上海光源產品管理系統及其全文檢索子系統的改進
2011-03-24 05:34:08佟興帆鄧輝宇李志明
核技術 2011年7期
關鍵詞:系統
佟興帆 鄧輝宇 李志明
(中國科學院上海應用物理研究所 上海 201800)
上海光源(Shanghai Synchrotron Radiation Facility, SSRF)的開發建設及長期維護、改進,對信息化系統有很高要求,如數據庫系統、數據管理系統(Product Data Management,PDM[1])、項目管理等。其中,數據管理系統具有重要地位,借助PDM 項目的實施,能完善SSRF對海量數據的管理,將研發流程電子化,通過流程控制任務的進行和數據發放可提高管理水平、完善信息化體系。
PDM 產品數據管理是計算機應用領域的重要技術之一,是以軟件技術為基礎,以產品為核心,對產品相關的數據、過程和資源一體化的集成管理技術。目前流行的 PDM 軟件有 PTC公司的Windchill, UGS公司的Teamcenter和IBM公司的PM等[2]。本文采用UGS公司的 Teamcenter平臺搭建PDM。通過SSRF-PDM系統的實施和應用,達到如下總體目標:數據集中管理及有效的版本控制;實現分級權限控制、快速檢索功能、遠程檢索和查閱工程文件;實現技術管理文件批轉審批功能;完成各種文檔格式轉換并能使用統一文檔瀏覽器;實現網上高速文件收發;完成與加速器實時數據庫的連接。
現有的基于Teamcenter的PDM系統的檢索結果是無序的。而對于檢索系統而言,排序是一個核心問題(SSRF的海量數據查找尤為如此)。另一方面,目前的檢索結果還存在滿意度不高(尤其是對中文)、無匹配程度控制、使用率低、不能模糊匹配等問題。本文通過引進Lucene[3]完善系統的檢索效果。
1 SSRF-PDM
1.1 系統結構
上海應用物理研究所網絡(圖 1)的所有客戶端計算機和服務器同在一個局域網內,主干網帶寬1000M,服務器和主干網間的帶寬1000 M,而客戶端計算機和主干網間的連接的帶寬為 100M。根據SSRF目前的硬件配置情況,SSRF-PDM 系統服務分布在兩臺服務器上:DB服務器以及PDM服務器。通過VPN連接兩個園區。

圖1 SSRF-PDM系統網絡結構Fig.1 SSRF-PDM network structure.
1.2 服務器和客戶端模塊配置(圖2)
SSRF-PDM 系統構建采用美國 UGS公司Teamcenter Engineering 2005 SR1(以下簡稱TCEng2K5SR1),由于要和SSRF目前的Solid Edge、AutoCAD、Protel、TCEngVis(Teamcenter Engineering Visualization的簡稱)進行集成,所以選擇Rich Client模式進行部署。在 PDM 服務器上,還要安裝和配置第三方的服務,如HTTP Service、App Service等。
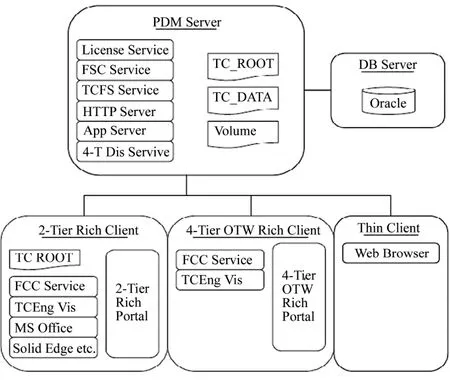
圖2 SSRF-PDM服務器和客戶端模塊配置Fig.2 SSRF-PDM server and client module configuration.
1.3 客戶端運行模式
SSRF-PDM系統提供 2種模式的 Rich Client(2-Tier Rich Client和4-Tier Rich Client)和 1種模式的Thin Client(Web Client)。2-Tier Rich Client需要在每一臺客戶端機器上單獨安裝 Portal和 TC Server服務(TC_ROOT),具有完全的功能,支持Solid Edge Manager、AutoCAD Manager、TCEng Vis、MS Office以及各種應用軟件的集成。4-Tier Rich Client以OTW(Over The Web)方式通過瀏覽器從服務器上自動安裝,并在服務器配置發生變化的時候自動完成系統更新。4-Tier OTW Rich Client方式不支持UG NX2 Manager和AutoCAD Manager,支持TCEng Vis。要求所有的OTW客戶端將TCEng Vis安裝在相同的本地目錄中,其有些PDM功能受到限制。TCEng2K5SR1的Thin Client方式不在客戶端安裝任何軟件,對客戶端要求最低,只要客戶端有 Web瀏覽器,就可以通過瀏覽器訪問SSRF-PDM系統。Thin Client方式可以在WAN環境使用,只要有Internet連通就可使用PDM系統,較宜于遠程使用。但是,這種方式主要用于數據瀏覽,不具有數據創建功能。
2 檢索系統的改進
系統配置完畢運行測試時,發現SSRF-PDM系統自帶的檢索系統檢索效果不理想。主要有如下問題:(1) 現有SSRF-PDM系統的檢索結果無序; (2)檢索結果滿意度不理想(尤其是對中文); (3) 無匹配程度控制,輸出大量無關信息;(4) 使用率低;(5) 對于某些格式的文件不能進行檢索(比如.dwg)。

圖3 Lucene的索引流程Fig.3 Lucene indexing process.
經調研,我們發現 Lucene是個很好的檢索工具,可進行增量索引(Append),可對大量數據進行批量索引,可實現排序,且接口設計可用于優化批量索引和小批量的增量索引;能非常靈活的適應各種應用(只需前端有合適的轉換器把數據源轉換成相應結構);對中文檢索的效果比較好。Lucene的索引流程如圖3所示。
2.1 Lucene的索引與SSRF-PDM檢索算法比較
SSRF-PDM自帶檢索工具所使用的算法,未建立很好的索引機制。它采用前向索引方式,即每個文檔對應著該文檔所包含的詞或者短語的列表;Lucene采用的是反向索引(inverted index)機制,文檔中的每個詞或短語對應著一個文檔列表,該列表中的文檔是所有包含該詞或短語的文檔。該列表還會包含一些輔助信息,比如該詞或短語在文檔中出現的次數以及出現的位置等。這些信息會被用來對搜索結果進行排序。這種結構對于“哪些文檔中包含單詞X”這樣的問題能快速得到搜索結果。
文本形式的文獻正文轉換為該文獻中每個漢字在正文中位置索引信息列表,也就是從文本空間到位置空間的轉換。此后每當用戶輸入一個詞句時,算法就以檢索詞句的第一個字為基礎,采用前方一致的方式搜索該漢字的索引,若無該漢字,則立即顯示落選信息;若有該字,則根據該字的記錄字段信息取出主文檔中的響應記錄,采用子字符串搜索函數,確定記錄中是否有該詞句。重復以上過程,直至命中的單字結果信息處理完畢。良好的索引機制和檢索算法,使Lucene檢索的速度得到提高。
2.2 Lucene向量空間模型[4]
將文檔和用戶的查詢語句都表示成向量之后,就可利用文檔向量和查詢向量間的相似性來表示文檔和查詢間的相關性。為衡量文檔向量和查詢向量間的相似性,較常用的方法是使用余弦系數(cosine coefficient)。它可表示為:

該算法用兩個向量的夾角的余弦值來表示兩個文檔之間或者文檔與查詢向量之間的相似程度。利用該算法,向量空間模型就能夠計算出系統中的每個文檔向量和查詢向量的相似程度。計算結果的數值在0–1間,值越大說明相似程度越高,也說明這個文檔和查詢之間的相關性越高,這樣就可以對查詢結果進行排序,把相關性高的搜索結果排在前面。
該算法解決了系統自帶的檢索工具不能進行相關度排序的問題。因為自帶工具只要檢索到與輸入關鍵字一致的結果便顯示輸出,不會進行繼續對全文遍歷而進行相關度計算,而對于海量的 SSRFPDM系統,結果排序是重要問題之一。
2.3 中文分詞算法[5]
SSRF-PDM系統自帶檢索工具,由于不是為中文檢索設計,對中文的查找效果遠低于英文,而上海光源的很大一部分資料都是中文記錄,所以需加入中文檢索功能。由于中文不同于英文,詞與詞中間沒有空格間隔,所以要分詞后才能進行檢索查找。Lucene提供的算法如下。
假設對 S=S1S2S3S4…… 進行正向最大匹配分詞, 其分詞算法可通過如下步驟進行:
(1)取一字 S1, 在詞表中查找 S1。并保存是否成詞標記;
(2)再取一字 S2 , 判斷詞表中是否有以 S1 S2為前綴的詞;
(3)不存在, 則S1 為單字, 一次分詞結束;
(4)存在, 判斷S1S2是否為詞, 并取以S1S2 為首的多字詞的個數n;
(5)如n為0, 一次分詞結束;
(6)否則再取一字 Si, 判斷詞表中是否有以S1S2….Si為前綴的詞;
(7)若不存在, 則返回最近一次能夠成詞的S1S2….Si-1
(8)否則轉(6);
(9)從字Si開始下一次分。
通過加入中文詞典與中文分詞,該系統對中文檢索的效果大為提高。
3 檢索系統的實現
為將 Lucene應用于 SSRF-PDM,開發了如下文件[6]。
3.1 CreateIndex.java
CreateIndex.java實現索引建立,為允許數據文件夾中出現文件夾嵌套,使用了遞歸的結構:構造方法調用private void indexDocs(File dataDir, String indexDir)進行索引建立,在 indexDocs方法中,將判斷當前傳入文件參數dataDir是目錄還是文件,如果是前者,則遞歸調用indexDocs方法,否則調用indexFile方法。indexFile方法進行文件索引,在建立索引之前,首先判斷索引文件是否存在,若索引文件不存在,則建立新的索引文件夾和索引文件,若索引文件存在,則在原索引基礎上進行增量索引。
由于Lucene提供的增量索引機制的問題,在進行增量索引時,需進行先期處理:我們在建立索引時加入了名為information的field,它由文件的絕對路徑和最后修改時間連接而成,能唯一確定一個文件,在進行增量索引時,需先判斷當前索引是否已對當前文件建立了索引,否,就直接建立新的索引;是,則需將已建立索引刪除后對當前文件建立新的索引,否則會出現重復索引的問題。
Lucene為實現全文檢索,提供了一些特定的數據結構,包括document, field, term等,索引和搜索時只需新建或者操作這些數據結構即可。
3.2 indexSearch.java
indexSearch.java實現搜索和搜索結果的排序。軟件要求對搜索結果進行排序,Lucene的搜索結果默認按照相關度降序排列,為提供相關度的升序排列,我們新建了一個SortField,分別用兩種排列方式對其進行實例化,并用此 SortField實例化一個Sort類。
3.3 LuceneDOCDocument.java
LuceneDOCDocument.java實現doc格式文件的轉化,靜態方法 getDocument返回一個 lucene的document類型。LucenePDFDocument.java,LuceneEXCELDocument.java,LucenePPTDocument.java三類分別實現pdf, xls, ppt格式文件的轉化,靜態方法 getDocument返回一個 lucene的 document類型。
3.4 LuceneSearcher.java
LuceneSearcher用于軟件GUI的實現。針對某些圖片文件,比如Solid edge生成的.dwg,我們采取標題檢索的方式找到圖片即可。
4 檢索系統測試[7]
通過對原PDM系統全文檢索和Lucene改進的全文檢索進行對比實驗,如圖4,可見改進后的Lucene全文檢索能將查詢結果按照匹配評分的高低排序給出,而原 PDM 系統全文檢索查詢結果為隨機排列。改進后的評分和排序機制,基本實現了最相關的檢索結果與用戶需求目標相匹配。Lucene全文檢索克服了 PDM 系統一次只能對某一種格式文件進行檢索的不足,可同時對MSWord、MSExcel、MSPowerPoint等不同類型文件進行全文檢索。

圖4 原PDM系統全文檢索結果(左)與 Lucene改進的全文檢索結果(右)Fig.4 Full-text search results by original PDM system (left) and the results improved by Lucene (right).
5 結論
為了完善上海光源對海量數據的管理、將研發流程電子化,進行了產品數據管理系統(PDM)的開發。針對傳統基于Teamcenter的PDM系統檢索結果無序、檢索結果滿意度不高、無匹配程度控制、使用率低、不能模糊匹配等問題,引進了 Lucene檢索系統,結果表明,Lucene能顯著改善檢索效果。下一步將繼續對檢索效率與檢索文件類型進行改善。
1 熊琦.產品數據管理PDM系統功能與應用分析.電腦知識與技術(學術交流)[J].2007,4(19):10 XIONG Qi.Product data management system function and application analysis [J], Computer Knowledge and Technology, 2007,4(19) :10
2 賈廣飛, 楊鐵男.PDM的發展現狀及其CIMS中的應用[J].河北工業科技.2002, 19(6): 35–38 JIA Guang-fei,YANG Tie-nan.Status and development of PDM and its application in CIMS[J], Hebei Journal of Industrial Science and Technology, 2002, 19(6) : 35–38
3 Otis Gospodnetic, Erik Hatcher.Lucene IN ACTION [Z].2006, 212–252
4 周登朋,謝康林.Lucene搜索引擎[J].計算機工程.2007.33(18): 95–96 ZHOU Dengpeng, XIE Kanglin [J].Lucene search engine,Computer Engineering, 2007.33(18): 95–96
5 王繼明,楊國林.基于 Lucene的中文文本分詞[J].內蒙古工業大學學報.2007, 26(3): 185–188 WANG Jiming,YANG Guolin.Chinese automatic wordcut base on Lucene [J], Journal of Inner Mongolia University of Technology, 2007, 26(3): 185–188
6 蘇潭英, 郭憲勇, 金鑫.一種基于 Lucene的中文全文檢索系統[J].計算機工程.2007, 33(23): 94–96 SU Tanying, GUO Xianyong, JIN Xin.Chinese full-text retrieval system based on Lucene [J], Computer Engineering, 2007, 33(23): 94–96
7 石磊.SSRF-PDM系統安裝配置文檔[Z].2008, 1: 1–3 SHI Lei.Configuration files of SSRF-PDM[Z], 2008, 1: 1–3
猜你喜歡
工業設計(2022年8期)2022-09-09 07:43:20
軍民兩用技術與產品(2021年10期)2021-03-16 06:05:30
北京測繪(2020年12期)2020-12-29 01:33:58
裝備制造技術(2019年12期)2019-12-25 03:06:46
制造技術與機床(2019年10期)2019-10-26 02:47:06
中國洗滌用品工業(2019年4期)2019-05-11 09:27:34
鐵道通信信號(2018年5期)2018-06-28 03:06:24
家庭影院技術(2017年9期)2017-09-26 03:41:45
知識經濟·中國直銷(2017年5期)2017-06-15 20:28:19
通信電源技術(2016年6期)2016-04-20 06:21:32
