一種改進的K均值聚類算法
2011-01-12 06:41:04孟佳娜鄧俐伶于玉海唐品忠
大連民族大學學報 2011年3期
關鍵詞:方法
孟佳娜,鄧俐伶,于玉海,唐品忠
(大連民族學院理學院,遼寧大連 116605)
一種改進的K均值聚類算法
孟佳娜,鄧俐伶,于玉海,唐品忠
(大連民族學院理學院,遼寧大連 116605)
針對傳統K均值算法中采取的歐氏距離計算相似性的不足,提出一種新的相似性計算方法,并將這種方法與歐氏距離的度量方法進行了比較。在UCI基準數據集上的實驗表明,該方法有更穩定的聚類結果,是一種比較有效的聚類度量方法。
聚類分析;K均值算法;相似性
聚類分析廣泛應用于模式識別、圖像處理、文本挖掘等領域,是非常重要的數據分析方法之一。目前已提出的聚類算法有很多,這些算法可以被分為基于劃分的方法、基于層次的方法、基于密度的方法、基于網格的方法和基于模型的方法[1]。在聚類方法中,K均值算法是最著名和最常用的劃分方法之一。K均值算法由于實現簡單、收斂速度快,自出現以來,已經提出了許多改進的算法。文獻[2]提出了一種關于K均值的局部搜索近似算法;文獻[3]針對初始中心敏感提出了一種選取初始聚類中心的算法。本文針對傳統K均值算法中計算相似性和選取初始中心點的不足,提出一種改進的算法。
1 傳統的K均值聚類算法
K均值法具有經典的聚類思想,邏輯簡明清晰。它的主要步驟如下:
步驟1對給定的m×n矩陣X,給出k個n維向量作為初始中心點。
步驟2比較數據集當中樣本點與各中心點間的距離,將各點劃分到與其距離最近的類中,形成初始分類。
步驟3計算步驟2所形成的類的中心,使每類中心點得以更新。
步驟4重復步驟2和3,直到中心點不再移動,各類所包含的樣本點也不再改變為止。
2 基于新的相似性度量方法的K均值聚類算法
聚類分析中數據結構可分為原始數據矩陣和距離矩陣。本文所討論的方法采用原始數據矩陣。原始數據矩陣X為
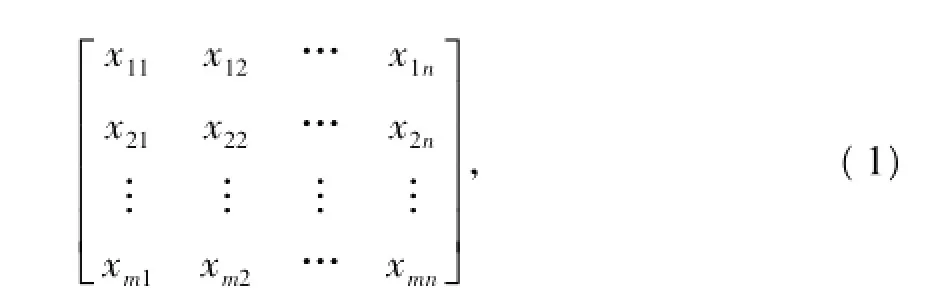
式中,xij(i=1,…,m;j=1,…,n)為第i個樣本的第j個屬性的觀測數據,第i個樣本為矩陣X的第i行所描述。在進行聚類分析時,通過對原始數據矩陣進行相應操作來刻畫樣本之間的相似性。
本文所提出的K均值算法的改進主要體現在初始中心點的選取和相似性度量兩個方面,下面介紹具體的改進方法。
2.1 初始中心點的選取
初始中心點的選擇在K均值算法中非常重要,為了使各類具有一定的區分度,通常尋找散布較大的點作為初始中心點。在傳統的算法中主要是隨機選取初始中心點或是以前K個樣本作為初始中心點,在本文的研究中,將按照如下方法來選取中心點:
(1)輸入原始數據矩陣。
(2)計算原始數據各維的最大值與最小值,保存為maxj與minj,表示第j維上數值的最大值與最小值。
(3)利用公式

計算得到第l類的中心點在第j維上的值,該值始終在開區間(minj,maxj)內,且各中心點之間比較分散。
2.2 數據對象之間的相似性度量
對于聚類問題,一個算法產生的簇集可能有許多性質,所以說一個聚類問題中相似性度量[4]的選擇是非常重要的。在傳統的K均值算法中,將每個樣本看成是高維空間中的一個點,進而定義點與點之間的距離,距離越大說明樣本之間的相似性越小,距離越小說明樣本間的相似性越大,這樣得到的聚類結果是一些體積相近的球體。本文在傳統的分組規則上進行改進,用曼哈頓距離來定義樣本的屬性之間的相似性,再將樣本與樣本之間的相似性用各個屬性的曼哈頓距離來刻畫。兩個樣本xa,xb之間的相似性可定義為

兩個樣本間的相似系數等于n個屬性間相似系數之和,每對屬性間的相似系數等于每對屬性曼哈頓距離加1的倒數。式(2)把兩個對象間每個屬性的相似系數都映射到(0,1]區間,在每個屬性的貢獻相同的假設下,有更好的可解釋性,而對于歐氏距離的度量方法,則會出現某個屬性的影響遠遠大于其他屬性甚至其他所有屬性之和的現象,從而降低了其他屬性在相似性度量中的作用,影響了樣本類別的劃分,對最終的聚類效果產生一定的影響。
3 實驗結果及分析
本文實驗中選擇MyEclipse作為開發工具,使用java語言對算法進行實現。
3.1 聚類效果的評價
評價一項工作的結果,首先要找出評價的標準,進而根據標準確定評價指標,利用定量化的方法來實現科學的評價。本文中所用的評價標準基于準確率、召回率與F值[5]。對數據集中每個人工標注的主題為Pl。假設在聚類算法形成的類層次結構中存在一個與之對應的簇Cl。為了發現Cl,遍歷聚類結果C={C1,C2,…,Ck},計算準確率、召回率和F值,從中挑選最優指標值及其對應的簇,以該最優的指標值來判定Pl的質量。對于任何人工主題Pl和聚類簇Cl:

3.2 實驗結果
從UCI[6]數據集上選取4個數據集Iris,Wine,Soybean(small),Vehicle進行聚類分析。UCI數據集是一個專門用于測試機器學習、數據挖掘算法的公共數據集。本文對4個數據集進行了標準化和未標準化的對比實驗,圖1列出了本文算法未經標準化處理的實驗結果。
從上述實驗結果可以看出,改進算法對數據集Wine和Soybean聚類后值有大幅的提高,提高了20%左右。而另外兩個數據集Iris,Vehicle則有所降低。Wine數據集有178個數據,分成3類,每個數據項有13個屬性,各個屬性的取值范圍差距較大。Alcohol(屬性1),Flavanoids(屬性8),Color_intensity(屬性11)這3個屬性對分類最為重要,它們的取值范圍分別為:(0.34~5.08),(1.28~13),(11.03~14.83),而對分類貢獻不大的屬性Proline(屬性13)的取值范圍是(278~1 680),在采用歐式距離計算相似性時,屬性Proline起到了絕對的作用,導致使用歐氏距離聚類時嚴重降低了效果,而使用本文提出的相似度量方法則明顯地減弱Proline(屬性13)的影響,提高了聚類的結果。數據集Soybean的分布與Wine相似。

圖1 原始數據未標準化的實驗結果
由于數據集Iris的兩個重要屬性1(sepal length),屬性2(sepal width)的取值都較屬性3 (petal length)和屬性4(petal width)大或相當,所以在這個數據集上并沒有體現出本文提出的度量方法的優勢。數據集Vehicle的分布跟Iris相似,故聚類結果沒有大的變化。圖2列出了標準化后的實驗結果。

圖2 原始數據標準化后的實驗結果
從圖2結果可以看出,在4個數據集上用改進算法都較原算法得到較好的聚類結果。
綜合圖1、圖2及實驗中得到數據可以得到如下結論:
(1)數據未標準化采用本文算法進行聚類,在數據集Wine,Soybean上的聚類效果好于原始的K均值算法,而在數據集Vehicle和Iris上,則效果有所下降。
(2)數據標準化和數據不標準化采用本文算法進行聚類,在大多數數據集上聚類效果波動不大,故改進算法相對于原算法有較為穩定的聚類結果。
4 結語
本文提出了一種新的相似性度量方法。由于它把每個屬性的相似系數都映射到(0,1]之間,對于傳統的聚類算法把對象中每個屬性在聚類過程中的貢獻看作是相同的假設,有更好的可解釋性。在本文改進的K均值算法中,對于初始中心點的選取,只是盡量取各維數上的稀疏點,從根本上講也是基于距離因素的選取。實際上,對于初始中心點,除了希望分布的盡量分散之外,還希望這些中心點具有一定的代表性,而本文改進的算法中并沒有考慮到該因素,所以在初始中心點的選取上本文方法還有待進一步完善。
[1]HAN Jiawei,MICHELINE K.數據挖掘概念與技術[M].北京:機械工業出版社,2005.
[2]KANUNGO T,MOUNT D M.A local search approximation algorithm for k-means clustering[J].Computational Geometry,2004,28:89-112.
[3]BRADLEY P S,FAYYAD U M.Refining initial points for k-means clustering[C]//Proceedings of the 15th International Conference on Machine Learning,Morgan Kaufmann,San Francisco,CA,1998.
[4]史金成.基于相關性的數據流聚類及其應用研究[D].合肥:合肥工業大學,2007.
[5]張堯庭,方開泰.多元統計分析引論[M].北京:科學出版社,1982.
[6]http://archive.ics.uci.edu/ml/index.html.
An Improved K-Means Clustering Algorithm
MENG Jia-na,DENG Li-ling,YU Yu-hai,TANG Pin-zhong
(College of Science,Dalian Nationalities University,Dalian Liaoning 116605,China)
According to the disadvantages of calculating similarity based on traditional Euclidean distance of K-Means algorithm,a new similarity metrics method is presented.The given method is compared with the Euclidean distance of the K-Means clustering algorithm.The experiments based on UCI benchmark data sets showed that the method has more stable clustering results,and is an effective clustering metrics method.
cluster analysis;K-Means;similarity
TP18
A
1009-315X(2011)03-0274-03
2010-12-17;最后
2011-01-14
中央高校基本科研業務專項資金資助項目(DC10040118);大連民族學院教學改革項目(Y-09-2009-03)。
孟佳娜(1972-),女,吉林四平人,副教授,主要從事數據挖掘、自然語言處理研究。
(責任編輯 鄒永紅)
猜你喜歡
中老年保健(2021年9期)2021-08-24 03:52:04
河北畫報(2021年2期)2021-05-25 02:07:46
中學生數理化(高中版.高考理化)(2020年2期)2020-04-21 05:33:04
兒童繪本(2020年5期)2020-04-07 17:46:30
兒童故事畫報(2019年5期)2019-05-26 14:26:14
Coco薇(2016年2期)2016-03-22 02:42:52
山東青年(2016年1期)2016-02-28 14:25:23
Coco薇(2015年1期)2015-08-13 02:47:34
小雪花·成長指南(2015年7期)2015-08-11 15:03:12
小雪花·成長指南(2015年4期)2015-05-19 14:47:56
