基于YOLOv3與CRNN的自然場(chǎng)景文本識(shí)別
2022-08-16 03:27:16吳啟明宋雨桐
計(jì)算機(jī)工程與設(shè)計(jì) 2022年8期
吳啟明,宋雨桐
(1.河池學(xué)院 計(jì)算機(jī)與信息工程學(xué)院,廣西 宜州 546300; 2.華中科技大學(xué) 計(jì)算機(jī)科學(xué)與技術(shù)學(xué)院,湖北 武漢 430074)
0 引 言
自然場(chǎng)景中文本區(qū)域偏轉(zhuǎn)角度及文本區(qū)域邊緣復(fù)雜多樣,而且受限于采集圖像時(shí)光照環(huán)境和采集設(shè)備的性能,圖像中會(huì)包含一些噪聲數(shù)據(jù),影響了最終識(shí)別效果。因此,尋找一種在自然場(chǎng)景中的文本檢測(cè)與識(shí)別技術(shù)顯得尤為重要。
文本檢測(cè)與識(shí)別技術(shù)在國(guó)內(nèi)外已經(jīng)有相關(guān)團(tuán)隊(duì)和學(xué)者在研究[1-6],比如Jiri Matas團(tuán)隊(duì),視覺(jué)幾何團(tuán)隊(duì)(VGG)以及微軟亞洲研究院(MSRA)等,學(xué)者中有華南理工大學(xué)金連文教授、華中科技大學(xué)白翔教授、中國(guó)科學(xué)院大學(xué)葉齊祥教授等,他們?cè)谧匀粓?chǎng)景文本檢測(cè)研究中獲得了重大成果。
為了降低自然場(chǎng)景中圖像包含的噪聲以及文本區(qū)域偏轉(zhuǎn)角度對(duì)識(shí)別效率的影響,本文借鑒了已有成果后提出使用YOLOv3[7]與CRNN[8]模型解決在自然場(chǎng)景下中文和英文文本的檢測(cè)與識(shí)別問(wèn)題。降低文本區(qū)域偏轉(zhuǎn)角度對(duì)識(shí)別效率影響的具體實(shí)現(xiàn)為,在一系列固定寬度的文本框中使用文字朝向檢測(cè)算法,檢測(cè)出朝向?yàn)?、90、180、270度文本框,再使用小角度估算函數(shù)對(duì)其它角度的文本框進(jìn)行微調(diào)[9]。然后使用YOLOv3檢測(cè)單個(gè)固定寬度的小文本框,并采用文本框聚類(lèi)算法連接這些小文本框,以此獲得完整的文本檢測(cè)框。最后使用CRNN模型識(shí)別這些文本檢測(cè)框中的內(nèi)容,為了解決識(shí)別結(jié)果文本行中沒(méi)有空格的問(wèn)題,采用Viterbi算法[10]對(duì)英文文本進(jìn)行分詞,增強(qiáng)閱讀體驗(yàn)。為了提高實(shí)驗(yàn)的說(shuō)服力,本文在相同的實(shí)驗(yàn)場(chǎng)景中把CTPN[11]與DenseNet模型和YOLOv3與CRNN模型的檢測(cè)與識(shí)別結(jié)果進(jìn)行對(duì)比分析,進(jìn)一步驗(yàn)證YOLOv3與CRNN模型在自然場(chǎng)景文本檢測(cè)識(shí)別任務(wù)中的優(yōu)越性。為了展示檢測(cè)與識(shí)別結(jié)果,本文設(shè)計(jì)了文本檢測(cè)與識(shí)別系統(tǒng),方便給用戶呈現(xiàn)識(shí)別檢測(cè)結(jié)果。
1 算法實(shí)現(xiàn)
1.1 文字朝向檢測(cè)算法
先采用VGG16網(wǎng)絡(luò)模型進(jìn)行遷移訓(xùn)練檢測(cè)文字朝向。VGG16網(wǎng)絡(luò)模型見(jiàn)表1,共有5段卷積層,前2段(B1、B2)有2個(gè)卷積層,后3段(B3、B4、B5)有3個(gè)卷積層,每段結(jié)尾連接最大池化層(MP)來(lái)縮小圖片尺寸,最終由兩個(gè)全連接層(F1、F2)及softmax進(jìn)行四分類(lèi)角度(0°,90°,180°和270°)預(yù)測(cè)。
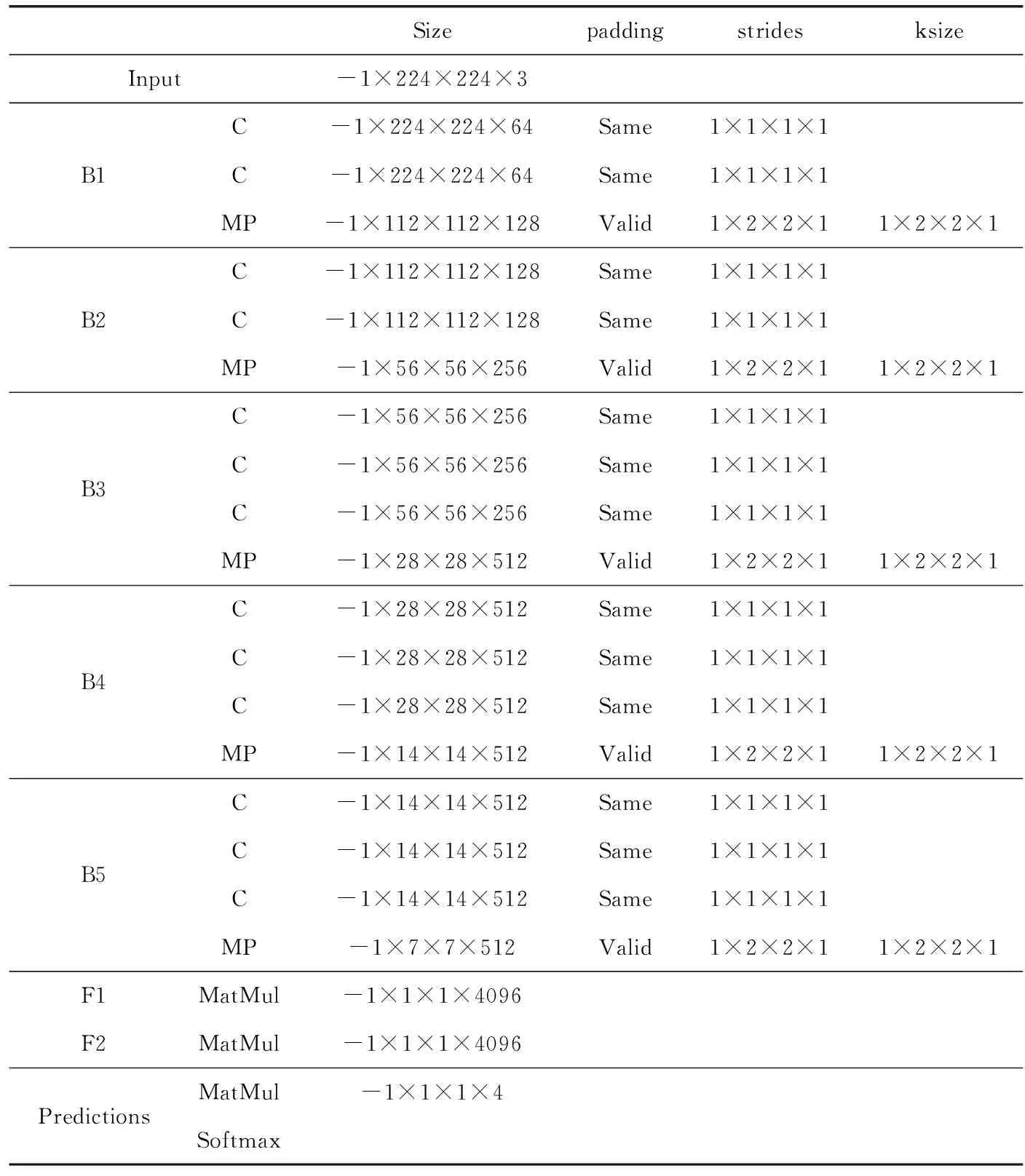
表1 VGG16網(wǎng)絡(luò)模型具體參數(shù)
首先要對(duì)圖像預(yù)處理,需要去除噪聲并剪切,最終輸出尺寸為(224,224,3)的圖像,接下來(lái)進(jìn)行零均值化處理,處理完的圖像加載到VGG16網(wǎng)絡(luò)輸入層(Input),用于預(yù)測(cè)文字朝向并旋轉(zhuǎn)調(diào)整。VGG16模型實(shí)現(xiàn)框架為keras,初始學(xué)習(xí)率為0.000 01,損失函數(shù)為交叉熵函數(shù),優(yōu)化方法為隨機(jī)梯度下降法,在此基礎(chǔ)上使用10萬(wàn)張圖片訓(xùn)練模型并進(jìn)行測(cè)試,實(shí)驗(yàn)準(zhǔn)確率為95.10%。
圖1為未加入文字朝向檢測(cè)算法與加入文字朝向檢測(cè)算法的結(jié)果對(duì)比。除四分類(lèi)角度(0°,90°,180°和270°)外其它角度,本文采用小角度估算函數(shù)預(yù)測(cè)并旋轉(zhuǎn)圖像,為了保證計(jì)算速度規(guī)定只能在(-15,15)度范圍內(nèi)調(diào)整。

圖1 文字朝向檢測(cè)算法使用結(jié)果對(duì)比
傾斜角度計(jì)算步驟為,首先將圖像灰度化,同時(shí)等比例縮放到(600-900)像素范圍內(nèi)。然后進(jìn)行歸一化處理。最后計(jì)算每行圖像的均值與方差向量,如果圖像中沒(méi)有文本傾斜情況,此時(shí)方差最大,對(duì)應(yīng)的角度就是傾斜角度。
1.2 YOLOv3文本區(qū)域檢測(cè)算法
1.2.1 YOLOv3模型文本檢測(cè)網(wǎng)絡(luò)框架
傳統(tǒng)YOLOv3目標(biāo)檢測(cè)算法更適用于一般物體的檢測(cè),將其用于自然場(chǎng)景文本文字檢測(cè)任務(wù)中并不能發(fā)揮其優(yōu)勢(shì)。相對(duì)于自然場(chǎng)景中的常規(guī)物體,自然場(chǎng)景中的文本行長(zhǎng)度、尺寸比例更加復(fù)雜多樣,為文本行定位增加了難度。為了解決上述問(wèn)題,先檢測(cè)單個(gè)固定寬度的小文本段,繼而再將這些小文本段聚類(lèi),得到一條文本行。
圖2為YOLOv3網(wǎng)絡(luò)結(jié)構(gòu),其中使用75個(gè)卷積層來(lái)分析文本特征。而且網(wǎng)絡(luò)結(jié)構(gòu)不包含全連接層,所以可以輸入任意大小的圖像。此外整個(gè)YOLOv3結(jié)構(gòu)中也沒(méi)有出現(xiàn)池化層,因此通過(guò)調(diào)整卷積核的步長(zhǎng)stride=(2,2) 來(lái)替代池化層實(shí)現(xiàn)下采樣的效果,并且往下一層傳遞時(shí)尺度不變。同時(shí)YOLOv3通過(guò)借鑒ResNet網(wǎng)絡(luò)對(duì)殘差信息的學(xué)習(xí)方式來(lái)優(yōu)化檢測(cè)速度。
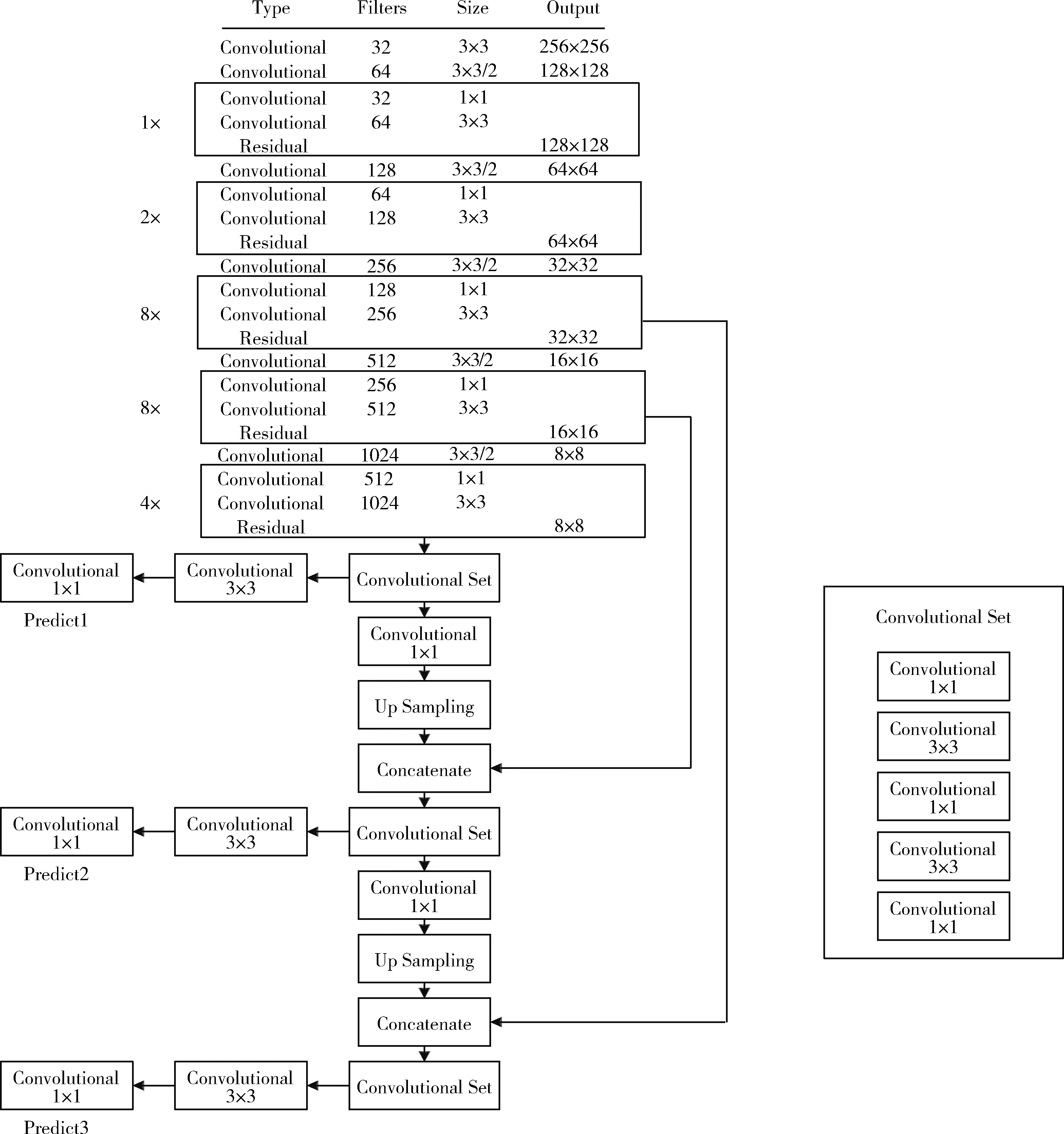
圖2 YOLOv3文本檢測(cè)網(wǎng)絡(luò)結(jié)構(gòu)
同時(shí)為了提高檢測(cè)精度,本文也借鑒了類(lèi)似FPN網(wǎng)絡(luò)的思路,首先將每種尺度預(yù)測(cè)3個(gè)邊界框,然后按照anchor設(shè)計(jì)方式得到9個(gè)聚類(lèi)中心,最后將這9個(gè)聚類(lèi)分給3個(gè)尺寸的邊界框。
1.2.2 YOLOv3模型訓(xùn)練
(1)環(huán)境配置
實(shí)驗(yàn)環(huán)境配置如下:
實(shí)驗(yàn)采用的硬件環(huán)境為12 G內(nèi)存,i7處理器windows 10 ×64;CUDA 8.0.61;CUDNN 5.1.10;開(kāi)發(fā)環(huán)境為python 3.6;編輯環(huán)境為Pytorch 1.0.1;調(diào)用的函數(shù)庫(kù)為opencv 3.4.2.16;開(kāi)發(fā)框架為keras 2.1.5。
(2)訓(xùn)練數(shù)據(jù)集


圖3 txt格式標(biāo)簽
由于YOLOv3模型限定輸入文件格式為xml,因此本論文使用python程序?qū)xt格式的標(biāo)簽文件轉(zhuǎn)換為xml格式標(biāo)簽文件,最終效果如圖4所示。可以看出xml格式標(biāo)簽文件中包含了文本的分類(lèi)標(biāo)簽、文本區(qū)域起始點(diǎn)的坐標(biāo)、文本圖像的大小、文本的內(nèi)容、文本區(qū)域偏離起始點(diǎn)的角度及文本區(qū)域長(zhǎng)寬。為解決在識(shí)別過(guò)程中出現(xiàn)的中文亂碼顯示問(wèn)題,首先將xml格式的文本采用HTML實(shí)體編碼,然后再解碼成漢字。

圖4 xml格式標(biāo)簽
(3)模型訓(xùn)練
基于keras和tensorflow加載YOLOv3模型實(shí)現(xiàn)遷移學(xué)習(xí)。cluster_number為9,最小分隔寬度值為8, scales[416,512,608,608,608,768,960,1024],遷移訓(xùn)練完成后再通過(guò)K-means進(jìn)行計(jì)算,得出anchors為 {8,11, 8,22, 8,34, 8,49, 8,70, 8,98, 8,142, 8,228, 8,522}。
使用GPU訓(xùn)練YOLOv3模型,設(shè)置輸入圖像尺寸為608×608,初始學(xué)習(xí)率為0.001,訓(xùn)練過(guò)程中按0.1倍進(jìn)行調(diào)整。epoch設(shè)定為100,batch_size設(shè)定為32。經(jīng)過(guò)實(shí)驗(yàn)得出YOLOv3的loss和confidence_loss值如圖5所示。

圖5 YOLOv3的loss值和confidence_loss值
由圖5可知,YOLOv3模型在訓(xùn)練過(guò)程中,loss由0.9056降至0.8313后波動(dòng)逐漸減小,confidence_loss由0.6857降至0.6443后波動(dòng)逐漸減小,說(shuō)明loss值隨著訓(xùn)練次數(shù)的增加有序下降,最終趨于收斂。相對(duì)而言驗(yàn)證集的損失值曲線val_loss波動(dòng)幅度較大,但隨著迭代次數(shù)的增加最終趨于收斂,表明YOLOv3模型在ICDAR2017數(shù)據(jù)集中的檢測(cè)效果趨于穩(wěn)定。最終將訓(xùn)練好的YOLOv3模型用于檢測(cè),結(jié)果如圖6所示。

圖6 YOLOv3模型檢測(cè)出的text_proposal
1.3 文本框聚類(lèi)算法
YOLOv3模型輸出一系列固定寬度的文本框,然后將這些固定寬度的文本框采用文本線構(gòu)造算法連接起來(lái)。
假設(shè)某圖有圖7所示的A文本框和B文本框,采用如下算法構(gòu)造文本行:
(1)按x坐標(biāo)對(duì)文本框index依次排序;
(2)計(jì)算每個(gè)固定寬度的文本框boxi的pair(boxi), 組成pair(boxi,boxj);
(3)通過(guò)pair(boxi,boxj) 建立連接圖,最終得到一個(gè)文本檢測(cè)框。
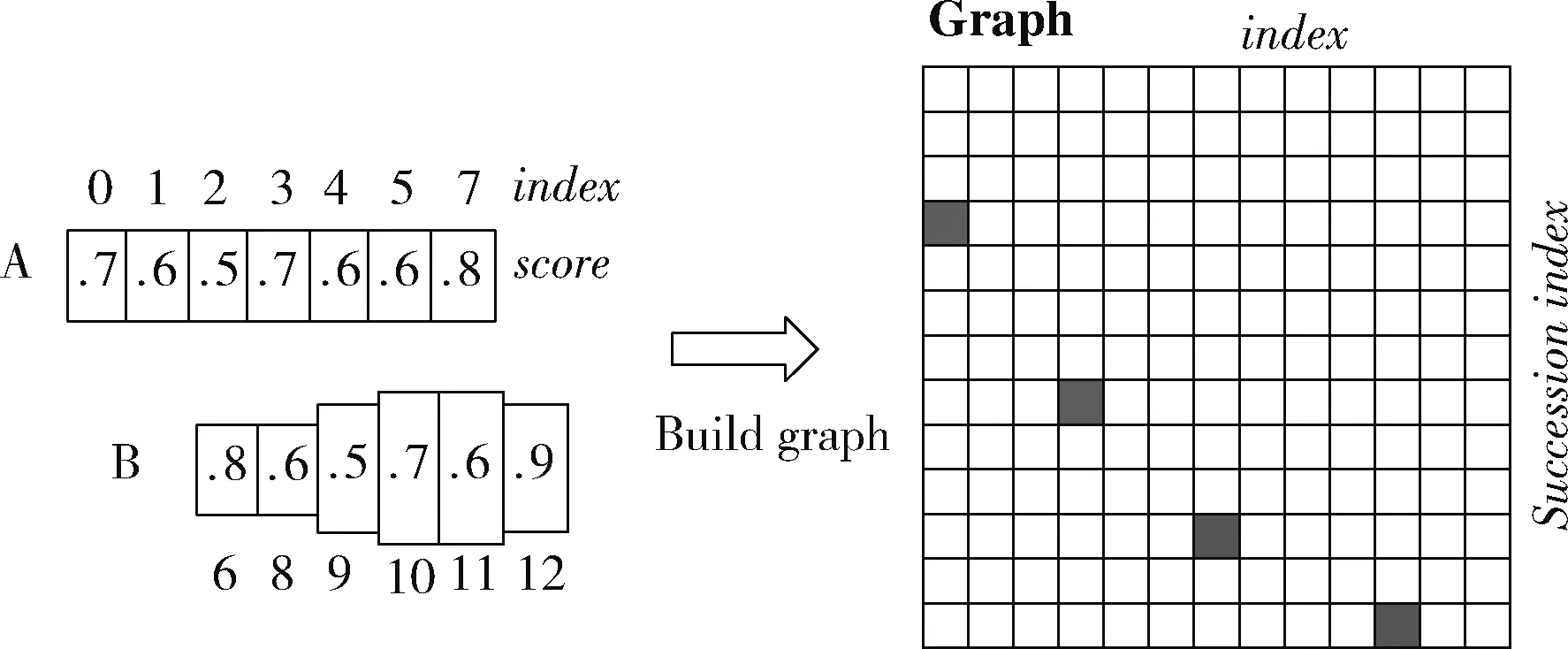
圖7 文本框聚類(lèi)算法構(gòu)造文本行
文本框聚類(lèi)算法建立文本框boxi的pair(boxi,boxj) 步驟為:
(1)正向?qū)ふ?/p>
1)尋找在水平正方向上與文本框boxi距離小于50的文本框?yàn)楹蜻x文本框集合;
2)從步驟1)的候選文本框中挑出滿足boxi水平方向overlapv>0.7的文本框;
3)從步驟2)的文本框中挑出滿足softmax score最大的boxj。
(2)反向?qū)ふ?/p>
1)尋找在水平正負(fù)方向上與文本框boxi距離小于50的文本框?yàn)楹蜻x文本框集合;
2)從上述步驟1)的候選文本框中挑出滿足boxi水平方向overlapv>0.7的文本框;
3)從上述步驟2)的文本框中挑出滿足softmax score最大的boxk。
(3)對(duì)比scorei和scorek
判斷scorei≥scorek是否為最長(zhǎng)連接,如果是最長(zhǎng)連接,設(shè)置Graph(i,j)=True; 否則將繼續(xù)尋找該連接所在的最長(zhǎng)連接。
在進(jìn)行文本區(qū)域檢測(cè)時(shí),借鑒“微分”思想將待檢測(cè)文本分割成一系列等寬的文本框,然后再由文本線構(gòu)造算法合并成一個(gè)圖8所示的完整文本檢測(cè)框。

圖8 檢測(cè)的文本框聚類(lèi)結(jié)果
1.4 CRNN文本識(shí)別算法
主要研究基于CRNN的自然場(chǎng)景文本識(shí)別,CRNN可在不依賴詞典的情況下實(shí)現(xiàn)識(shí)別不定長(zhǎng)文本序列。研究發(fā)現(xiàn)基于CRNN的自然場(chǎng)景文本識(shí)別任務(wù)準(zhǔn)確率較高。
1.4.1 CRNN文本識(shí)別算法原理
CRNN文本識(shí)別算法在自然場(chǎng)景的文本識(shí)別中集成了特征提取、序列建模和轉(zhuǎn)錄功能。
如圖9所示在自然場(chǎng)景文本識(shí)別中CRNN包括了卷積層(Conv)、循環(huán)層(ReCurrent Layers)和轉(zhuǎn)錄層(Transcription Layers),主要用于特征提取、序列建模和轉(zhuǎn)錄功能。
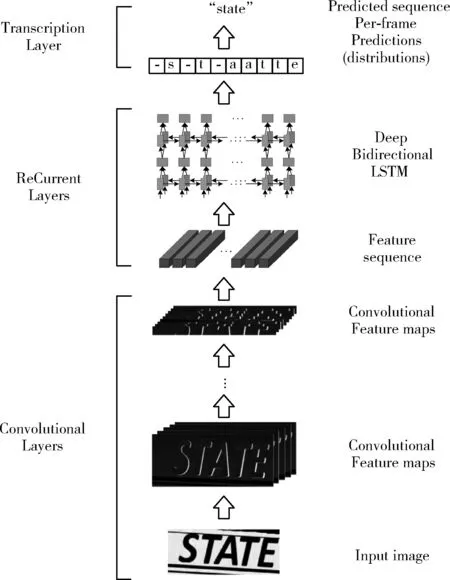
圖9 CRNN識(shí)別原理
首先在卷積層中獲得輸入圖像的特征序列,然后在循環(huán)層中對(duì)這些特征序列進(jìn)行每幀預(yù)測(cè),最后在轉(zhuǎn)錄層將其轉(zhuǎn)換成標(biāo)簽。
圖9的卷積層(Conv)中包含Conv和MaxPool,用于將輸入圖像(32,100,3)變成一組卷積特征矩陣(1,25,512),然后用BN網(wǎng)絡(luò)對(duì)這些卷積特征矩陣進(jìn)行歸一化。圖10所示歸一化后的特征向量與特征圖之間一一對(duì)應(yīng)且從左向右依次排列。
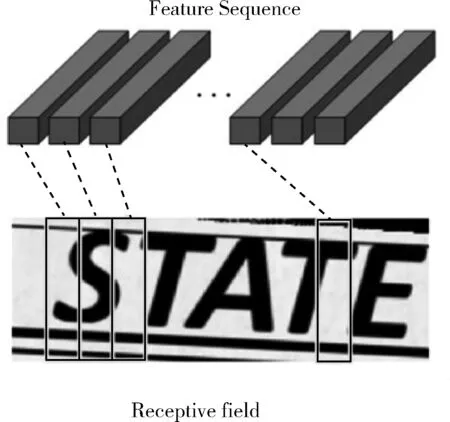
圖10 特征序列
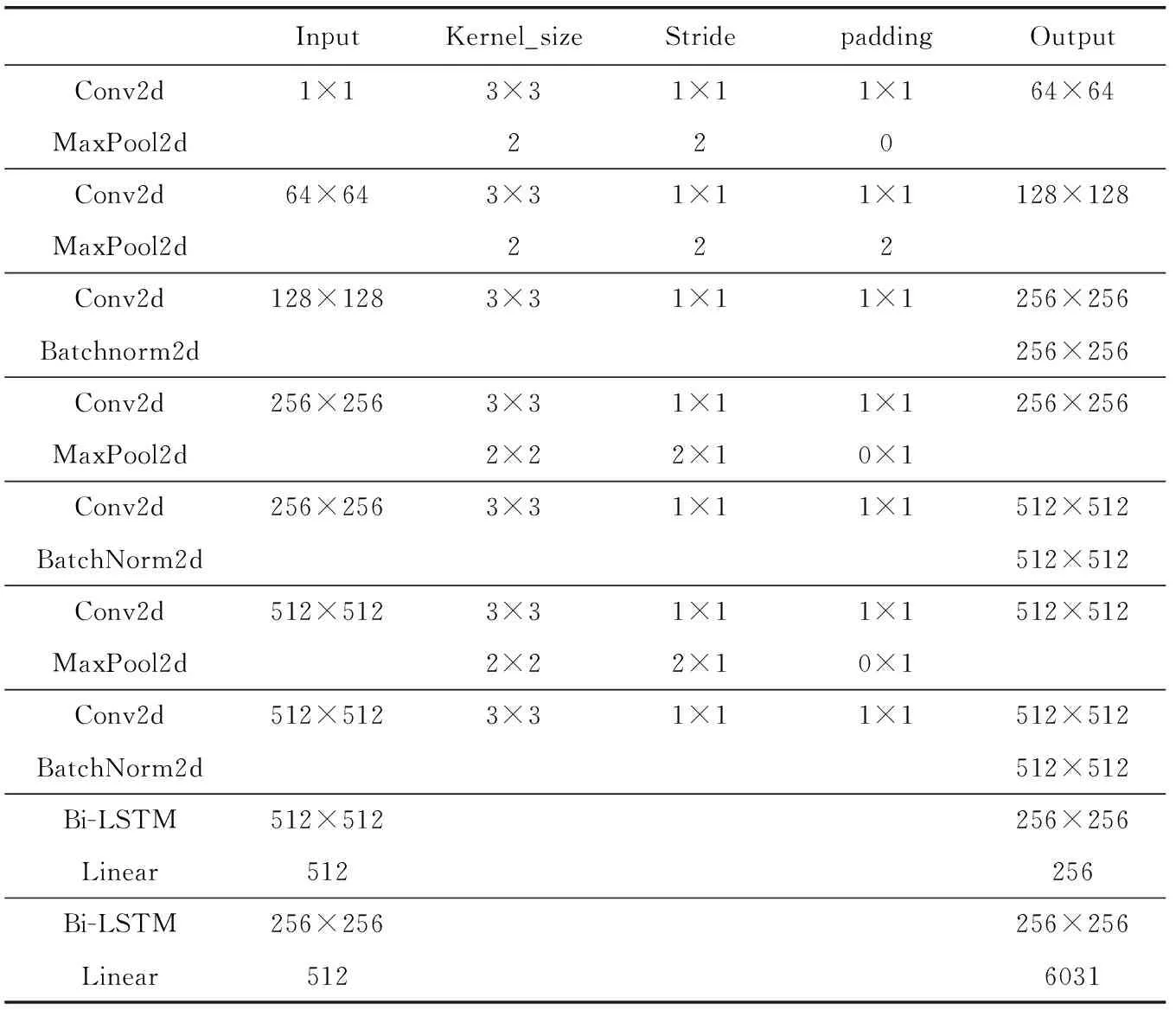
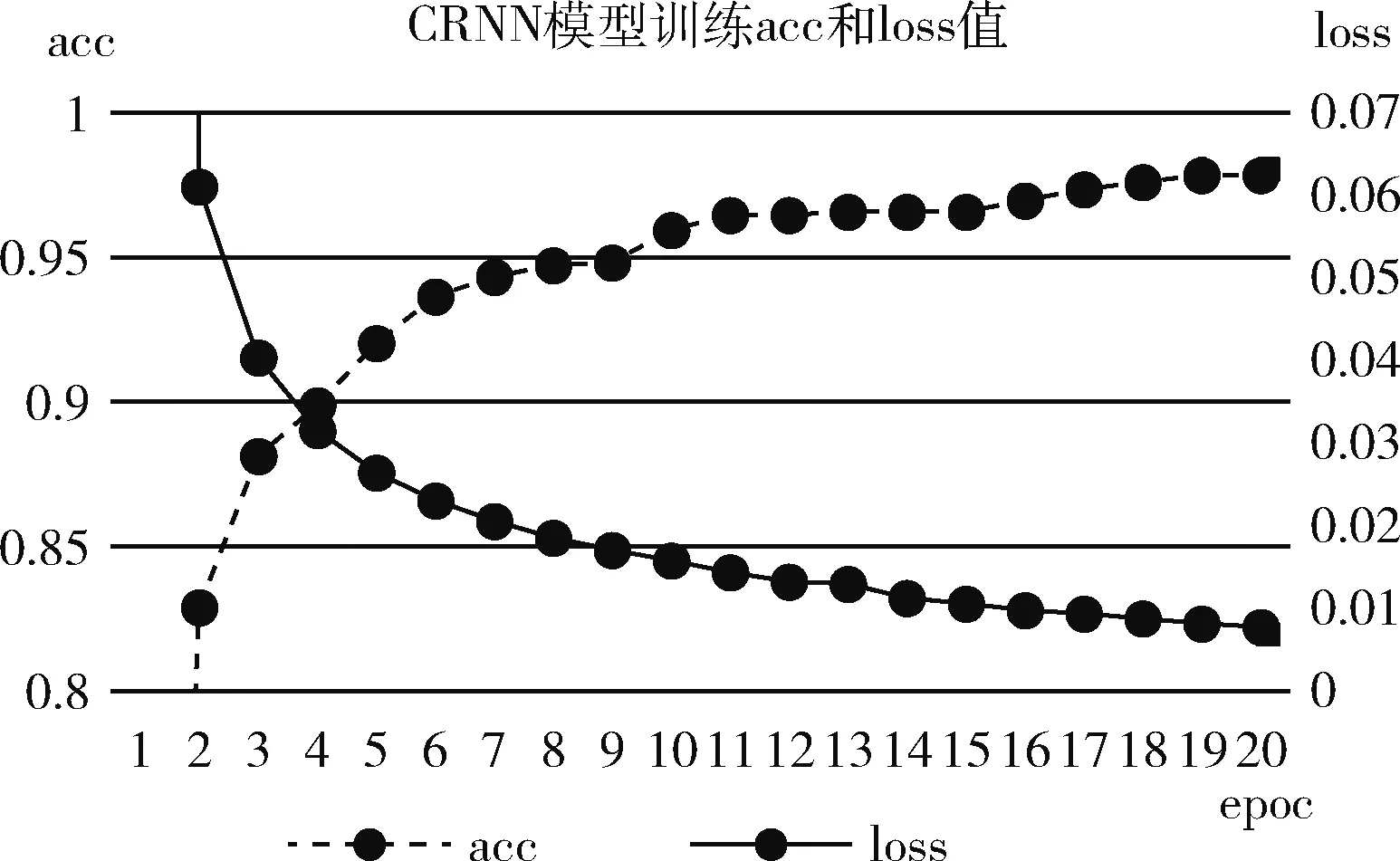
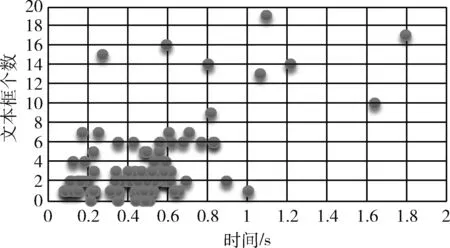
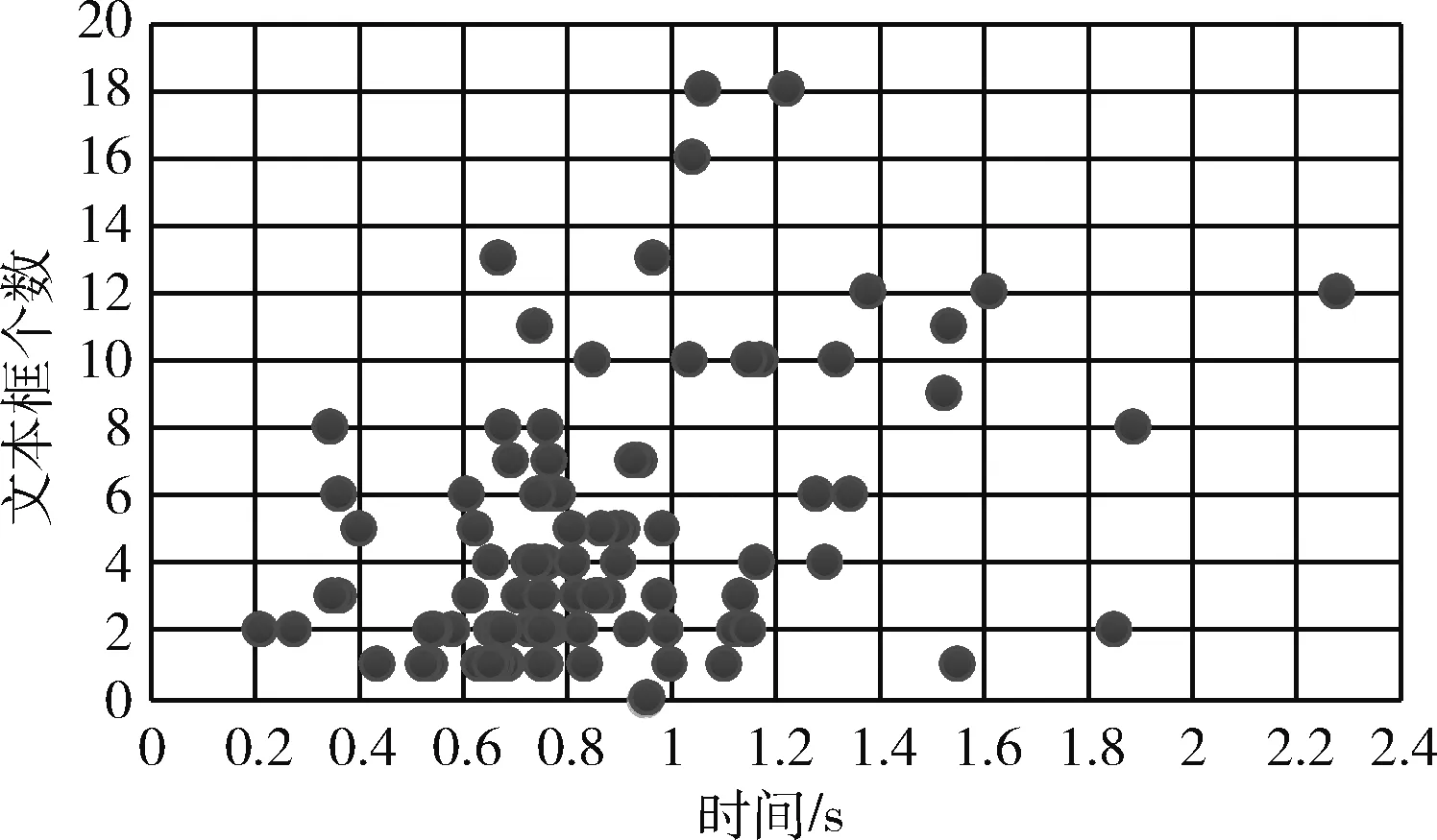
圖11所示,在循環(huán)層中通過(guò)深度雙向LSTM結(jié)構(gòu),對(duì)每幀xt預(yù)測(cè)其特征序列X=x1,…,xt的標(biāo)簽yt。 深度雙向LSTM網(wǎng)絡(luò)可以記憶長(zhǎng)段序列輸入,本文設(shè)置最大時(shí)間序列長(zhǎng)度T為25,設(shè)置xt(1 圖11 深度雙向LSTM結(jié)構(gòu) 循環(huán)層的預(yù)測(cè)結(jié)果標(biāo)簽yt, 通過(guò)CRNN頂部的轉(zhuǎn)錄層轉(zhuǎn)換為標(biāo)簽序列。CRNN頂部的轉(zhuǎn)錄層使用CTC算法計(jì)算損失函數(shù),理論上可以簡(jiǎn)化訓(xùn)練過(guò)程從而加快收斂。 CRNN頂部的轉(zhuǎn)錄層分為有詞典轉(zhuǎn)錄和無(wú)詞典轉(zhuǎn)錄;無(wú)詞典轉(zhuǎn)錄模式下,主要通過(guò)預(yù)測(cè)結(jié)果標(biāo)簽中概率最大的標(biāo)簽來(lái)確定該目標(biāo)文本的標(biāo)簽;有詞典轉(zhuǎn)錄模式下,首先定位目標(biāo)文本,然后通過(guò)模糊匹配確定該目標(biāo)文本的標(biāo)簽。 轉(zhuǎn)錄層通過(guò)每幀預(yù)測(cè)結(jié)果標(biāo)簽yt來(lái)表明標(biāo)簽序列y=y1,…,yt。 并且y=y1,…,yt中的任意結(jié)果標(biāo)簽yt∈R|L′|都是集合L′=L∪{blank} 的一個(gè)概率分布。首先在序列π∈L′T上定義映射函數(shù)B用于去除空標(biāo)簽和重復(fù)標(biāo)簽,然后將去除空標(biāo)簽和重復(fù)標(biāo)簽的序列π∈L′T寫(xiě)入序列1,就比如序列“--hh-e-l-ll-oo--”經(jīng)過(guò)映射函數(shù)B移除空標(biāo)簽和重復(fù)標(biāo)簽后變成“hello”。條件概率為將所有序列π∈L′T通過(guò)映射函數(shù)B映射到序列l(wèi)的概率之和 (1) 相比于先前的專家學(xué)者在自然場(chǎng)景文本識(shí)別領(lǐng)域的研究,CRNN文本識(shí)別算法具有4種獨(dú)特的屬性: (1)CRNN模型可實(shí)現(xiàn)端到端訓(xùn)練。 (2)CRNN模型不需要字符分割,可以自動(dòng)識(shí)別任意長(zhǎng)度的文本序列。 (3)CRNN模型在有詞典狀態(tài)和無(wú)詞典狀態(tài)均有良好的魯棒性和準(zhǔn)確性。 (4)CRNN模型更適用于自然場(chǎng)景問(wèn)題中。在IIIT-5K、街景文本和ICDAR數(shù)據(jù)集中驗(yàn)證了其優(yōu)越的性能。 1.4.2 CRNN模型文本識(shí)別網(wǎng)絡(luò)框架 CRNN網(wǎng)絡(luò)詳細(xì)參數(shù)見(jiàn)表2。為了在中文訓(xùn)練和英文訓(xùn)練中更好兼容,調(diào)整CRNN模型中后兩個(gè)MaxPool2d層的stride為2×1,進(jìn)而增加了特征序列的長(zhǎng)度,提高了不同寬度下的字符識(shí)別效果。同時(shí)為了使網(wǎng)絡(luò)收斂速度加快,本文在模型第3個(gè)卷積層之后加入Batchnorm2d層。 表2 CRNN模型文本識(shí)別網(wǎng)絡(luò) 1.4.3 CRNN模型訓(xùn)練 (1)訓(xùn)練數(shù)據(jù)集 采用的圖像數(shù)據(jù)集中包含字符6031個(gè),針對(duì)包含字符的單張圖像,依次進(jìn)行預(yù)處理、模糊處理、灰度處理、部分遮擋處理、背景處理。然后再針對(duì)圖像中字符本身的特點(diǎn)選擇對(duì)圖像進(jìn)行拉伸或變換處理。最終生成360萬(wàn)張大小280×32的文本圖片,其中每張圖片包含10個(gè)字符。 (2)模型訓(xùn)練 圖12 CRNN模型訓(xùn)練所得驗(yàn)證集精確度和loss值 分析上圖可知,隨著訓(xùn)練次數(shù)的增加模型的準(zhǔn)確率逐漸提高,loss值逐漸下降,并呈收斂趨勢(shì),表明訓(xùn)練逐漸趨于穩(wěn)定。 最終利用訓(xùn)練好的CRNN模型進(jìn)行識(shí)別,結(jié)果如圖13所示。 圖13 CRNN模型識(shí)別結(jié)果 如圖14(a)為輸入數(shù)據(jù),圖14(b)為CRNN網(wǎng)絡(luò)返回的無(wú)空格數(shù)據(jù),此類(lèi)數(shù)據(jù)無(wú)法正確分割英文單詞,因此本文采用動(dòng)態(tài)規(guī)化算法(Viterbi)[9]分隔英文單詞。 通過(guò)Viterbi找到隱含狀態(tài)序列,即位于馬爾可夫信息源上下文和隱馬爾可夫模型(HMM)中生成概率最高的序列維特比路徑。 假設(shè)HMM中的整個(gè)狀態(tài)空間表示為S(i∈S), 其中狀態(tài)i初始概率為πi, 從狀態(tài)i到j(luò)的概率表示為ai,j。 觀察到的值為y1,y2,…,yt。 通過(guò)下面的迭代關(guān)系給出產(chǎn)生觀察值的最可能狀態(tài)序列x1,x2,…,xt P1,k=πk-P(y1|k) (2) 式(2)中的P(y1|k) 表示處于隱狀態(tài)k所對(duì)應(yīng)值y1的產(chǎn)生概率,πk表示k的初始概率 (3) 式(3)中的Pt,k表示在0~t中的最大序列概率值,此時(shí)的k為最終狀態(tài);然后用參數(shù)x的反向指針獲得維特比路徑。 式(3)所示,Viterbi對(duì)于當(dāng)前狀態(tài)最佳值的計(jì)算依賴于當(dāng)前狀態(tài)的 |S| 個(gè)值和前一狀態(tài)的 |S| 個(gè)值,總共有T個(gè)狀態(tài),每個(gè)狀態(tài)需要計(jì)算O(|S|2) 次,因此總時(shí)間復(fù)雜度為O(T×|S|2)。 通過(guò)對(duì)比圖14(a)的輸入圖片和圖14(b)的識(shí)別結(jié)果,發(fā)現(xiàn)識(shí)別結(jié)果中的英文字符串沒(méi)有空格,導(dǎo)致難以分割單詞從而降低可讀性。圖14(c)使用Viterbi算法,結(jié)果顯示英文字符串被分詞,由此可證Viterbi算法可以解決英文字符串的分詞問(wèn)題。 圖15為文本檢測(cè)識(shí)別系統(tǒng)架構(gòu),其中YOLOv3網(wǎng)絡(luò)負(fù)責(zé)文字檢測(cè)模塊,CRNN網(wǎng)絡(luò)負(fù)責(zé)文字識(shí)別模塊。 圖15 系統(tǒng)架構(gòu) 文字檢測(cè)與識(shí)別系統(tǒng)為B/S架構(gòu),圖16所示從Web頁(yè)面上傳圖片后先存儲(chǔ)到數(shù)據(jù)庫(kù),然后從數(shù)據(jù)庫(kù)批量讀取待識(shí)別圖片,并使用文字朝向算法預(yù)測(cè)角度并旋轉(zhuǎn),再通過(guò)YOLOv3模型將圖片中的文字輸出為定長(zhǎng)的文本框,將這些文本框使用聚類(lèi)算法連接成一個(gè)文本行,之后將文本行送入CRNN模型識(shí)別,識(shí)別出的結(jié)果使用Viterbi分詞算法進(jìn)行分詞處理,最后在前端頁(yè)面展示分詞處理結(jié)果。 圖16 系統(tǒng)前端頁(yè)面 YOLOv3與CRNN模型在不同的自然場(chǎng)景文本圖像識(shí)別中均有良好的效果,并且識(shí)別速度快,能夠滿足實(shí)際的識(shí)別需求。圖17為選取100幅場(chǎng)景文本圖像在YOLOv3與CRNN模型中進(jìn)行測(cè)試,得到檢測(cè)時(shí)間與文本框個(gè)數(shù)間的關(guān)系。 圖17 YOLOv3與CRNN模型文本框檢測(cè)個(gè)數(shù)和 檢測(cè)與識(shí)別的時(shí)間關(guān)系 分析上圖得出,在自然場(chǎng)景文本圖像檢測(cè)與識(shí)別中,模型在0.7 s內(nèi)就能檢測(cè)出大部分文本框,多次實(shí)驗(yàn)發(fā)現(xiàn)平均在1 s以內(nèi)就能檢測(cè)出大部分文本框,因此設(shè)定閾值0為1 s,以閾值為標(biāo)準(zhǔn)剔除超過(guò)閾值的數(shù)據(jù),最終求得平均檢測(cè)時(shí)間為0.4258 s。 基于DenseNet,使用keras框架搭建模型并訓(xùn)練。在GPU環(huán)境中運(yùn)行5個(gè)epoch,batch_size取128,實(shí)驗(yàn)識(shí)別率為97.3%。 經(jīng)過(guò)實(shí)驗(yàn)得出DenseNet模型與CTPN檢測(cè)用時(shí)7.934 s,檢測(cè)與識(shí)別共用時(shí)12.994 s。DenseNet在訓(xùn)練集中準(zhǔn)確率較高,但加入Viterbi分詞算法后英文文本的識(shí)別準(zhǔn)確率會(huì)降低,由此可證在DenseNet模型中加入Viterbi算法后會(huì)降低其識(shí)別準(zhǔn)確率。 這里存在一個(gè)問(wèn)題,由于DenseNet模型是用于識(shí)別低像素圖片,因此采用DenseNet模型,需要首先壓縮圖片像素,然后再檢測(cè)識(shí)別,這樣降低像素的方式如果出現(xiàn)圖片中字符較多的情況會(huì)導(dǎo)致檢測(cè)性能下降,從而影響后續(xù)的識(shí)別效果。 為了進(jìn)一步分析CTPN與DenseNet模型識(shí)別結(jié)果,采用與YOLOv3與CRNN模型實(shí)驗(yàn)中相同的100幅場(chǎng)景文本圖像進(jìn)行測(cè)試,得到CTPN與DenseNet模型文本框個(gè)數(shù)與識(shí)別時(shí)間的關(guān)系。 圖18所示,在自然場(chǎng)景文本圖片識(shí)別任務(wù)中DenseNet與CTPN模型在2 s內(nèi)可識(shí)別出大多數(shù)文本框個(gè)數(shù),在0.2 s~1.4 s之間識(shí)別出的文本框數(shù)最多。在1.6 s內(nèi)基本上能夠完成文本框識(shí)別,由此給定閾值為1.6 s,以閾值為標(biāo)準(zhǔn),刪除大于閾值的數(shù)據(jù),最終求得平均檢測(cè)識(shí)別時(shí)間為0.8250 s。 圖18 DenseNet與CTPN與文本框檢測(cè)個(gè)數(shù) 及檢測(cè)與識(shí)別的時(shí)間關(guān)系 提出兩種檢測(cè)與識(shí)別模型,并設(shè)計(jì)相關(guān)實(shí)驗(yàn),最終得出CRNN與YOLOv3模型的以下特點(diǎn): (1)檢測(cè)方面,CTPN模型的檢測(cè)精度比YOLOv3模型低。具體表現(xiàn)在CTPN模型在大間距字符文本行中檢測(cè)精度低,而且會(huì)出現(xiàn)邊緣檢測(cè)不準(zhǔn)確的情況。同時(shí)CTPN模型在檢測(cè)方向上也有限制,只能檢測(cè)水平方向的文本,而YOLOv3模型在多文字朝向檢測(cè)場(chǎng)景中仍然保持很好的檢測(cè)效果。 (2)識(shí)別方面,CRNN模型在中英文混合的自然場(chǎng)景中識(shí)別準(zhǔn)確率比DenseNet模型高,說(shuō)明CRNN模型有較強(qiáng)的魯棒性;而且DenseNet模型只能讀取低分辨率圖片,一旦圖片中字符數(shù)量增多時(shí)識(shí)別準(zhǔn)確率就會(huì)降低,這就導(dǎo)致最終識(shí)別準(zhǔn)確率降低。 (3)檢測(cè)與識(shí)別速度方面,通過(guò)在相同數(shù)據(jù)集上測(cè)試。表3為相同的實(shí)驗(yàn)環(huán)境和場(chǎng)景文本數(shù)據(jù)集中,CTPN與DenseNet模型和YOLOv3與CRNN模型檢測(cè)與識(shí)別時(shí)間對(duì)比,實(shí)驗(yàn)結(jié)果表明CRNN模型與YOLOv3的檢測(cè)與識(shí)別速度明顯優(yōu)于CTPN與DenseNet模型。 表3 CTPN與DenseNet模型和YOLOv3與 CRNN模型檢測(cè)與識(shí)別時(shí)間對(duì)比/s 綜上所述,通過(guò)對(duì)比兩種模型的識(shí)別結(jié)果得出,在自然場(chǎng)景中的中英文文本圖像檢測(cè)與識(shí)別任務(wù)中,YOLOv3與CRNN模型不論是檢測(cè)與識(shí)別準(zhǔn)確率和檢測(cè)與識(shí)別速度方面都具有顯著的優(yōu)勢(shì)。 為了提升現(xiàn)有的自然場(chǎng)景圖片文本檢測(cè)與識(shí)別技術(shù),本文提出使用CRNN與YOLOv3模型進(jìn)行自然場(chǎng)景下的文本檢測(cè)識(shí)別,實(shí)驗(yàn)采用文字朝向檢測(cè)算法和小角度估算函數(shù)提升了文字朝向檢測(cè)算法的準(zhǔn)確率,并使用YOLOv3和文本框聚類(lèi)算法確定待識(shí)別文本行,最終使用CRNN識(shí)別文本。相比較傳統(tǒng)的DenseNet與CTPN模型,CRNN與YOLOv3模型的識(shí)別準(zhǔn)確率和識(shí)別效率都最優(yōu)。 雖提升了自然場(chǎng)景文本的識(shí)別準(zhǔn)確率和識(shí)別效率,但仍有不足之處需要更深入探究,具體如下: (1)由于中文數(shù)據(jù)集中缺少繁體字,手寫(xiě)體及彎曲文本,導(dǎo)致CRNN模型對(duì)這類(lèi)中文字體識(shí)別準(zhǔn)確率低,從而降低了整體識(shí)別準(zhǔn)確率,接下來(lái)將在數(shù)據(jù)集中補(bǔ)充這類(lèi)中文字體。 (2)在模糊圖像中的識(shí)別準(zhǔn)確率較低,可以嘗試對(duì)模糊圖像進(jìn)行增強(qiáng)處理,或許可以提高識(shí)別準(zhǔn)確率。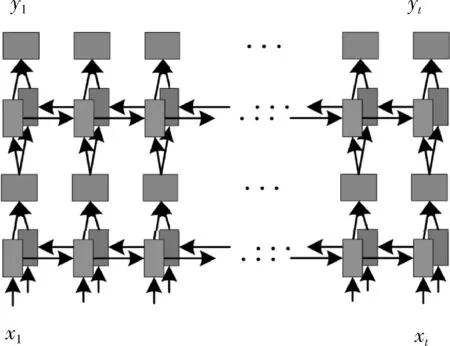
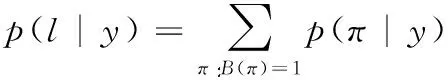
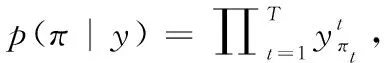

1.5 Viterbi分詞算法
2 檢測(cè)與識(shí)別系統(tǒng)框架

3 識(shí)別結(jié)果對(duì)比分析
3.1 YOLOv3與CRNN模型識(shí)別結(jié)果
3.2 CTPN與DenseNet模型識(shí)別結(jié)果
3.3 兩種模型識(shí)別結(jié)果對(duì)比分析

4 結(jié)束語(yǔ)
猜你喜歡
童話王國(guó)·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
中學(xué)生數(shù)理化·七年級(jí)數(shù)學(xué)人教版(2021年6期)2021-11-22 07:50:58
中學(xué)生數(shù)理化·七年級(jí)數(shù)學(xué)人教版(2021年6期)2021-11-22 07:50:58
中學(xué)生數(shù)理化·七年級(jí)數(shù)學(xué)人教版(2021年6期)2021-11-22 07:50:58
中學(xué)生數(shù)理化·七年級(jí)數(shù)學(xué)人教版(2020年10期)2020-11-26 08:24:50
數(shù)學(xué)物理學(xué)報(bào)(2020年2期)2020-06-02 11:29:24
制造技術(shù)與機(jī)床(2019年10期)2019-10-26 02:48:08
電子制作(2018年18期)2018-11-14 01:48:06
光學(xué)精密工程(2016年6期)2016-11-07 09:07:19
海峽科技與產(chǎn)業(yè)(2016年3期)2016-05-17 04:32:12
