GPU 提速疊前時間體偏移技術(shù)
2011-01-11 08:14:56張慧宇劉路佳劉偉峰周李軍
物探化探計算技術(shù) 2011年5期
張慧宇,劉路佳,張 兵,劉偉峰,周李軍
(1.中國石化石油物探技術(shù)研究院,江蘇南京 210014;2.中國石化石油勘探開發(fā)研究院 信息技術(shù)研究所,北京 100083;3.中國石油化工集團公司 多波地震技術(shù)重點實驗室,北京 100083)
GPU 提速疊前時間體偏移技術(shù)
張慧宇1,劉路佳1,張 兵1,劉偉峰2,3,周李軍1
(1.中國石化石油物探技術(shù)研究院,江蘇南京 210014;2.中國石化石油勘探開發(fā)研究院 信息技術(shù)研究所,北京 100083;3.中國石油化工集團公司 多波地震技術(shù)重點實驗室,北京 100083)
為了進一步提高疊前時間體偏移的計算效率,實現(xiàn)了在GPUCPU協(xié)同并行計算模式下Kirchhoff疊前時間體偏移技術(shù),并進行優(yōu)化。經(jīng)在NvidaTeslaC1060GPU上的測試表明,GPU(GraphicProcessingUnit)的處理速度是CPU(單核)的四十倍左右。同時表明,CUDA(ComputeUnifiedDeviceArchitectare)編程為CPU向GPU的轉(zhuǎn)化提供了一個較為方便的語言環(huán)境。
CUDA編程;GPU計算;Kirchhoff疊前時間體偏移;并行計算
0 前言
隨著勘探技術(shù)的發(fā)展,地震數(shù)據(jù)規(guī)模越來越大,對處理周期的要求卻越來越短,意味著地震數(shù)據(jù)處理對計算設(shè)備的要求不斷提升。近兩年來,由于GPU擁有強大的并行計算能力,使得 GPU計算在地球物理領(lǐng)域的研究受到廣泛關(guān)注[1]。美國休斯頓的Headwave公司是一家專門從事地學數(shù)據(jù)分析的公司,開發(fā)了新一代計算平臺,支持疊前地震數(shù)據(jù)的分析與解釋。在平臺開發(fā)中,充分利用圖形卡的并行計算潛力,以支撐實時工作流程、實時可視化和實時計算。Headwave公司采用了NVIDIA的GPU計算產(chǎn)品,使用CUDA軟件環(huán)境。通過GPU計算技術(shù)的采用,大大加快了地球物理數(shù)據(jù)分析的速度。Peakstream公司采用二種克希霍夫偏移計算算法的變種,對GPU加速性能進行了試驗,取得了最高達二十七倍的加速結(jié)果。
地震數(shù)據(jù)處理主要包括三大模塊:反褶積、疊加、偏移。其中,偏移是整個處理過程中最復(fù)雜最耗時的環(huán)節(jié)。偏移的方法有很多種,疊前偏移和疊后偏移、時間偏移和深度偏移、二維偏移和三維偏移等。三維Kirchhoff積分法疊前時間偏移是一種常用的偏移方法,具有成像精度高,偏移速度較快的特點,適合于橫向速度變換不太大地區(qū)的地震數(shù)據(jù)處理。若將該方法用GPU進行提速,會進一步縮短處理周期,提高計算效率,加強實用化程度。
1 GPU 計算與 CUDA 編程[2~5]
GPU是圖形處理單元(GraphicProcessingU-nit)的簡稱,是目前通用計算機系統(tǒng)中專門從事圖形計算的單元,其應(yīng)用極為廣泛。與常規(guī)CPU不同的是,GPU中大部份晶體管被用來進行數(shù)據(jù)處理(見下頁圖1),只有少量被用作數(shù)據(jù)緩存和指令流控制。因此,GPU特別適合運行單程序多數(shù)據(jù)流的數(shù)據(jù)并行處理任務(wù),即主要支持SPMD并行計算模式。目前,GPU的計算性能已達1TFLOPS。
CUDA(ComputeUnifiedDeviceArchitecture,計算統(tǒng)一設(shè)備架構(gòu))是NVIDIA公司2007年推出的GPU通用計算產(chǎn)品,是一種將GPU作為數(shù)據(jù)并行計算設(shè)備的軟、硬件體系。CUDA采用了比較容易掌握的類C語言進行開發(fā),開發(fā)人員不必重新學習語法。CUDA將用于GPU上計算的并行代碼用NVCC編譯器編譯,用于CPU上進行計算的串行代碼用標準的C編譯器進行編譯。此外,CUDA除了提供C語言編程接口外,還提供Fortran語言編程接口。這里,我們利用C語言調(diào)用CUDA子程序,來實現(xiàn)基于GPU的疊前時間體偏移算法。所用的GPU設(shè)備是NVIDIA公司生產(chǎn)的TeslaS1070,包含四塊TeslaC1060卡,每塊有240個核,主頻為1.30GHz,浮點運點能力達到1TFLOPS。
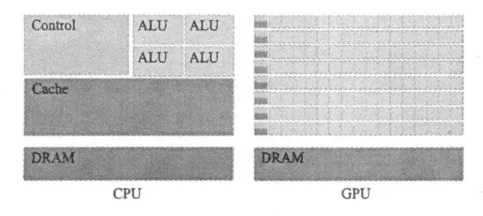
圖1 CPU與GPU晶體管的使用Fig. 1 GPU use more transistors in computing
2 Kirchhoff積分法疊前時間體偏移[6]
一般的Kirchhoff積分法疊前時間偏移是按輸出道的觀點,把一個輸入的地震道振幅按Kirchhoff積分偏移公式,發(fā)散到不同時刻的等時面上,這種方案適合小規(guī)模數(shù)據(jù)體計算。但是,在進行大規(guī)模數(shù)據(jù)的積分法疊前成像處理時,該方案的缺陷就非常明顯:由于偏移孔徑很大,導(dǎo)致輸入數(shù)據(jù)的重復(fù)次數(shù)很多,大大增加了I/O量。為了克服這一缺點,作者在本文采用適于大規(guī)模數(shù)據(jù)的三維Kirchhoff積分法疊前時間體偏移方法。
與一般的Kirchhoff積分法疊前時間偏移不同,該方法是按共偏移距數(shù)據(jù)體進行偏移成像,其處理流程如圖2所示。
(1)數(shù)據(jù)按偏移距進行排序。
(2)對每個共偏移距數(shù)據(jù)體進行并行體偏移計算;按共偏移距數(shù)據(jù)體中的Inline線分配作業(yè),每條線一個進程;每個進程的成像輸出空間大小,等于疊加后的全局成像數(shù)據(jù)體,放在局部盤上。
(3)一個共偏移距數(shù)據(jù)體偏移完后,規(guī)約收集每個處理器對應(yīng)的局部盤上的成像結(jié)果;把規(guī)約疊加后的結(jié)果移到全局盤上;清除局部盤上的空間,為下一個共偏移距數(shù)據(jù)的偏移做準備。
(4)所有偏移距的數(shù)據(jù)偏移完,全局盤上就有了所有偏移距數(shù)據(jù)對應(yīng)的成像結(jié)果;重排序可以得到每點的成像道集;成像道集修飾疊加,可以得到最后的疊前偏移成像結(jié)果。
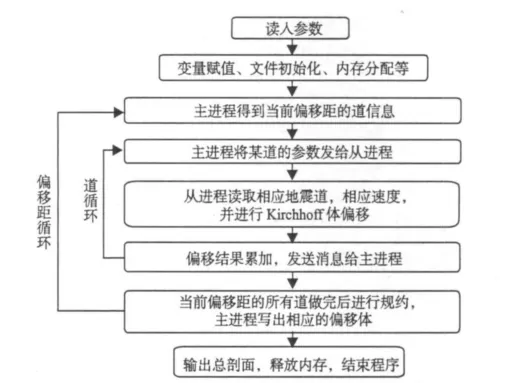
圖2 疊前時間體偏移流程圖Fig. 2 Technological process of seismic prestacktime migration
3 基于GPU的算法實現(xiàn)
GPU的優(yōu)勢在于天生的并行計算體系結(jié)構(gòu),但在邏輯判斷、非線性尋址等方面,卻遠不如CPU。因此,使用GPU處理數(shù)據(jù)并行任務(wù),而由CPU進行復(fù)雜邏輯和事務(wù)處理等串行計算,就可以最大限度地利用計算機的處理能力。作者的研究,正是在GPUCPU協(xié)同并行模式下實現(xiàn)的。
(1)首先基于上述流程,對算法進行并行分析。可以看出,該方案主要有兩層循環(huán),外層的偏移距循環(huán)和內(nèi)層的道循環(huán)。由于GPU的顯存有限,只有4G,所以采用將道循環(huán)在GPU上運行的方案。
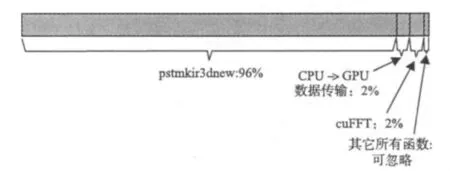
圖3 算法各部份計算時間統(tǒng)計Fig. 3 Time statistics of algorithm of each part
(2)在初步確定并行方案后,對程序中的各個子函數(shù)進行時間測量,找出其中的“熱點”函數(shù),著重進行GPU改造。圖3為算法各部份計算占用時間的統(tǒng)計,由圖3可見,偏移內(nèi)核函數(shù)(pstmkir3dnew)占用了絕大部份的計算時間,而FFT計算時間及GPUCPU數(shù)據(jù)傳輸時間分別各占2%,其它函數(shù)計算時間幾乎可以忽略不計,所以我們主要關(guān)注偏移內(nèi)核函數(shù)的優(yōu)化。
基于GPU的內(nèi)核函數(shù)優(yōu)化,最重要的是如何分配線程層次。對GPU而言,有三級并行層次,即:線程、線程塊,線程網(wǎng)格。作者在本文中方法基于成像體空間分配線程層次,每個線程計算三維成像體橫截面的一個成像點,將整個成像橫截面規(guī)則地分成多個線程塊,再由整個線程塊結(jié)構(gòu)組成一個線程網(wǎng)格,結(jié)構(gòu)見圖4。
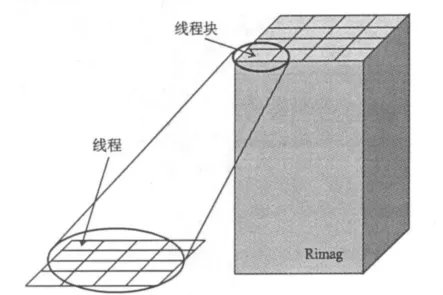
圖4 線程分配策略Fig. 4 Thread allocation strategies
通過以上步驟,基本上實現(xiàn)了算法的GPU改造。為了進一步提高計算效率,還需要做一些算法優(yōu)化。
4 基于GPU的算法優(yōu)化
(1)減少數(shù)據(jù)I/O時間。我們知道,在傳統(tǒng)的集群計算中如何降低數(shù)據(jù)I/O消耗非常重要。在基于GPU的計算中,由于GPU的計算速度非常快,所以數(shù)據(jù)I/O問題更加顯著。
前面已經(jīng)提到,CUDA具有三層并行層次,相對于這三個層次,CUDA也提供了三層存儲器結(jié)構(gòu):①線程本身的寄存器和局部存儲器;②線程塊的共享存儲器;③線程網(wǎng)格的全局存儲器。此外,還有兩種只讀存儲器:常數(shù)存儲器和紋理存儲器[2]。相對于GPU的高速計算能力,GPU對片外存儲器的訪存具有較高的訪存延遲。為解決這一難題,就要充分發(fā)揮各種存儲器的作用。例如:將一些全局常量存入常量存儲器,以便利用GPU上的常量cache減低對片外顯存的訪問量。
(2)利用CUDA提供的一些快速計算函數(shù)。在不影響精度的前提下,可以使用CUDA所提供的內(nèi)建函數(shù),來提高計算效率,如:__sinf(x),__fdividef(x),__expf(x)等。
通過上述算法優(yōu)化,可使基于GPU的疊前時間體偏移計算效率速度提升近四十倍。
5 數(shù)據(jù)測試
為了驗證算法的正確性及運算效率,作者采用某三維數(shù)據(jù)進行了數(shù)據(jù)測試。該工區(qū)覆蓋面積為54.17km2,總道數(shù)達594 ×104,記錄時間6s,采樣2ms,數(shù)據(jù)總體大小為73GB。該工區(qū)的特點是有負向背斜構(gòu)造及大傾角構(gòu)造,偏移參數(shù)為:成像網(wǎng)格為25m×25m,最大偏移孔徑為8000m,最大成像角度In_line和Cross_line方向分別為60°和30°,測試環(huán)境如表1所示。
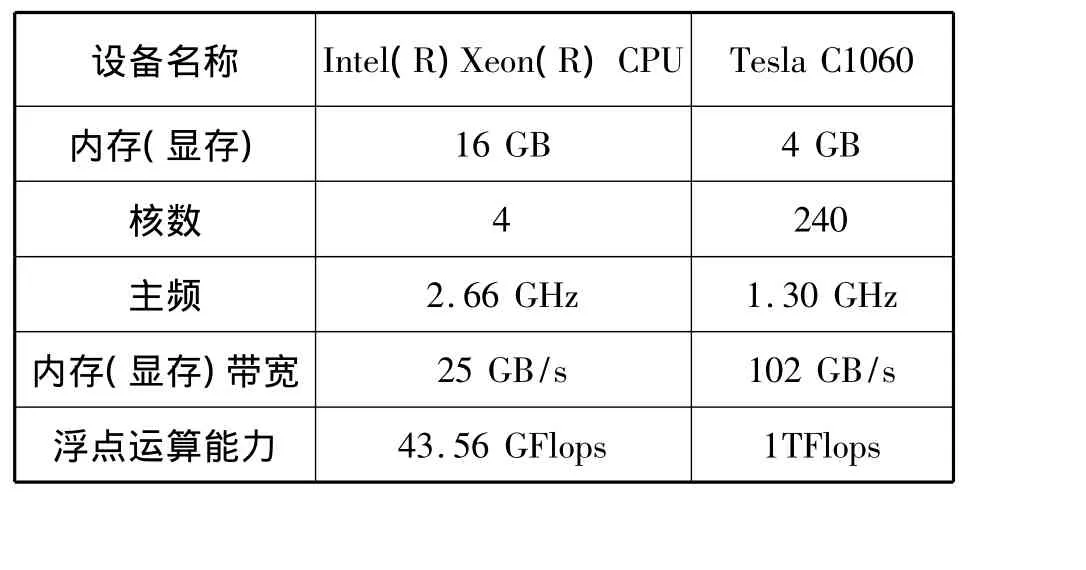
表1 測試環(huán)境Tab. 1 Test environment
偏移剖面局部圖如下頁圖5所示。在圖5展示的兩個剖面,從視覺上看不出差別。為了比較CPU計算結(jié)果和GPU計算結(jié)果的精確誤差,我們采用下述的均方誤差公式,對數(shù)據(jù)進行誤差分析與統(tǒng)計,如下頁圖6所示,縱軸為百分比,橫軸為相對誤差大小(千分之)。
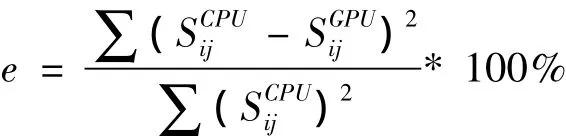
通過分析計算,偏移剖面的均方誤差大小為:0.002%,其中相對誤差小于0.1%所占的比重為85.48% ,可以說明基于GPU的三維疊前時間體偏移算法是正確的。計算時間如下頁表2所示。
由表2可以看出,GPU單卡相對于CPU單核的加速比約為四十倍。
6 結(jié)論
作者在本文中實現(xiàn)了基于GPU的三維疊前時間體偏移技術(shù),經(jīng)在NvidaTeslaC1060GPU上的測試表明,GPU的處理速度是CPU(單核)的四十倍左右。該方法為將來做大規(guī)模數(shù)據(jù)處理,提供了高效的技術(shù)平臺。同時表明,CUDA編程為CPU向GPU的轉(zhuǎn)化,提供了一個較為方便的語言環(huán)境。經(jīng)過此次技術(shù)積累,要加快偏移新方法以及其它處理技術(shù)向GPU平臺的移植進度,以適應(yīng)當前地球物理技術(shù)的發(fā)展。
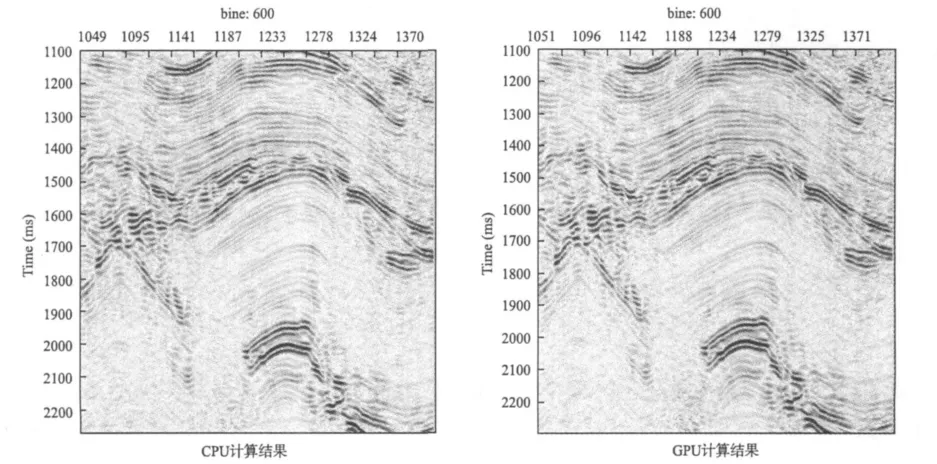
圖5 某三維數(shù)據(jù)測試結(jié)果局部剖面Fig. 5 Image after pstm on CPU and GPU
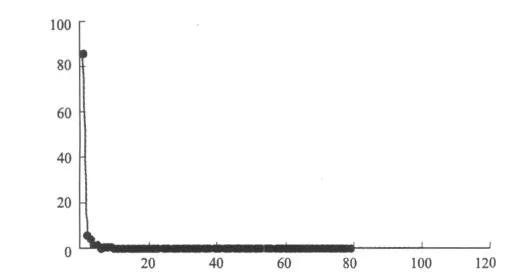
圖6 誤差統(tǒng)計圖Fig. 6 Error statistical figure

表2 某三維數(shù)據(jù)測試時間對比Tab. 2 Time contrast diagram of test 3D data
[1] 趙改善.地球物理高性能計算的新選擇:GPU計算技術(shù)[J].勘探地球物理進展,2007,30(5):399.
[2] 張舒,褚艷利,趙開勇,等.GPU高性能運算之CUDA[M].北京:中國水利水電出版社,2009.
[3] 張兵,趙改善,黃俊,等.地震疊前深度偏移在CUDA平臺上的實現(xiàn)[J].勘探地球物理進展,2008,31,(6):427.
[4] 王華忠,蔡杰雄,孔祥寧,等.適于大規(guī)模數(shù)據(jù)的三維Kirchhoff積分法體偏移實現(xiàn)方案[J].地球物理學報,2010,53(7):1699.
[5] 孔祥寧,趙改善,王華忠,程玖兵.疊前偏移計算中多文件并行 I/O技術(shù)[J].物探化探計算技術(shù),2005,27(2):97.
[6] 劉國峰,劉洪,王秀閩,等.Kirchhoff積分疊前時間偏移的兩種走時計算及并行算法[J].地球物理學進展,2009,24(1):131.
[7] 鄒振,劉洪,劉紅偉.Kirchhoff疊前時間偏移角度道集[J].地球物理學報,2010,53(5):1207.
[8] 滕人達,劉青昆.CUDA、MPI和OpenMP三級混合并行模型的研究[J].微計算機應(yīng)用,2010,31(9):63.
[9] 李博,劉國峰,劉洪.地震疊前時間偏移的一種圖形處理器提速實現(xiàn)方法[J].地球物理學報,2009,52(1):245.
[10] 李肯立,彭俊杰,周仕勇.基于CUDA的Kirchhoff疊前時間偏移算法設(shè)計與實現(xiàn)[J].計算機應(yīng)用研究,2009,26(12):4474.
TP332
A
1001—1749(2011)05—0568—04
國家高技術(shù)研究發(fā)展計劃(863計劃)(2009AA01A140)
2011-03-22 改回日期:2011-06-19
張慧宇(1983-),女,碩士,現(xiàn)從事石油物探應(yīng)用軟件研究與開發(fā)。
