新安江模型參數自動優化方法在淮河息縣站水文模擬中的應用
2011-08-07 09:13:20陳紅雨
治淮 2011年7期
王 凱 陳紅雨
在概念性水文模型的參數率定中,一般是用手工調試或計算機自動完成。要做好手工調試,必須有豐富的經驗,而且耗時費力,參數的優選不僅困難還會帶有主觀性。為了克服不同優化方法的缺點,近年來利用基因法、單純形法、復合形混合演化法等多種優化算法比較和結合的方式來準確地進行概念性水文模型參數優選的嘗試得到越來越多的重視和發展。本文選擇基因法、單純形法、復合形混合演化法及基因法結合單純形法四種優化方法分別對淮河息縣站新安江模型的產匯流參數進行率定,并對結果進行分析比較。
一、參數優化算法簡介
基因法是一類借鑒生物界自然選擇和自然遺傳機制的隨機化搜索算法,它模擬基因重組與進化的自然過程,把待解決問題的參數編成二進制碼,稱為“基因”,若干“基因”組成一個“染色體”,許多“染色體”進行類似于自然選擇、配對和變異的運算,經過多次重復運算,直至得到最優的結果。基因法通過“染色體”的“基因突變”,能跳出局部最優解,最終有可能收斂到全局最優解。
單純形法通過求出單純形n+1個頂點上的函數值,確定出函數最大值點(最高點)和函數最小值點(最低值點),然后通過反射、擴展、收縮等方法求出一個較好點,取代最高點,構成新的單純形,或者通過向最低點收縮形成新的單純形,以此來逼近最小點。
復合形混合演化法由自然界中的生物競爭進化原理和遺傳法的基本原理等概念綜合而成。該法開始時在參數可行域中引入隨機分布的點“群”,將這些點群分成幾個“復合形”,每一個“復合形”都獨立地根據下降單純形法進行“進化”,定時將整個群體重新混合在一起,并產生新的復合形,如此進化和混合不斷重復進行直到滿足設定的收斂準則為止。
二、新安江模型參數優選方法選用
三水源新安江模型作為一種概念性流域水文模型,從1981年問世以來,在南方濕潤地區得到廣泛的應用,是一種普遍認為精度較高的模型。由于此模型內部的產匯流參數有較強的地區性特征,因而不宜直接移用。三水源新安江模型的難點,不在其模型結構的本身,而在確定合適的產匯流參數。因此,如何根據實測水文資料來確定模型參數是模型應用中的主要問題。
新安江模型參數大多具有明確的物理意義,從理論上或概念上可以通過實測確定,但目前一方面由于缺乏實測值,一方面由于模型對實際的水文物理過程進行了概化,有些參數并不是反映單一過程或單一影響因素的結果,因而不大可能通過實測確定,只能依靠系統方法,用最優化技術求解。本文選用基因法、單純形法、復合形混合演化法進行參數優化,并對結果進行比較分析。
1.參數值域
對于濕潤地區,流域水文現象按其性質一般可分為蒸散發、產流、分水源、匯流4個層次。三水源新安江模型中共有16個參數:蒸散發的參數有K、WUM、WLM、C;產流的參數有WM、B、IM;分水源的參數有 SM、EX、KG、KI;匯流的參數有 CG、CI、UH、KE、XE。本文不討論單位線UH以及馬斯京根中KE和XE的率定方法,只討論前13個參數的率定。待優化參數意義及值域見表1。
2.目標函數
目標函數是用于評價實測與估算流量過程的擬合程度,其選擇主要取決于對模型成果的要求,常用的目標函數有:
式中,Qci與Qoi分別為計算與實測值。本文選用的目標函數為:
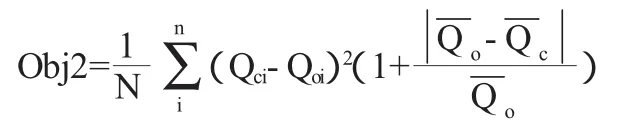
3.參數優化準則
當目標函數選定后,需要設置終止優化法的準則,本研究所采用的準則為:①最大迭代次數IMAX;②目標函數值的收斂容差TOLF;③參數迭代步長收斂容差TOLL。根據相關文獻,本研究中上述三個準則的值分別取IMAX=5000、TOLF=10-5、TOLL=10-6。當滿足上述其中任意一個準則時,優化過程終止。
三、參數優化結果與比較分析
為分析不同優化方法的特點,本文將上述三種優化算法及基因法結合單純形算法共四種優化方法分別應用于淮河息縣流域的降雨徑流模擬中。息縣站位于淮河上游,屬亞熱帶向暖溫帶過渡形氣候。流域面積8826km2(扣除南灣水庫面積),以上河道長度255km,在上游119km處有長臺關水文站。流域內有雨量站17個,年平均降水量1145mm左右。
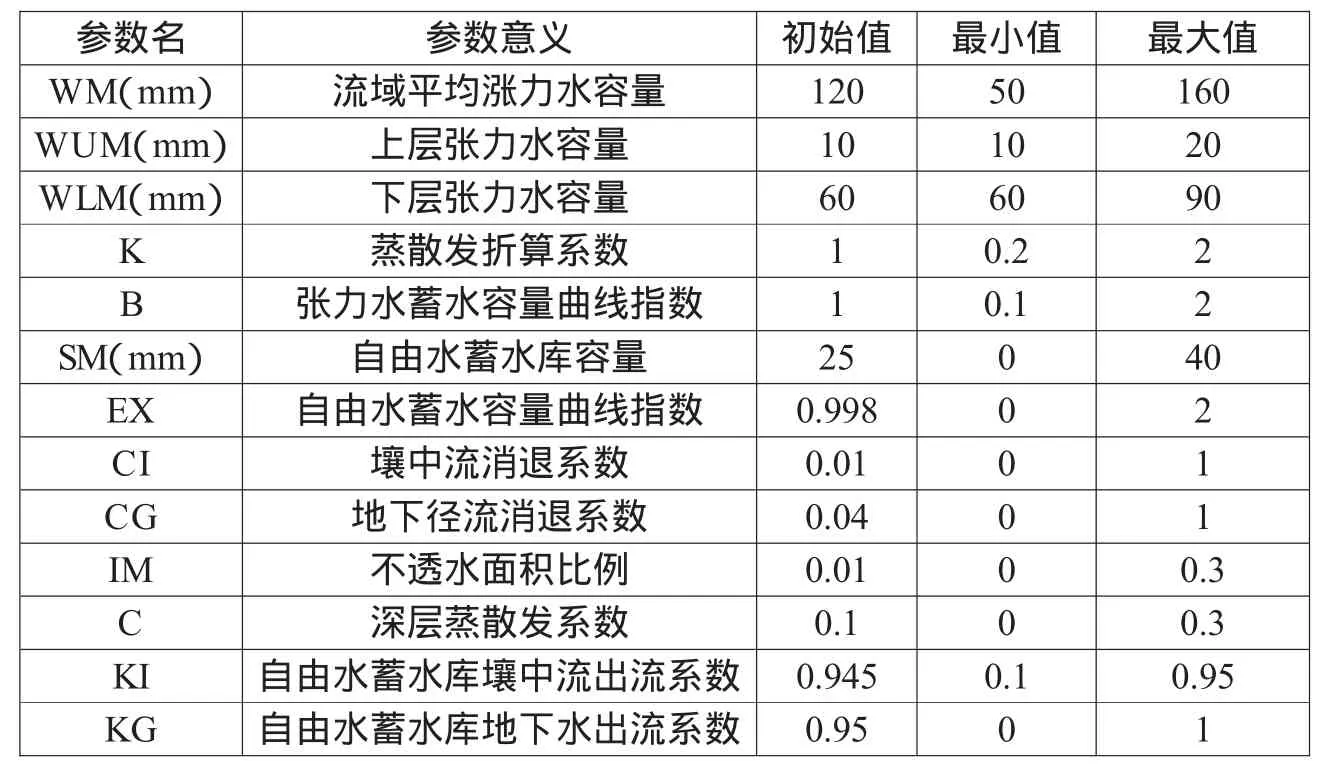
表1 三水源新安江模型參數意義及值域

表2 參數率定結果及優選指標
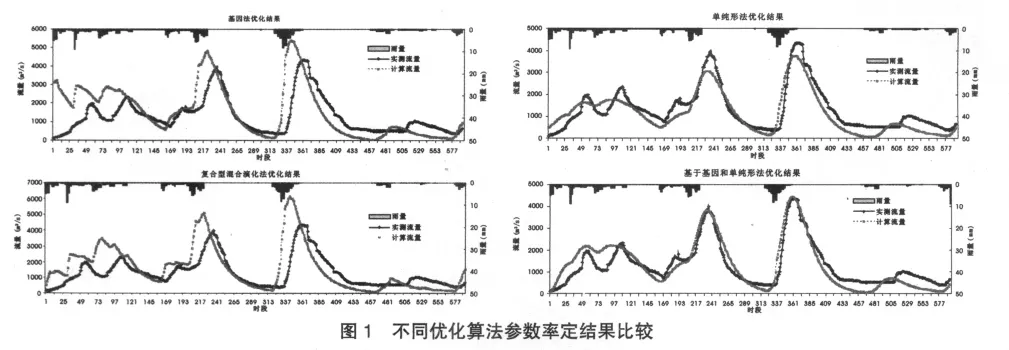
選取2007年6月30日9時~7月25日0時的洪水資料,進行模型的參數自動率定,計算時間步長為1h,共592個計算時段,率定期為1~400時段,驗證期為401~592時段。參數率定結果及優選指標如表2所示。不同優化算法參數率定結果比較見圖1。
由表2及圖1綜合分析,結合優選計算實際過程得出:①就精度而言,無論是確定性系數、水量平衡系數還是洪峰合格率,基因法結合單純形法精度最高,單純形法次之,復合形混合演化法再次之,基因法最差。②就運算速度而言,單純形法的運算速度最快,復合形混合演化法次之,基因法最慢。③參數初值的選定對基因法的影響較小,而對單純形法的影響則較大。因此,在進行概念性水文模型參數自動優選時,在用基因法進行全局優化時,可結合單純形法提高其局部搜索能力,或用基因法優選出的值作為單純形法的初始參數值提高其全局優化能力。
四、結論
通過三種優化算法的比較分析及其在淮河息縣流域降雨徑流的應用,得出以下結論:
①參數自動優化方法克服了試算法費時、所優選參數帶有主觀性的缺點,只要根據模型參數的物理意義,給出優選參數的合理取值范圍,自動優選方法就能夠得到最優的參數值。
②3種優化算法中以單純形法的運算速度最快,復合形混合演化法次之,基因法最慢;參數初值的選定對基因法的影響較小,而對單純形法的影響則較大;各方法以基因法結合單純形法精度最高,單純形法次之,復合形混合演化法再次之,基因法最差。
③綜合上述3種算法的優點,在進行概念性水文模型參數自動優選時,建議以基因法的優選結果作為單純形法的初值,然后再進一步優化,可得到模型參數的最佳值。
④流域水文模型參數的優化問題不僅僅是優化方法的問題,還涉及到資料質量問題,目標函數問題以及模型結構問題等。通過研究,算法要搜索到穩定的全局最優參數組通常需要16年以上的資料。同時,算法搜索結果也受到目標函數的影響。因此,適合的目標函數、高質量的實測資料以及避免優化參數相關性是獲得模型全局最優參數組的有力保障(本研究由國家水體污染控制與治理科技重大專項(2008ZX07010-006)、水利部2009年公益性行業科研專項(200901027)共同資助)
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
房地產導刊(2022年5期)2022-06-01 06:20:14
建材發展導向(2021年12期)2021-07-22 08:06:48
建材發展導向(2021年7期)2021-07-16 07:07:52
中學生數理化(高中版.高二數學)(2021年12期)2021-04-26 07:43:48
中學生數理化(高中版.高考數學)(2021年12期)2021-03-08 01:28:50
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
光學精密工程(2016年6期)2016-11-07 09:07:19
核科學與工程(2015年4期)2015-09-26 11:59:03
