一種快速KMSE算法及其在異常入侵檢測中的應用
2011-03-12 14:05:00范自柱徐保根
哈爾濱工業大學學報 2011年3期
范自柱,徐 勇,徐保根,朱 旗
(1.哈爾濱工業大學深圳研究生院,518055廣州深圳,zzfan3@yahoo.com.cn; 2.華東交通大學基礎科學學院,330013江西南昌)
核方法[1]的基本思想是將輸入空間通過某種非線性映射變換到一個高維的特征空間,借助于“核技巧”[2]在新的空間中應用線性分析方法.“核技巧”最早應用于支持向量機(Support Vector Machines,SVM)中.隨后,基于核的主分量分析(Kernel Principal Component Analysis,KPCA)[3]、基于核的Fisher鑒別分析(Kernel Fisher Discriminant Analysis,KFDA)[4]和基于核的最小均方誤差(KMSE)[5]等核學習方法被提出.實際上,KMSE模型可以看作是在核主分量分析基礎上實施特征提取的過程,而且在形式上它等效于最小平方支持向量機(Least Squares Support Vector Machines,LS-SVM)[6]與核鑒別分析.當樣本數趨于無窮時,KMSE模型將以最小均方誤差逼近特征空間中的貝葉斯判別函數.
根據再生核理論,KMSE模型在特征空間中的鑒別向量是此空間中樣本的線性組合.相應地,KMSE模型對一個樣本的特征抽取結果為該樣本與所有(訓練)樣本間核函數的線性組合.因此,KMSE特征抽取效率與訓練集的大小成反比.為了提高學習效果,人們往往需要數百甚至成千上萬個樣本進行學習(訓練),而這樣大規模的訓練集無疑會大大降低KMSE的特征抽取效率.針對這一問題,一些關于核的優化算法[7-10]被相繼提出.本文首次將KMSE和其快速算法應用于異常入侵檢測[11]這一信息安全領域,在經典的入侵檢測實驗數據集KDDCUP1999上的實驗結果表明,KMSE是一種有效的異常入侵檢測方法,經改進后得到的快速KMSE方法檢測效率非常高,檢測結果十分理想.
1 KMSE模型
KMSE是對傳統的最小均方誤差(MSE)應用核方法而得到的.本文主要考慮2類問題:假設在n個訓練樣本 x1,x2,…,xn中,前 n1個屬于第1類,類別標識為1;其余的n2個屬于第2類,類別標識為-1,且n1+n2=n.這些樣本經過一非線性映射φ(·)得到特征空間中的2組樣本: φ(x1),φ(x2),…,φ(xn1)對應第1類;φ(xn+1),…,φ(xn)對應第2類.則KMSE模型為

其中:
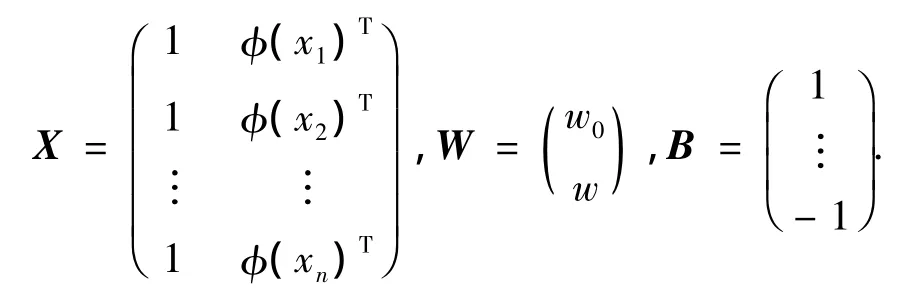
式中:W為特征空間中的鑒別方向;w為鑒別矢量;w0為閾值權;B中1的個數為n1,-1的個數為n2.根據再生核理論,W可以看作為閾值權w0與特征樣本的線性組合[13],式(1)中的W變為
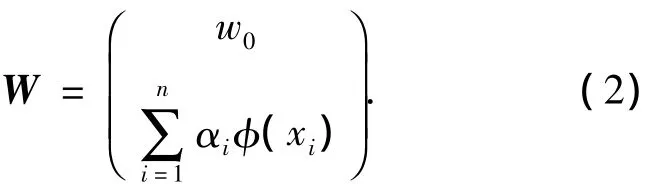
因此,借助核函數k(x,xi)=(φ(x)· φ(xi)),式(1)可以改寫為

其中:
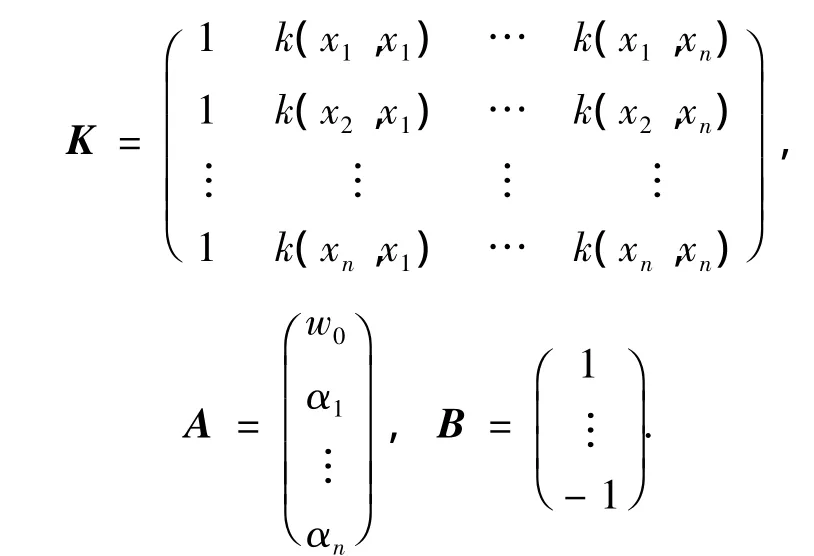
式(3)的最小二乘解的一般形式為
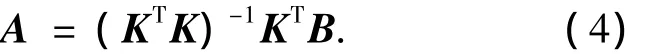
由于KTK是病態矩陣,所以需要引入一正則項μ,則式(4)變為
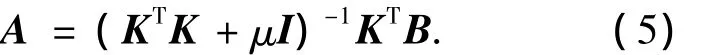
式中:I為單位矩陣;A即為將min(μATA+(BKA)T(B-KA))作為目標函數得出的解.根據式(5)求出A后,便可實現分類.設有一待測模式x,它在鑒別方向上的投影為
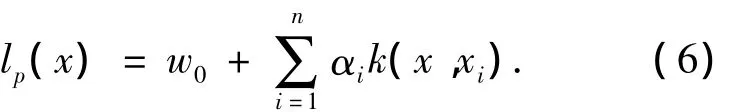
當lp(x)>0時,將x分到第1類,其類標記為1;否則,它被分到第2類,其類標記為-1.
2 KMSE的快速算法(FKMSE)
由式(2)知,如果要確定一個樣本的類別,需要把它與所有訓練樣本的點積求出,才能判別其類別.當訓練樣本非常多時,若要給大容量的測試集分類,顯然,其效率是不高的.在輸入空間中,訓練樣本的維數一般不是很高.由線性相關性理論,n+1個n維向量必線性相關,所以,當訓練樣本的個數大于其維數時,訓練樣本間必然存在線性相關性.根據線性相關理論,得出下面的結論:
定理1 對于特征空間F中的一組向量: φ(x1),φ(x2),…,φ(xr)∈F,如果它們線性相關,即存在一組不全為0的數:l1,l2,…,lr∈R,使得:

則有
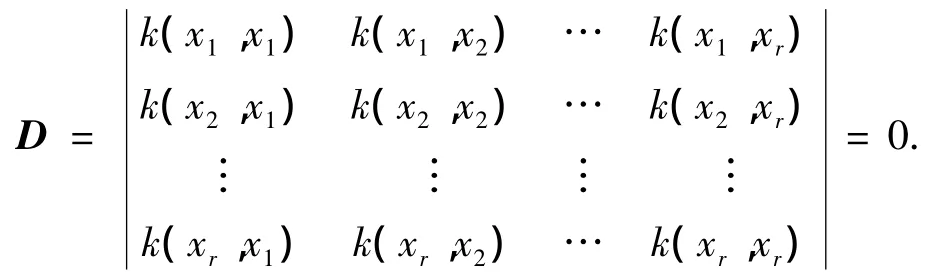
證明 依次用φ(x1),φ(x2),…,φ(xr)乘式(7)左右兩邊,得:
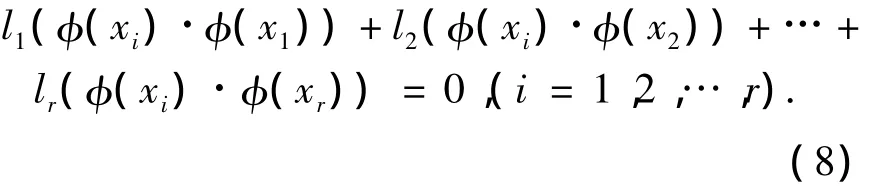
定義核函數k(x,xi)=(φ(x)·φ(xi)),得出齊次線性方程組為

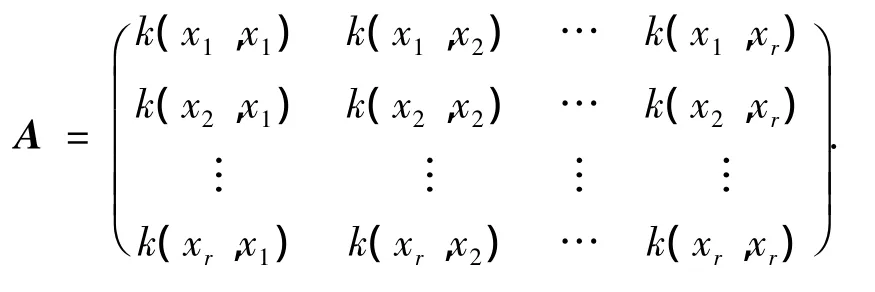
其中,L=(l1,l2,…,lr)T,顯然,A是方陣,根據求解線性方程組的Crame法則,齊次線性方程組若有非零解,則det(A)=0,即D=0.由題設,l1,l2,…,lr不全為零,也即是式(9)有非零解,所以有D=0.得證.
定理1的逆否命題也很有用,即:若D≠0,則φ(x1),φ(x2),…,φ(xr)線性無關.
利用定理1,可以判斷特征空間中的一組向量是否線性相關,如果相關,則根據某個準則選取該向量組的一個極大無關組,用這個無關組代替原向量組,從而可以減少鑒別方向W中涉及向量的個數.這樣,式(6)中的n將減小,測試時所需的計算代價變小,因此,能夠提高分類效率.理論上,一個向量組與它的極大無關組等價,也就是能夠相互線性表示,而且,一個向量組往往不止一個極大無關組.在實際應用中,極大無關組的形式越簡單往往被使用得越多,如單位向量組.在本文應用中,主要考慮方程組的求解誤差,也就是訓練模式向量對應的準則值.根據式(5),本文選取的準則為:J即給出快速算法過程:
1)計算每個訓練模式x1,x2,…,xn對應的準則值J.為了計算J,必須先計算每個xi(i=1,2,…,n)對應的矩陣K'為
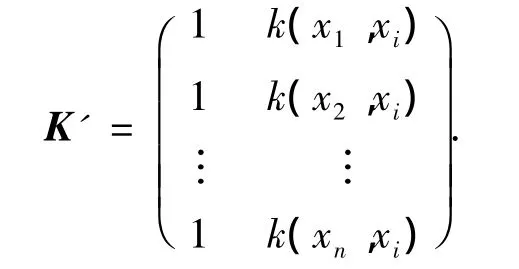
計算出K'后,把K'代入式(5)中求出A,最后把每個J計算出來,并且依J值的大小用快速排序法將xi(i=1,2,…,n)按升序排成一序列,記為R;令極大無關組B={}.
2)從R中選出第1個元素x1',計算它對應的D=|k(x1',x1')|,把x1'加入B,使其成為B的第1個元素:B={x1'},R=R-{x1'}.
3)B中其他元素的確定.correlate(B)表示與B中所有元素線性相關的樣本.設經過第i-1步選擇,B中有i-1個元素,B={x1',x2',…,xi'-1},與其對應的行列式為

取R中元素xi',令
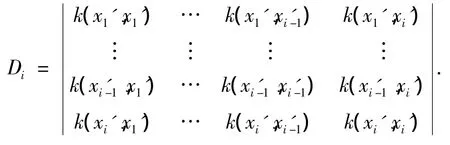
若Di=0,xi'∈correlate(B).則確定B中其他元素的過程的偽語言描述為:

最后獲得基樣本集B={x1',x2',…,xs'}.
4)用基樣本集B代替整個訓練樣本集,修改式(6),得:
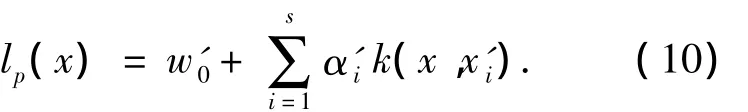
利用式(10),可以對一待測模式x進行分類.一般地,s?n,所以對待測樣本的分類速度將會大大提高.
3 實驗
本文實驗包括2個部分:實驗1和實驗2.它們都是在2.4 GHz CPU,256 M內存環境中使用Matlab7.0實現.
3.1 實驗1
在實驗1中,使用文獻[5,9]中提到的基準數據庫,在7個基準模式集上進行.每個模式集被隨機分成了100個部分,每個部分又包括4個子部分:訓練數據集、訓練標記集、測試數據集和測試標記集.實驗采用高斯型核函數為
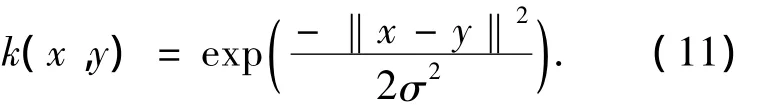
實驗時,先對每個數據集的第1個子集進行訓練,然后對100個測試集測試.按照這種方式,先在基準數據集上,根據式(5)實現了傳統的KMSE方法(TKMSE).一方面是為了與新提出的方法FKMSE在算法效果方面進行對比;另一方面,是為了確定核函數中的參數,實驗結果如表1所示.表1最后1列括號中的值為最優的核函數參數,式(5)中的正則項μ取1.0E-3.
表1給出了TKMSE、NKNM、FKNM、AB、SVM和FKMSE等6種方法的平均分類錯誤率及其標準差.其中:AB和SVM這2種方法的結果引自文獻[5];NKNM和FKNM這2種方法的結果引自文獻[9].表1中的分類效果由2項構成:第1項是100次測試所得的平均分類錯誤率;第2項是其標準差.對于每一數據集,表1中的括號項標出了使用5種方法NKNM、FKNM、AB、SVM和本文提出的FKMSE得到的最好分類效果.由表1看出,FKMSE與除TKMSE外的其他4種方法分類效果相當;對于數據集f.solar,FKMSE是5種非TKMSE方法中分類最好的.
表2給出了FKMSE和FKNM方法中的基樣本數及其與總訓練樣本數的比例,基樣本數后面的百分比是指一次訓練得到的基樣本個數與訓練樣本數之比.此比例普遍較低,7個數據集中最高的是15%,有的甚至低至約1%.這就是本文方法實現速度快的根本原因.同時,從分類效果來看,FKMSE與原方法TKMSE相差無幾,基本可以取代原訓練樣本進行分類.從表1和表2中可以看出,雖然FKMSE的分類效果比TKMSE稍微下降一點,總體分類正確率下降大約2%.但是,它的效率大大提高了.表3給出了FKMSE和TKMSE這2種方法的分類時間.這里的分類時間是指測試100次所需要的時間,表中括號中的數值是FKMSE與TKMSE分類時間的比例.從表3可以看出,文中提出的快速算法比傳統的方法測試速度要快一個數量級以上,極大地提高了分類效率.而且,根據表2和3,數據集的訓練樣本越多,本文方法的分類效率就越高.
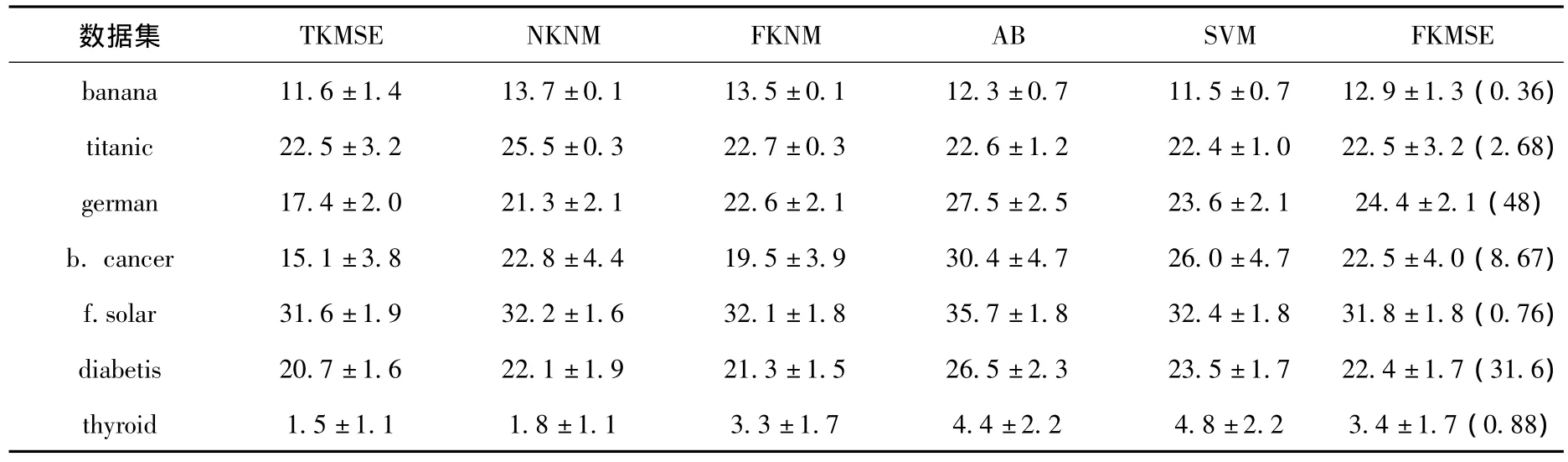
表1 分類錯誤率和標準差

表2 FKMSE和FKNM方法中的基樣本數及其與總訓練樣本數的比例

表3 FKMSE和TKMSE分類時間
3.2 實驗2
本文選用在入侵檢測領域中的經典測試數據集KDDCUP1999[12].該數據集主要由6個部分組成,實驗在其中的一個子集kddcup.data-10-percent.gz上進行.這個子集包含約49萬個樣本,每個樣本有41個特征.本文把數據集中的數據分成2類:1)正常數據,即類別表示為“normal”的數據; 2)異常數據,包含4類攻擊:DOS、PROBE、R21和U2R.本文實驗的訓練集選取2 000個樣本,由2類組成:1)“normal”;2)DOS攻擊類型之一的“smurf”類,每類1 000個樣本,都是隨機抽取.測試集在kddcup.data-10-percent.gz中按先后順序選取10 000個樣本,分為10個測試子集,每個1 000個樣本,樣本的類別與訓練集一致.
實驗中,通過預處理,去除了12個特征,采用29個特征進行計算.實驗也選用形如式(11)的高斯核函數,其參數選為訓練樣本方差的均值.其他參數同實驗1.
表4給出了2種方法KMSE和FKMSE的入侵檢測效果和時間.實驗中的檢測效果用平均檢測率表示,一次檢測率是指在一次測試中正確檢測出的攻擊次數與總的攻擊次數之比.平均檢測率則是對10個測試子集進行檢測所得到的檢測率均值.表中檢測時間是指對10個測試子集進行檢測所需的時間.從表4中可以看出,2種方法的檢測效果皆很理想,所以它們都是異常入侵檢測的有效方法.值得注意的是,本文提出的FKMSE方法在實驗中,不僅檢測效果很好,而且非常高效,其檢測時間只有KMSE方法的0.2%.因此,比KMSE方法更適合實時大規模異常入侵檢測.根據表4,在硬件條件不高的情況下,用FKMSE方法對10 000個樣本檢測,只需要2.9 s,就可以完全達到實時入侵檢測的要求.

表4 KMSE和FKMSE的檢測效果和時間
4 結論
1)原始輸入空間的樣本經非線性映射后變成特征空間的樣本,它們之間往往存在線性相關性.因此,如果通過訓練學習,剔除線性相關性,減少參與計算的樣本的個數,將會提高分類效率.
2)FKMSE適合實時大規模異常入侵檢測.
[1]TAYLOR S,CRISTIANINI N.Kernel methods for pattern analysis[M].London:Cambridge University Press,2004.
[2]ZHANG D,SONG F X,XU Y,et al.Advanced pattern recognition technologies with applications to biometrics[M].New York:IGI Global,2009.
[3]XU Y,LIN C,ZHAO W.Producing computationally efficient KPCA-based feature extraction for classification problems[J].Electronics Letters,2010,46(6):452-453.
[4]MIKA S,RATSCH G,WESTON J,et al.Fisher discriminant analysis with kernels[C]//Neural Networks for Signal Processing IX,1999.Proceedings of the 1999 IEEE Signal Proceesing Society Workshop.Madison,WI:IEEE Press,1999:41-48.
[5]LIU W F,PUSKAL P,JOSE P.The kernel least-meansquare algorithm[J].IEEE Transactions on Signal Processing,2008,56(2):543-554.
[6]XU Y.A new kernel MSE algorithm for constructing efficient classification procedure[J].International Journal of Innovative Computing,Information and Control,2009,5(8):2439-2447.
[7]CAWLEY G C,TALBOT C.Efficient leave-one-out cross-validation of kernel fisher discriminant classifiers[J].Pattern Recognition,2003,36(11):2585-2592.
[8]ZHENG W M,ZOU C R,ZHAO L.An improved algorithm for kernel principal component analysis[J].Neural Processing Letters,2005,22(1):49-56.
[9]XU Y,ZHANG D,JIN Z,et al.A fast kernel-based nonlinear discriminant analysis for multi-class problems[J].Pattern Recognition,2006,39(6):1026-1033.
[10]LEE D,JUNG K H,LEE J.Constructing sparse kernel machines using attractors[J].IEEE Trans on Neural Networks,2009,20(4):721-729.
[11]肖立中,邵志清,馬漢華,等.網絡入侵檢測中的自動決定聚類數算法[J].軟件學報,2008,19(8): 2140-2148.
[12]KDDCUP1999.http://archive.ics.uci.edu/ml/databases/kddcup99/kddcup99.html.
猜你喜歡
小獼猴智力畫刊(2022年9期)2022-11-04 02:31:42
數學小靈通(1-2年級)(2021年4期)2021-06-09 06:25:56
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
小哥白尼(趣味科學)(2019年6期)2019-10-10 01:01:50
當代陜西(2019年10期)2019-06-03 10:12:04
中學生數理化·七年級數學人教版(2019年4期)2019-05-20 10:06:32
中學生數理化·七年級數學人教版(2018年6期)2018-06-26 08:36:06
初中生世界·七年級(2017年9期)2017-10-13 22:27:46
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
發明與創新(2016年38期)2016-08-22 03:02:52
