一種基于關系數據庫的出行路徑快速檢索算法
2010-11-27 01:46:16汪長勤
網絡安全與數據管理 2010年19期
劉 晟,汪長勤
(1.安徽大學 計算機教學部,安徽 合肥 230039;2.安徽大學 計算機學院,安徽 合肥 230039)
隨著交通運輸和經濟的發展,越來越多的出行者需要考慮合理地選擇出行方案。通常可供出行者選擇的出行方案比較多,如何為出行者快速提供到達目的地的可行性出行方案,是現今旅游、交通運輸等行業迫切需要解決的實際問題,同時也是學者研究的熱點和難點之一[1-3]。為了解決交通出行問題,研究人員提出了出行路徑選擇模型與算法。出行選擇模型主要以換乘次數最少與出行距離最短為優化目標,其目的是尋找一條最優路徑[4]。現有的出行路徑選擇模型多為基于“出行距離最短”或“出行耗時最少”的最短路模型,而楊新苗等人的研究結果表明“換乘次數”是大部分乘客在選擇出行方案時首先考慮的因素,“出行距離最短”為第二目標[5]。而且出行選擇模型的求解思想是將多目標規劃問題轉化為單目標規劃問題,或者將多目標問題轉化為有主次之分的多層單目標規劃問題[6]。從理論上講,出行者的起點到終點的出行方案可多達數千甚至上萬條,而且可選擇的交通工具類型也是多源的。因此出行路徑選擇模型中所涉及的多源交通數據量較大且關系復雜,目前多選擇利用關系數據庫存儲出行路徑選擇模型中所涉及的交通基礎數據[6-8]。故對這些交通數據檢索并最終確定最優的出行方案需要大量時間,而目前大多數的交通出行方案的查詢只是針對如飛機、火車或者汽車的這種單一的交通工具的點到點查詢。本文以關系數據庫SQL Server為存儲工具,采用基于分層結構首尾協同的出行路徑模型進行快速、準確查詢出多種交通工具組合的出行方案。
1 路徑選擇模型
由于交通出行路徑查詢中涉及多源的交通數據較多,導致從出行者的起點到終點的出行方案很多。為了能夠快速準確查詢出可行的出行方案,本文采用了基于分層結構首尾協同的出行路徑模型來快速準確查詢可行的出行路線。該模型的基本思想就是同時從起點(S)和終點(T)查詢中轉站信息,直到找到匹配的可行方案。這樣可以相對快速、準確地查詢出多種交通工具組合的出行方案。該模型的出行方案查詢策略如圖1所示。

圖1 基于分層結構首尾協同出行方案查詢策略圖
該模型主要包括以下幾個部分:(1)選用SQL Server存儲的交通數據及該模型中所產生的中間數據;(2)同時從起點(S)和終點(T)查詢中轉站信息,然后再對中轉站信息進行匹配和查詢,直到找到可行出行方案;(3)比較給出可行出行方案。
該模型的具體描述如下:
(1)利用SQL Server建立包括交通信息表、臨時堆棧表、方案主表、方案子表和一些輔助臨時表等一系列的關系數據表。
(2)從起點(S)開始向前查詢出所有經過起點的交通信息集合。設這些信息集合為S1且層次為1;再以S1為起點向前查詢經過S1的所有交通信息集合(不含同種交通工具的重復信息),設這些信息集合為S2且層次為2;則第i次搜索形成信息集合為Si且層次為i;經過若干次搜索后可將以起點為出發點以終點為目的的整個交通數據搜索完畢。
(3)從終點(T)開始向后查詢出所有經過終點的交通信息集合。設這些信息集合為T1且層次為1;再以T1為起點向前查詢出經過T1的所有交通信息集合,設這些信息為 T2且層次為2,則第j次搜索形成信息集合為 Tj且層次為j,經過若干次搜索后可將以終點為出發點以起點為目的的整個交通數據搜索完畢。
(4)比較Si中任意中轉站集中任意和Tj中相同的中轉站,找到從起點到終點的出行可行方案。基于分層結構首尾協同的兩次以內中轉出行路徑查詢算法的流程圖如圖2所示。
由圖1可以得出如表1所示的直達、一次和二次轉車出行條件。
2 算法實現
基于SQL Server的存儲平臺,設計了包含交通信息表(表2)、臨時堆棧表(表 3)、方案主表、方案子表和一些輔助臨時表等用來存儲路徑選擇過程中所涉及的數據。其中交通信息表格用來存儲交通基礎信息,該表中包括車次/航班號、站點序號以及站點編號等字段。臨時堆棧表用來將每次查詢出的車次信息按層次保存。方案子表是出行方案的明細,同一方案而言,如果是直達的,則只有一條數據;如果是中轉的,則數據個數為中轉次數加1且數據為方案車次/航班的匯總信息。方案主表是方案子表明細的匯總,具體字段見表4。
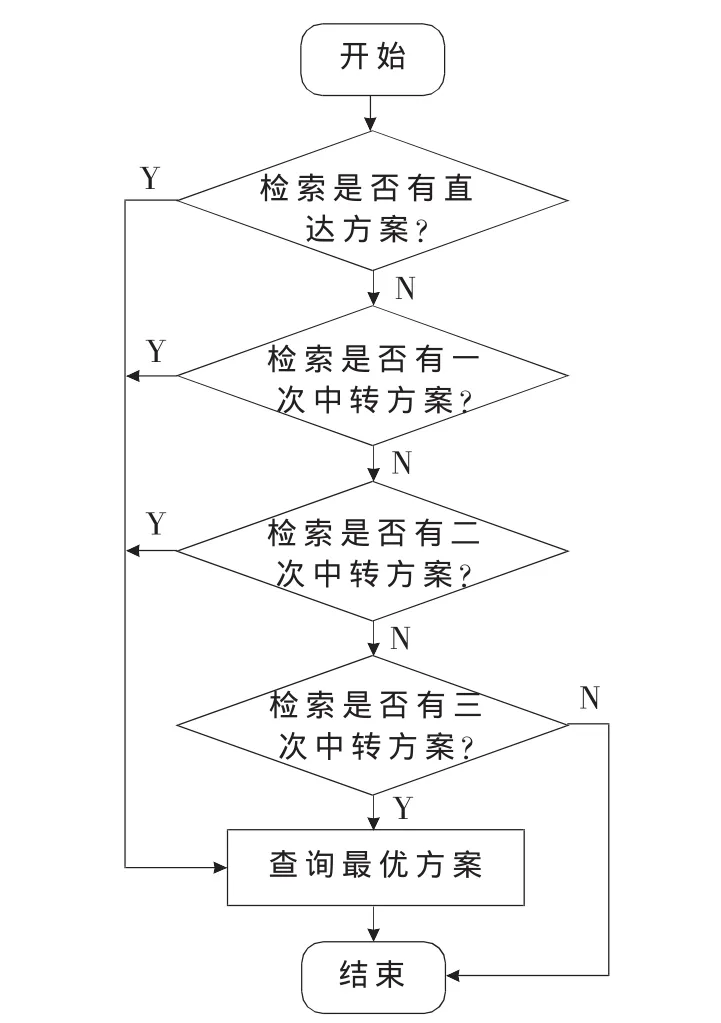
圖2 方案查詢算法流程圖

表1 中轉類型及其條件
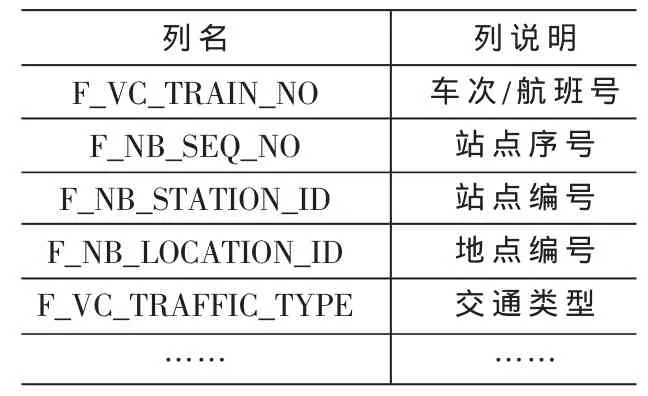
表2 交通信息表(T_TRAFFIC_INFO)
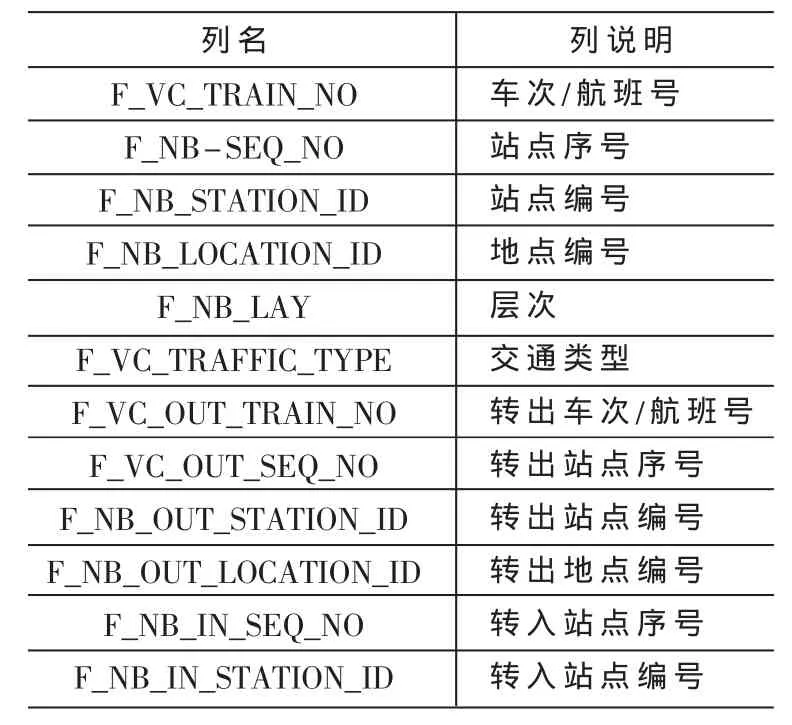
表3 臨時堆棧表(#T_STACK)

表4 臨時方案子表(#T_RESULTZB)
3 應用與結果分析
首先,根據圖2和表1確定中轉車次數最少的方案,根據方案查詢出相應的信息,并將信息保存到臨時堆棧表中(為解決同城多個站點中轉問題,中轉時使用地點編號作為中轉條件);然后,生成可行的出行方案并保存到臨時結果子表中;最后,對臨時結果子表進行匯總并將結果保存到臨時結果主表中。
3.1 臨時堆棧表數據查詢
臨時堆棧表的數據是分層的,其S1和S2層是從起點查詢的,T1和T2層是從終點查詢的。其對應的表關聯如下:
第一層:

第二層:

第三層:

第四層:


3.2 臨時結果子表查詢
在臨時堆棧表數據的基礎上,根據表1所對應中轉類型的條件可直接獲得此中轉類型的所有方案數;再將具體的方案信息保存到臨時結果表中(先保存到子表中,主表信息可根據子表的方案號進行匯總得到)。
3.3 結果分析
將起點、終點及其他參數作為存儲過程的入口參數,通過參數便可獲得相應出行方案信息,同時可根據最優策略對這些方案進行排序,從而獲得出行者所需要的方案。
本文討論了一種基于分層結構首尾協同的出行路徑選擇模型,通過對中轉信息進行快速檢索,并對相應信息判斷是否匹配,以便找出相對優化的出行路徑。但該算法僅適合起點(S)與終點(T)中都是有若干條線路途徑的地點。如果兩者中有一點是沒有任何線路經過(即為孤點),文中算法對于出現孤點而無法實現中轉的情況尚未予以考慮。
[1]李文勇,王煒,陳學武.公交出行路徑螞蟻算法[J].交通運輸工程學報,2004,4(4):102-105.
[2]張衛華,陸化普,石琴.公交優先的信號交叉口配時優化方法[J].交通運輸工程學報,2004,4(3):49-53.
[3]DZEROSKIS,LAVRAC N.Relationaldatamining[M].Berlin:Sp ringer, 2001.
[4]譚滿春,李丹丹.基于Vague集的公交出行路徑選擇[J].中 國 公 路 學 報 ,2008(5):86-89.
[5]楊新苗,馬文騰.基于GIS的公交乘客出行路徑選擇模型[J].東南大學學報自然科學版,2000(6):87-91.
[6]徐光美,楊炳需,張偉,等.多關系數據挖掘方法研究[J].計算機應用研究,2006(9):8-12.
[7]AGRAWAL R,SRIKANT R.Mining sequential patterns[C].Proceedings of the 11 th International Conference on Data Engineering, Los Alamitos:IEEE Computer Society Press,1995:3214.
[8]韓愷,岳麗華,龔育昌.利用關系數據庫系統對半結構化數據進行近似查詢[J].中國科學與技術大學學報,2005,35(5):674-682.
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
中華手工(2017年2期)2017-06-06 23:00:31
光學精密工程(2016年6期)2016-11-07 09:07:19
核科學與工程(2015年4期)2015-09-26 11:59:03
中外會展(2014年4期)2014-11-27 07:46:46
中學數學雜志(初中版)(2006年1期)2006-12-29 00:00:00
建筑創作(2001年3期)2001-08-22 18:48:14
祝您健康(1987年3期)1987-12-30 09:52:32
