工序的加工的結束時間表示為ETiKi;TiKi為工件Pi加工第Ki道工序的時間.按照上文所述的定義,則車間作業調度的約束條件為以下幾個:第一,每個工序中均包含一個工序集合,該工序集合由多道工序組合而成,且要預先給定工件加工工序的順序;第二,某臺機器同時只可以加工一個零件的其中一道工序;再次,加工零件不一樣,其各工序間不存在先后的約束條件,工件相同,其工序需符合前后的約束關系;第四,工序PiKi(JiKi)和PiKi+1(JiKi+1),二者的時間相距為零,即STiK-i+1-ETiKi=0;第五,每個零件在進行每道工序加工時,其開始時間要大于等于零,即STiKi+1-ETiKi=0;第五,每個工件每道加工工序的開工時間必須大于或者等于零,即STiKi≥0;第六,所有的要件要在預定交期前全部完工,設Ti為加工工件Pi的總時間,即∑TiKi=Ti.
2 混合遺傳算法
本文所提出的混合遺傳算法的應用為:將啟發式算法融入遺傳算法中,再利用該混合算法求解車間生產調度排序的問題.遺傳算法為一種群體優化算法,其通過選擇和變異及交叉等不同操作,不斷的進化解集性能,從而可以使搜索的速度得到進一步提高.不過遺傳算法也存在不足,即難以控制早熟及收斂性等問題.作為傳統的啟發式算法,有著搜索速度快且結構簡單的優點,但是其也存在搜索能力差且容易陷入局部最優等不足.基于二者的優勢與不足,將其進行結合,將啟發式算法融入遺傳算法中,重新構造出的混合遺傳算法能力更強,對于求解比較復雜的優化問題有著積極的意義.該混合方法融合了遺傳算法的記憶功能和并行性,并將其與啟發式算法的快速搜索優勢相結合,使得求解質量得到了進一步的提高.具體來講對遺傳算法進行改進的方法主要為以下幾點:第一,將啟發式嵌入初始化中,產生一個初始解群,且該初始解群要具備良好的適應性能,這種方法可以使混合遺傳算法優于啟發式算法;第二,把啟發式融入評估函數中,將染色體進行解碼轉換為生產調度;第三,對個體變異及交叉率進行自適應設計.上述幾點中,在進行個體中全局搜索時主要采用遺傳算法;而對染色體部分搜索則利用啟發式算法.由于啟發式與遺傳算法二者存在相應的互補性,所以二者相混合的算法更優于兩種單獨算法.
3 利用混合遺傳算法進行車間作業調度的求解
3.1 參數編碼
在進行遺傳算法的求解過程中,要將問題所在空間的相關參數轉化為遺傳空間的參數,還要經過基因依據所對應的結構組成染色體,這個將問題空間參數向著遺傳空間參數轉化的過程可以稱之為編碼.編碼的表達方法有很多,有基于工序的、基于工件的或者基于位置列表的以及基于機床的表達等等,本文所采用的是基于機床的表達方法.將染色體進行編碼為設備序列,以該序列為基碼,編碼的具體實現為:
工件編號為1,2,3,…n;各工件的對應的工序編號為1,2,3,…k;對應的機床編號為1,2,3,…m.從而符號1.1.1則代表工件1的1工序在機床1上完成,以3(工件)×3(機床)為例:假如工件的加工工序最多為4,機床所對應不存在的加工工序則定義為0.0.0,工件的各加工工序要能滿足工序先后關系的約束.
3.2 生成初始種群與設計適應度函數
可以通過隨機產生的方法來產生初始種群,以便于達到解空間所有狀態的遍歷.對約束條件進行檢驗,判斷其是否為可行解,假如判斷結果為是,則將其加入初始種群,如果不是則淘汰.不過由于初始群體為隨機產生,因此進化的代數有所加大,從而遺傳算法的計算時間也相應大幅度增加.此處加入啟發式算法,將該算法局部搜索能力強的特點加以充分利用,從而優良個體產生的速度就有所提高.個體適應函數應為工件總加工時間單調遞減函數,即個體適應度的函數值隨著總工時的減小而增加,反之總工時越大,則個體適應度的函數值就越小.個體i的適應函數值可以進行以下定義:
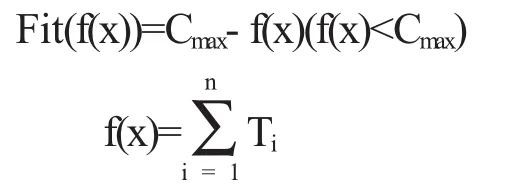
上式中:Cmax是f(x)的最大值估計.
3.3 交叉操作
交叉算子利用一點交叉運算,參與交叉運算的包括兩個個體母體M與父體F,按照自適應交叉概率Pc進行相應的交叉運算.記交叉運算兩個體體母體M及父體F,其經過交叉運算所產生的子代個體記為D與S,L是染色體的長度.整數p為隨機生產,且1 上式中:fmax:群體最大適應度值 favg:每代群體平均適應度值 f:要交叉的兩個個體比較大的適應度值. 算法的收斂程度和自適應調整為反向關系,因此防止算法收斂于局部最優十分有效,并且可以保存更優的進化結果. 利用互換變異進行變異操作,即整數m先隨機生成,其取值范圍為機床的數量.在該機器中隨機選擇某一工序,將該工序和相臨的工序進行互換.需要注意的是,在變異時要看相臨的工序是否為加工同一工件.其自適應變異概率Pm進行如下定義: 本文求解的目標為工件完工時間的最小化,其目標函數為: 其中 i=(1,2…n) 生產調度問題為NP問題,即可用多項式時間算法對其猜測準確性加以驗證,因此最優解確定算法相對較難確定.而且遺傳算法又具體備相應的優良特性,因此在車間生產調度問題方面,遺傳算法為后續的研究趨勢.本文所提出將啟發式規則融入遺傳算法的混合遺傳算法,在進行調度算法的求解過程中,即可以發揮遺傳算法的長處,又可以充分利用啟發式算法快速搜索的特點,從而取得了更優的分配效果,且通過實例可以證明,該方法所求解的調度結果相對較優. 〔1〕(日)玄光男,程潤偉.遺傳算法與工程設計[M].北京:科學出版社,2007. 〔2〕鞠全勇,朱劍英.基于混合遺傳算法的動態車間調度系統的研究[J].中國機械工程,2009(11). 〔3〕祁建程,楊建剛.并行混合遺傳算法在車間調度問題的應用[J].計算機應用與軟件,2011(1). 〔4〕丁書斌,李啟堂,徐繼濤,等.混合遺傳算法求解經典作業車間調度問題[J].煤礦機械,2007(1). 〔5〕楊開兵.多目標混合遺傳算法求解流水車間調度問題[J].電腦與信息技術,2008(6). 〔6〕張華,陶澤.基于混合遺傳算法的車間調度問題的研究[J].機械設計與制造,2005(3). TP18 A 1673-260X(2011)09-0018-02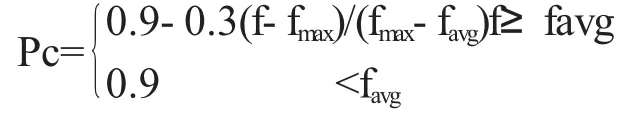
3.4 變異操作
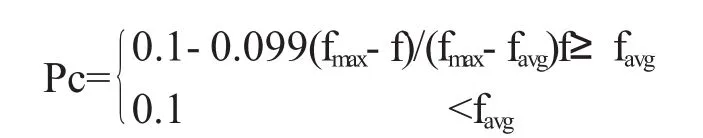
3.5 目標函數

4 結論
猜你喜歡
小主人報(2022年1期)2022-08-10 08:28:44
新作文·小學低年級版(2021年9期)2021-11-27 07:57:46
學生天地(2020年17期)2020-08-25 09:28:54
作文成功之路·小學版(2020年7期)2020-08-24 08:19:30
少年博覽·初中版(2020年6期)2020-06-12 11:42:23
作文成功之路·小學版(2020年7期)2020-01-02 10:10:44
趣味(數學)(2018年12期)2018-12-29 11:24:10
小學生作文(中高年級適用)(2017年10期)2017-11-13 06:01:00
能源(2016年2期)2016-12-01 05:10:46
故事大王(2016年7期)2016-09-22 17:30:08
