基于MS-VAR模型的就業影響因素非線性估計
2011-09-05 02:48:06羅孝玲楊懷東
統計與決策 2011年15期
羅孝玲,楊 立,楊懷東
(中南大學 商學院,長沙 410083)
0 引言
當前,就業問題已經成為經濟發展中最重要的問題之一,國內外對此進行了廣泛的研究。國外對就業問題的代表模型有貝弗里奇的結構性失業模型和菲利普.阿吉翁等提出的就業失業模型,總體上而言西方經濟學觀點認為經濟增長是就業增長必然會帶來就業增長【1】。劉新衛【2】利用道格拉斯生產函數驗證了我國經濟增長與就業的正相關關系。Pissarides【3】的研究表明,在勞動生產率處于上升階段時,增加勞動力會增加企業利潤,從而帶來就業增長。何靜慧【4】以浙江為例,研究了經濟增長和技術進步對就業的影響。張曉旭【5】運用偏離—份額方法分析1978年以來中國就業增長與產業結構變遷的關系,結果發現,對于就業增長而言結構成分占主導性作用。李曉嘉等【6】分析了我國產業結構和就業結構之間的互動關系,發現我國就業矛盾的原因主要在于我國的產業結構與就業結構不相稱,就業結構滯后于產業結構的發展。吳小松等【7】根據SDA模型對1987~2002年間我國就業增長與結構變遷的影響因素進行了實證分析從三次產業來看,第一產業的居民消費、第二產業的資本形成及第三產業的政府消費對各產業就業增長均有較大拉動作用。冉光和等【8】經驗分析出資本投入與勞動供需協調之間存在穩定的正相關關系,技術進步則與勞動供需協調呈穩定的負相關關系,偏離比較優勢的資本深化與技術進步弱化了就業促進功能并加速了勞動市場的分化。總體而言,國內外學者對就業問題進行了一系列的定性和定量分析,取得了階段性成果。
然而,由于宏觀經濟運行在特定經濟周期可能存在結構性變化或者結構性斷點,采用傳統的線性模型來研究就業的影響因素問題可能導致較大的偏差。因此,本文試圖摒棄傳統的線性建模思路,從研究變量的非線性特征入手,結合Ham ilton【9】分析宏觀經濟的思路,將我國宏觀經濟分為兩個狀態(擴張期和收縮期)進行研究。具體而言,本文運用格蘭杰因果關系檢驗和逐步回歸模型得到就業的主要影響因素,選擇非線性馬爾科夫狀態轉移向量自回歸模型(MS-VAR模型)研究不同狀態下就業與各個影響因素之間的關系,并在此基礎上研究就業在各個狀態下的轉換概率和狀態持續時間,從而為就業政策的提出提供理論支持。
1 就業水平影響因素的指標體系建立
1.1 就業問題評價指標(因變量Y)選取
就業是社會、國民經濟中極其重要問題。按已有研究,就業可以定義為三個月內有穩定的收入或與用人單位有勞動聘用關系。本文是對就業人數進行研究,所以選取就業人數作為就業問題評價指標。
1.2 影響因素指標體系建立
影響就業的因素可能有很多,這些因素之間內部可能也存在相互之間的關系,如何系統明了地對這些因素進行分析,找到主要的影響因素的首要條件是建立合理的指標體系。
1.2.1 指標體系建立方法選取
通過參考各關于指標體系的文獻,本文采用分層模式指標體系,將整個指標體系分為三層,第一層為目標層,第二層要素層,第三層為指標層;根據對各類指標的定性分析,可以認為該問題采用分層模式指標體系的目標層為“影響因素”。接下來討論研究要素層各要素的選取和定義。
1.2.2 要素選取
參考我國宏觀經濟指標體系,和訊網數據庫和研網數據庫,以及從宏觀角度看,消費、投資、政府購買和進出口都是影響就業的重要因素,再綜合文獻中的資料,可以提取以下可能影響就業的因素:
①消費;②投資;③對外貿易;④GDP和人口數等國民經濟核算指標;⑤經濟景氣指數。
在進行統計分析的過程中,各要素之間可能會存在相互之間的關系,所以要對以上五個要素進行篩選。本文選取就業影響的指標體系要素層的三個要素分別為:①消費;②投資;③對外貿易。
1.3 各要素主要指標初步選取
1.3.1 消費要素
根據宏觀經濟核算指標,了解到反映其消費要素的指標可能有:居民消費價格指數、衣著價格指數、糧食價格指數、居住價格指數、交通和通信價格指數,社會各種消費品零售總額和居民收入等。由于衣、食、住、行價格指數綜合起來就是居民消費指數,所以這幾個指標就可以選擇居民消費價格指數;社會消費品零售總額可以代表社會整體消費品水平,可以反映居民消費;而反映居民消費水平的要素可以包括居民實際收入和可支配收入,所以可以用其中1個指標表示,這里采用居民可支配收入這個指標。
1.3.2 投資要素
整體反映投資要素的指標是固定資產投資完成額,而固定資產投資包括中央和地方投資兩項,所以再選取另一個指標——地方項目資產投資完成額。
中央投入中教育科技等投資,間接影響了人力資本的強度,從而影響到就業,這一系列的影響過程涉及很廣,在接下來的模型中可以暫不考慮其影響。
市場利率是影響就業的一個很重要的指標,它可以直接影響投資情況,所以考慮將“市場利率”這個指標放入“投資”這個要素中。
1.3.3 對外貿易要素
對外貿易中的主要指標有進出口額,進出口總額,進出口差,其中進出口差最能反映對外貿易這個要素的情況,所以考慮只選取“進出口差”和“進出口總額”這個指標。
綜合以上分析,得到以下影響因素指標體系:

表1 影響就業因素指標體系
1.4 樣本選取
綜合各數據庫各指標的數據,由于年度數據樣本量太小(一般從1978~2008,且1989年前缺失值嚴重),本文選取月度數據(2001年1月~2008年12月)作為數學模型建立的所需的統計數據。數據來源于研網。
各影響因素指標可以查詢到月度數據,而根據就業的定義和數據庫中數據,只能得到就業人數的年度數據。本文中利用三次樣條插值法,利用2001~2008年的年度就業人數進行數據處理,得到2001年1月~2008年12月的月度數據。經過各數據整理,得到就業指標數據表如表2:
1.5 因果關系檢驗提取主要指標
通過以上定性的分析,我們選取了8個可能的主要因素指標,并選取了2001年1月~2008年12月的樣本數據,現將對這些樣本數據進行Granger因果關系檢驗,通過檢驗找到這8個指標中對就業人數影響的主要因素。
1.5.1 Granger因果關系檢驗原理
兩個時間序列的變量在時間上有先導——滯后關系,如何考察一個變量過去的行為是否在影響另一個變量的當前行為,或者雙方的過去行為在相互影響著對方的當前行為,Granger提出了一個簡單的檢驗程序,稱之為Granger因果關系檢驗。
對兩個變量Y與X,Granger因果關系檢驗要求估計以下回歸:
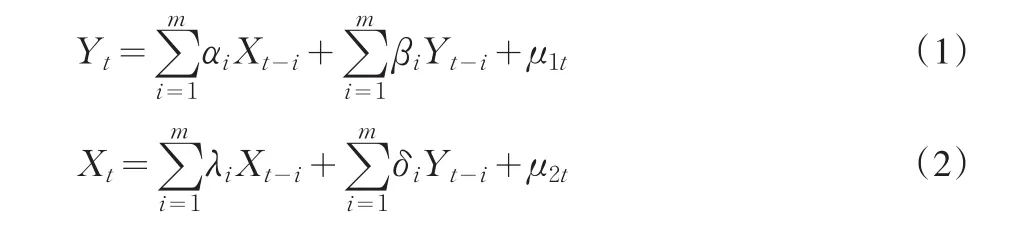
可能存在有四種檢驗結果:
(1)X對Y有單向影響,表現為(1)式X各滯后項前的參數整體不為零,而(2)式Y各滯后項前的參數整體為零;
(2)Y對X有單向影響,表現為(2)式Y各滯后項前的參數整體不為零,而(1)式X各滯后項前的參數整體為零;
(3)Y與X間存在雙向影響,表現為Y與X各滯后項前的參數整體不為零;
(4)Y與X間不存在影響,表現為Y與X各滯后項前的參數整體為零;
Granger檢驗是通過受約束的F檢驗完成的。如針對X不是Y的Granger原因這一假設,即針對(1)式中X滯后項前的參數整體為零的假設,分別做包含與不包含X滯后項的回歸,記前者的殘差平方和為RSSu,后者的殘差平方和為RSSR;再計算F統計量:

式中,m為X的滯后項的個數,n為樣本容量,k為包含可能存在的常數項及其他變量在內的無約束回歸模型的待估參考的個數。
如果計算的F值大于給定顯著性水平α下F分布的相應的臨界值Fα(m,n-k),則拒絕原假設,認為X是Y的Granger原因。
1.5.2 1Granger因果檢驗
表2中給出了就業人數和8個指標的樣本數據,對這些樣本數據進行因果關系檢驗。
用Eviews先對就業人數和固定資產投資完成額進行因果關系檢驗,得到以下結果(見表3):
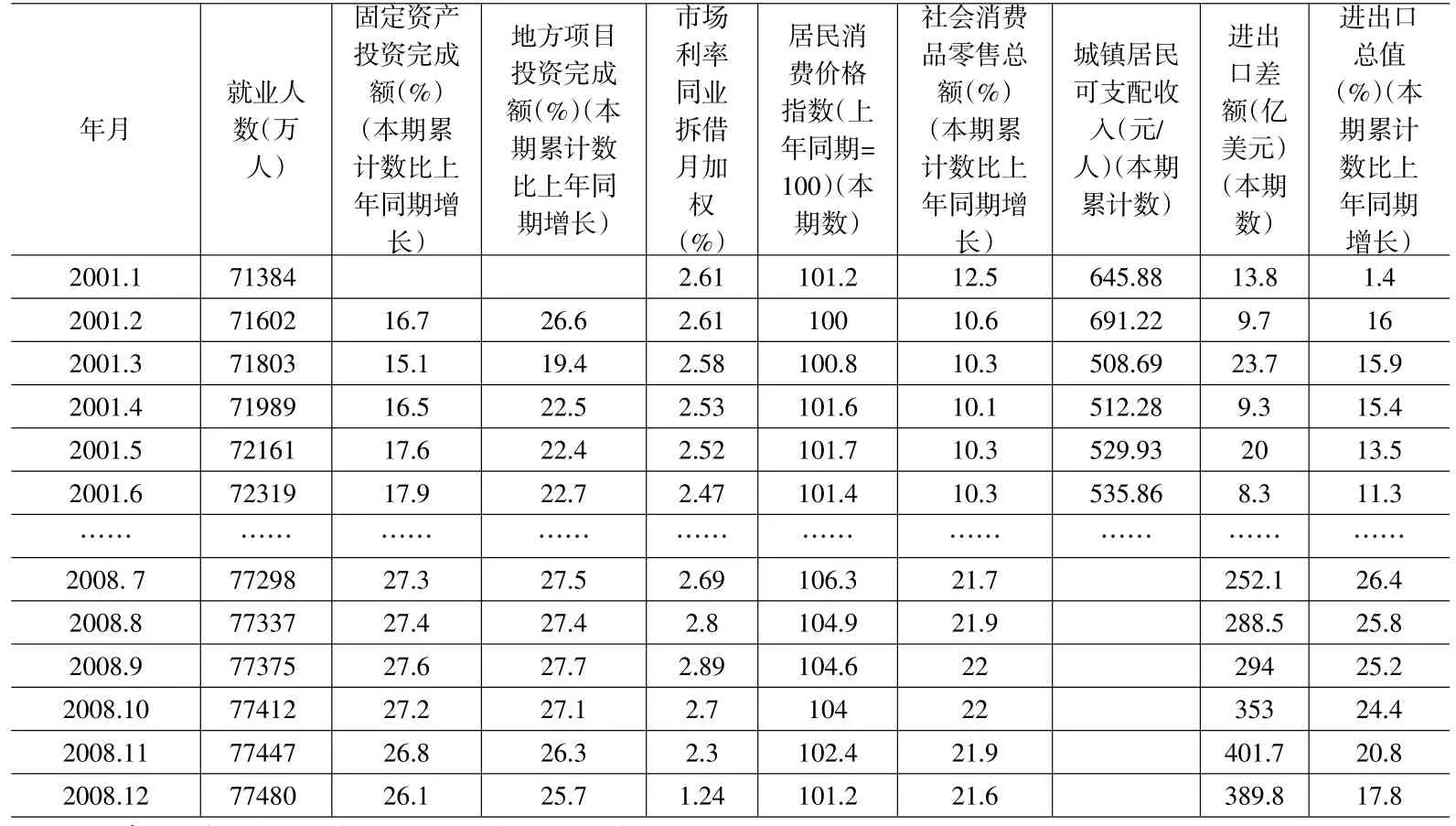
表2 就業指標表

表3 就業人數與固定資產投資完成額Granger因果檢驗結果表
由表3F檢驗的相伴概率可以看出,在5%的顯著性水平下,拒絕“X1不是Y的Granger原因”的假設,而不拒絕“Y不是X1的Granger原因”的假設。因此,檢驗結果為:固定資產投資額是就業人數的Granger原因。
同理,將就業人數與其他因素指標進行Granger因果檢驗,得到結果如表4:

表4 就業人數與各因素的Granger因果檢驗結果
綜上表明以下結論:
(1)固定資產投資總額、地方項目資產投資、市場利率、居民消費價格指數和社會消費品零售總額是就業人數的Granger原因,但是就業人數不是它們的Granger原因;
(2)城鎮居民可支配收入和進出口差額是就業人數的Granger原因,同時就業人數也是它們的Granger原因;
(3)進出口總額不是就業人數的Granger原因,就業人數也不是進出口總額的原因.
1.5.3 主要指標確定
以表4中的因果關系檢驗結論為依據,是就業人數的Granger原因的指標為影響就業人數的主要指標。則表示為如表5所示:
由上述分析可知,影響就業人數的相關因素由表5所示的7個,為了消除因素之間的多種共線性,以就業人數為因變量,表5中的影響因素為自變量,以2001年1月~2008年12月的全國月度數據為樣本,建立逐步回歸模型,得到以下回歸結果:
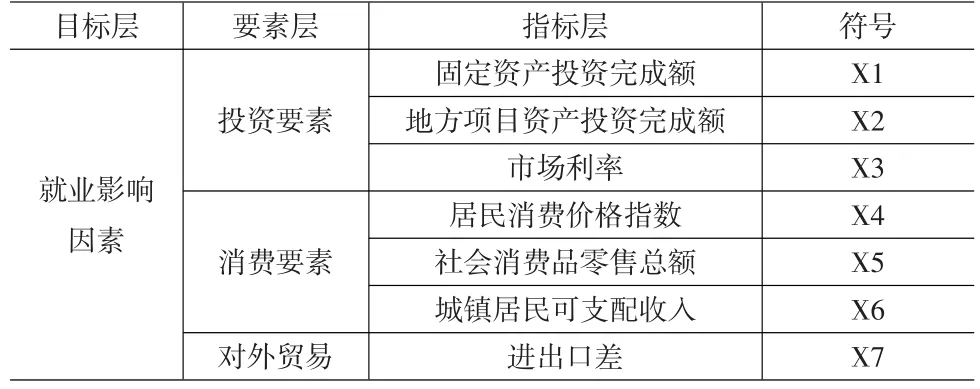
表5 影響就業人數的主要指標

由此可見影響就業問題的主要因素為x1,x3,x4,x6,x7,在后續的MS-VAR模型中,本文僅考慮這5個因素的影響。
2 馬爾科夫區制轉移向量自回歸模型的建立
2.1 馬爾科夫區制轉移向量自回歸模型的構建
自Sims(1990)提出向量自回歸模型(Vector Autoregression,VAR)以來,該方法在研究總體變量之間的關系得到廣泛的應用,而馬爾科夫區制轉移向量自回歸模型(MS-VAR)就是在向量自回歸模型(VAR)模型的基礎上加上馬爾科夫鏈(Markov Chain)特性的模型。
根據上面的分析,本文采用就業人數(Y1)、固定資產投資(Y2)、市場利率(Y3)、居民消費價格指數(Y4)社會消費品零售總額(Y5)和進出口差額(Y6)構建MS-VAR模型。這些指標可以構成6維時間序列向量Yt=(Y1t、Y2t、Y3t、…Y6t)。該時
間序列在狀態St可構建P階VAR模型,如式5:
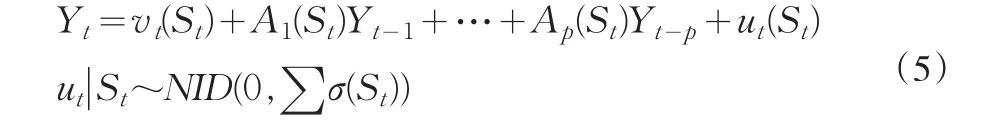
其中,St為狀態變量,vtSt為常數項,它來自不同狀態下的母體,Ai(St)為外生變量的系數向量。
結合經濟變量常有的兩狀態模式,可以假設本模型存在兩種狀態(擴張期和收縮期),當St=1時是擴張期,當St=2時是收縮期。馬爾科夫轉換模型的概念主要是由兩種概率分配混合產生數據,此種狀態改變的現象與Chow test的觀點有部分是相似的,但Chow test主張的是認為在t期的數據不是由狀態一就是由狀態二“獨立”產生,而并非由狀態一及狀態二混合產生,所以馬可夫轉換模型會較Chow test相對來得有彈性。兩狀態的馬爾科夫模型的狀態轉換矩陣可由式6加以表示:

其 中 ,0<P11、P12、P21、P22<1,且 P11+P12=P21+P22=1。Pij=P(St+1=j|St=i),i、j=1or2,表示狀態轉換的概率。本期(第t期)處于狀態i而下一期(第t+1期)轉換為狀態j的概率為Pij。
上面敘述的狀態變量St是無法觀察的,且轉換概率也是無法觀察,但可以用最大似然估計求出在各時點t的狀態概率值。
馬爾科夫轉換是可以用無法觀察的狀態變量來捕捉時間序列的數據產生過程(Data-Generating Process)。在馬爾科夫狀態轉換模型中的參數包含常數項、平均數與誤差項都會依狀態的改變而有所不同,因此我們可以依照研究本身的需求,來對于某些參數進行不同狀態改變的假設,來進行我們的實證分析。
2.2 馬爾科夫區制轉移向量自回歸模型的實證分析
在進行MS-VAR模型計算之前,先要保證樣本數據的平穩性,本文采用ADF檢驗進行,發現就業人數不是平穩序列,于是對其進行一階差分后檢驗得到平穩的結論。ADF采用Eviews6進行計算,具體檢驗結果見表6。

表6 ADF單位根檢驗

表7 滯后階數的判斷

表8 最佳MS-VAR模型的選擇
在對數據進行平穩化處理和平穩檢驗后,就可以求解模型了,本文采用OX軟件包中的MSVAR優化包,采用基于極大似然估計的EM算法進行估計參數。
在進行MS-VAR分析之前,必須先確定滯后階數(P),本文是根據MSM-VAR模型的AIC和SIC判斷準則來決定最適的滯后階數,由表7可知,當落后期數為1的時候,AIC值為22.5177,SIC值為24.4387,在滯后期數為4時,AIC值和SIC值相對較小,代表其模型配適性最佳,因此,本文選擇滯后期數為4的模型進行分析。
接下來通過AIC值、SIC值和LR Linearity值來判斷MS-VAR的模式,這些值的具體大小見表8。
從表8看出,MSIAH(2)-VAR(4)模型的AIC值和SIC值最小,且其LR Linearity統計量顯著,我們選擇該模型來研究,對應于兩種狀態,截距、方差和回歸系數都在發生變化。
由表9可知,當期處于狀態1(擴張期),下期維持狀態1(擴張期)的概率為0.9555,當期處于狀態1,下期轉換為狀態2(收縮期)的概率為0.0445,當期為狀態2,下期維持狀態2的概率為0.9778,當期為狀態2,下期為狀態1的概率為0.0222。
由表10可知,處于狀態1的平均概率為0.333,期望持續期為22.48個月;處于狀態2的平均概率為0.667,期望持續期

表9 狀態轉換概率

表10 狀態期望持續期和平均概率
為每45.02個月。可以看出,狀態2的平均概率和期望持續期都大于狀態1,這說明從總量上講,2001~2008年間,我國經濟的擴張期是短于收縮期的。
由于本文研究的核心是就業受其他因素的影響情況,因此文章僅提供MSIAH(2)-VAR(4)模型中就業人數增量(進行過差分處理)的參數表,由表11可知,在擴張期,就業人數的增量受到第一期到第四期就業人數增量、第二期和第三期固定資產投資、第四期利率、第三期和第四期物價指數、第一期和第二期消費總額、第一期進出口差額的顯著影響;在收縮期,就業人數增量收到第一期到第三期就業人數增量、第一期到第三期物價指數、第一期消費總額的顯著影響。
圖1給出了每個樣本觀測點分別在狀態1和狀態2的濾子概率以及相應的平滑概率和預測概率曲線。從圖1的上半部分看出,經濟狀態在2001年1月~2004年1月和2005年4月~2006年3月兩個時段處于擴張期,從圖1的下半部分看出,經濟狀態2004年2月~2005年3月和2006年4月~2008年12月兩個時段處于收縮期。結合國家統計局發布的中國企業景氣指數,該指數從2001年第一季度的118.56點上升到2004年第一季度的135.9點,成為一個明顯的擴張趨勢,該指數從2004年第一季度的135.9點下降到2005年第二季度的131.71點,成為一個收縮趨勢,給指數從2006年第一季度的131.5點下降2008年第四季度的107點,成為一個明顯的收縮趨勢。從與中國企業景氣指數的對比看,它與本研究得到的結論非常吻合,說明了采用MS-VAR模型對經濟狀態進行劃分的合理性。
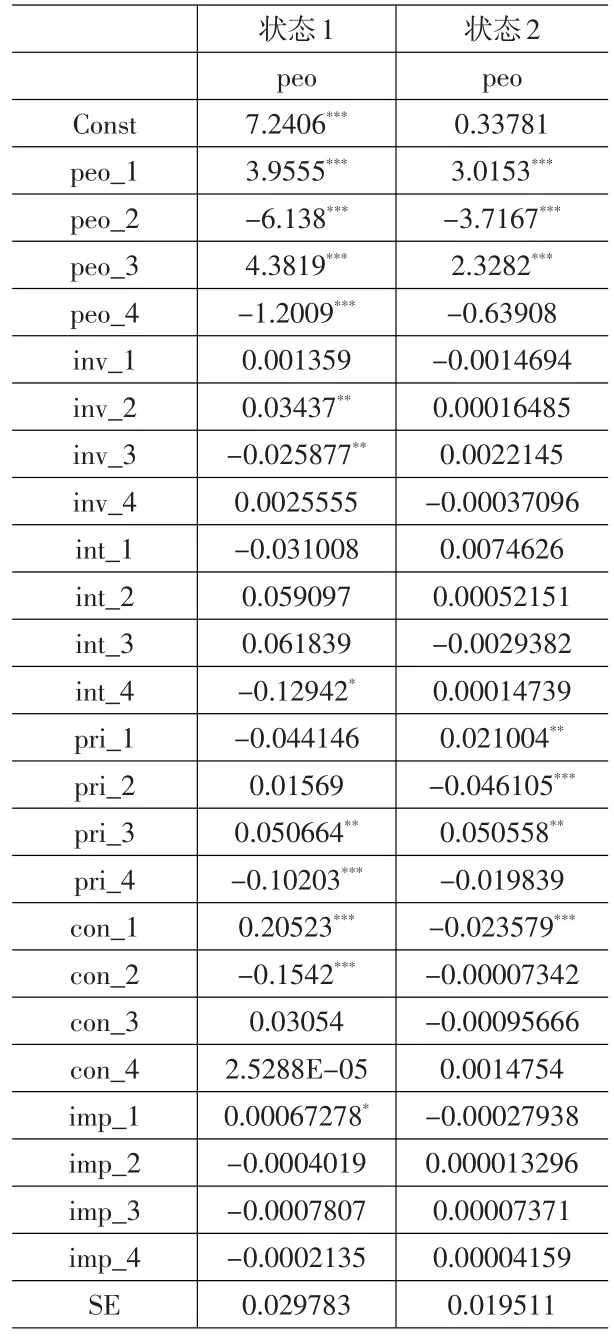
表11 MSIAH(2)-VAR(4)模型就業人數的參數

圖1 MSIAH(2)-VAR(4)模型狀態概率圖
3 結論與研究展望
本研究首先采用了格蘭杰因果關系檢驗和逐步回顧模型對影響就業的因素進行了篩選和驗證,得到五個影響就業的關鍵因素。在此基礎上,考慮到不同狀態下就業與其影響因素之間的關系會有所不同,建立了MS-VAR模型。從實證的結論看,最終建立的MSIAH(2)-VAR(4)模型能夠很好的區分經濟狀態,并給出了以下重要結論:
(1)在擴張期,就業人數的增量受到第一期到第四期就業人數增量、第二期和第三期固定資產投資、第四期利率、第三期和第四期物價指數、第一期和第二期消費總額、第一期進出口差額的顯著影響;在收縮期,就業人數增量收到第一期到第三期就業人數增量、第一期到第三期物價指數、第一期消費總額的顯著影響。
(2)處于擴張期的平均概率為0.333,期望持續期為22.48個月;處于收縮期的平均概率為0.667,期望持續期為45.02個月。
后續研究中,我們將考慮狀態的持續性,研究是否某一狀態持續的時間越長,其轉換為另一狀態的概率越大的期間相依現象。同時,將考慮加入誤差修正模型對MS-VAR模型進行拓展,研究就業的長期均衡和短期突變現象,為就業問題提供更多的決策依據。
[1]Martine Carre,David Drouot.Pace Versus Type the Effect of Economic Growth on Unemployment and Wage Pattern[J].Review of Economics Dynamics,2004,(7).
[2]劉新衛.就業增長率與經濟增長率關系的預測模型[J].科技創業,2008,(12).
[3]Pissarides Chirstopher A.Equilibirum Unemployment Theory[M].Cambridge:MIT Press,2000.
[4]何靜慧.經濟增長、技術進步與就業的關系——以浙江為例[J].統計與決策 ,2005,(10).
[5]張曉旭.中國就業增長與產業結構變遷關系的考量[J].統計與決策,2007,(24).
[6]李曉嘉,劉鵬.我國產業結構調整對就業增長的影響[J].山西財經大學學報,2006,(1).
[7]吳小松,范金,胡漢輝.我國就業增長與結構變遷的影響因素:基于SDA的分析[J].經濟科學,2007,(1).
[8]冉光和,曹躍群.資本投入、技術進步與就業促進[J].數量經濟技術經濟研究,2007 ,(2).
[9]Hamilton,James D.A New Approach to the Economic Analysis of Nonstationary Time Series and the Business Cycle[J].Econometrica,1989,(57).
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
中學生數理化·八年級物理人教版(2022年3期)2022-03-16 05:55:08
當代陜西(2021年2期)2021-03-29 07:41:24
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
媽媽寶寶(2017年3期)2017-02-21 01:22:28
光學精密工程(2016年6期)2016-11-07 09:07:19
中國塑料(2016年3期)2016-06-15 20:30:00
通信電源技術(2016年3期)2016-03-26 07:13:38
核科學與工程(2015年4期)2015-09-26 11:59:03
