基于特征辨別能力和分形維數(shù)的特征選擇方法*
2010-08-08 00:51:56夏晶晶朱顥東
網(wǎng)絡(luò)安全與數(shù)據(jù)管理 2010年7期
夏晶晶 ,朱顥東
(1.鄭州牧業(yè)工程高等專科學(xué)校 信息工程系,河南 鄭州 450011 2.中國科學(xué)院成都計(jì)算機(jī)應(yīng)用研究所,四川 成都 610041)
文本分類系統(tǒng)通常采用特征集來表示文檔,這使得特征向量的維數(shù)非常大,有時(shí)會達(dá)到數(shù)十萬維。如此高維的特征對于后續(xù)的分類過程未必全都重要、有益,而且高維的特征可能會大大增加分類的計(jì)算量,使整個(gè)處理過程的效率降低,可能產(chǎn)生與小得多的特征子集相似的分類結(jié)果[1]。因此,必須對文檔的特征向量進(jìn)一步凈化處理,在保持原文含義的基礎(chǔ)上,找出既能反映文本內(nèi)容,又比較簡潔的特征向量,特征選擇就是為解決上述問題而產(chǎn)生的一個(gè)關(guān)鍵選擇方法。該方法不僅能夠解決上述問題,而且在一定程度上還能消除噪聲詞語,使文本之間的相似度更加準(zhǔn)確,既提高了語義上相關(guān)文本之間的相似度,同時(shí)降低了語義上不相關(guān)的文本之間的相似度[2]。
本文首先分析了幾種經(jīng)典的特征選擇方法,提出了特征辨別能力的概念,緊接著把分形維數(shù)引入粗糙集并提出了一個(gè)基于分形維數(shù)的屬性約簡算法,最后把該約簡算法與特征辨別能力結(jié)合起來,提出了一個(gè)綜合的特征選擇方法。該方法首先利用特征辨別能力進(jìn)行特征初選以過濾掉一些詞條來降低特征空間的稀疏性,然后利用所提屬性約簡算法消除冗余,從而使得選擇的特征子集具有較低的冗余性、較好的代表性。
1 幾種經(jīng)典特征選擇方法
目前常用的文本特征選擇方法有 DF、WF、IG、CHI、MI等[3-9]。
1.1 文檔頻DF(Document Frequency)
特征的文檔頻是指在訓(xùn)練語料集中出現(xiàn)該特征的文檔數(shù)。該方法選擇特征時(shí)僅考慮特征所在的文檔數(shù),如果某個(gè)特征在訓(xùn)練語料集中所在的文檔數(shù)達(dá)到一個(gè)事先給定的閾值,則留下該特征,否則刪除。該方法的缺點(diǎn)在于僅考慮特征詞在文檔中出現(xiàn)與否,忽視了特征在文檔中出現(xiàn)的次數(shù)。于是產(chǎn)生了一個(gè)問題:如果特征詞a和b的文檔頻相同,那么該方法就認(rèn)為這兩個(gè)特征詞的貢獻(xiàn)是相同的,而忽略了它們在文檔中出現(xiàn)的次數(shù)。但是,通常情況是文檔中出現(xiàn)次數(shù)較少的詞是噪聲詞,這樣就導(dǎo)致該方法所選擇的特征不具代表性。
1.2 詞頻WF(Word Frequency)
特征的詞頻是指特征在文檔中出現(xiàn)的數(shù)目。使用該方法選擇特征時(shí),特征只有在文檔中出現(xiàn)的次數(shù)達(dá)到一個(gè)閾值時(shí),才被保留,否則予以刪除。該方法的缺點(diǎn)在于僅選擇出現(xiàn)頻繁的詞作為特征,但是有時(shí)候在某個(gè)文檔中出現(xiàn)頻繁的特征對分類貢獻(xiàn)并不大。
1.3 信息增益IG(Information Gain)
信息增益是指特征在某類文檔中出現(xiàn)前后的信息熵之差,該差用平均信息量表示。信息增益的缺點(diǎn)在于不但考慮了特征出現(xiàn)的情況,而且還考慮了特征未出現(xiàn)的種情況。即使某個(gè)特征不在文本中出現(xiàn)也可能對判斷文本類別有所貢獻(xiàn),但實(shí)驗(yàn)證明,這種貢獻(xiàn)十分微小,尤其是在樣本分布和特征分布失衡的情況下,某些類別中出現(xiàn)的特征詞在全部特征詞的比例很小,較大比例的特征詞在這些類別中是不存在的,也就是此時(shí)的信息增益中特征不出現(xiàn)的部分占絕大優(yōu)勢,這將導(dǎo)致信息增益的效果大大降低。
2 特征辨別能力
如果一個(gè)特征對某個(gè)類的貢獻(xiàn)較大,那么該特征對這個(gè)類的辨別能力應(yīng)該較強(qiáng)。為此,本文定義了特征對類別的辨別能力,簡稱特征辨別能力。
定義1 特征辨別能力 表示特征fi對類別ci的辨別能力,用 Feature-Distinguishability(fi,ci)表示。 由于一個(gè)類別的特征詞有多個(gè),因此可用以下公式來表示特征辨別能力:
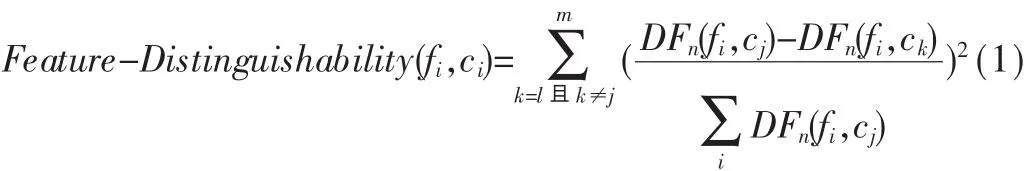
其中 m為屬于類別 cj的特征個(gè)數(shù),DFn(fi,cj)為在類別cj的文本訓(xùn)練集中出現(xiàn)特征fi的次數(shù)不小于n的文本 數(shù) 。 經(jīng) 分 析 可 知 ,F(xiàn)eature-Distinguishability(fi,cj)不 但 考慮了特征出現(xiàn)的文檔數(shù),而且還考慮了特征在文檔中出現(xiàn)的次數(shù),把文檔頻和詞頻進(jìn)行了有機(jī)的結(jié)合。Feature-Distinguishability(fi,cj)越大則表明特征 fi對類別 cj的辨別能力也就越大,那么該特征的分類能力也就越強(qiáng),即該特征也就越重要。
3 本文屬性約簡算法
粗糙集 RS(Rough Sets)理論是由 PAWLAK Z在 20世紀(jì)80年代初提出來的一種新的處理不精確、不相容、不完全和不確定知識的軟計(jì)算工具。其本質(zhì)就是在保持分類能力不變的前提下,通過知識約簡導(dǎo)出問題的分類規(guī)則[10]。目前RS己被廣泛應(yīng)用于機(jī)器學(xué)習(xí)、決策分析、數(shù)據(jù)挖掘、過程控制、智能信息處理等領(lǐng)域[11]。
屬性約簡是粗糙集的核心內(nèi)容之一,現(xiàn)已出現(xiàn)了大量的屬性約簡算法,例如以屬性重要度為基礎(chǔ)的屬性約簡算法[9]、以信息論為基礎(chǔ)的屬性約簡算法[12]。但是這些約簡算法執(zhí)行效率低且不一定能夠得到最小約簡。基于分形維數(shù)的屬性約簡算法可以有效地改變這一狀況[13-14]。本文利用數(shù)據(jù)集的分形維數(shù)進(jìn)行屬性約簡。
3.1 相關(guān)基本知識[15]
如果一個(gè)數(shù)據(jù)集在所有的觀察尺度下都具有自相似性,即一個(gè)數(shù)據(jù)集的部分分布有著與整體分布相似的結(jié)構(gòu)或特征,則稱該數(shù)據(jù)集是分形的。
定義2 嵌入維 數(shù)據(jù)集中的數(shù)據(jù)點(diǎn)所在歐式空間的維數(shù)稱為數(shù)據(jù)集的嵌入維,即一個(gè)數(shù)據(jù)集中屬性的個(gè)數(shù)。
定義3 固有維 一個(gè)數(shù)據(jù)集的固有維是指一個(gè)數(shù)據(jù)集所表示的空間對象的實(shí)際維數(shù)。
一般地說,空間對象的維數(shù)(固有維)不會超過所在歐式空間的維數(shù)(嵌入維)。例如,所有歐氏空間的直線不論嵌入維是二維或是三維,其固有維都是一維的。
定義4分形維 嵌入維數(shù)等于n的數(shù)據(jù)集可視為n維空間中的點(diǎn)。用邊長為 r(r∈(r1,r2))的n維立方體分割數(shù)據(jù)集,記落入第i個(gè)立方體中的數(shù)據(jù)點(diǎn)的數(shù)目為Ci。則分形維Dq計(jì)算如下:
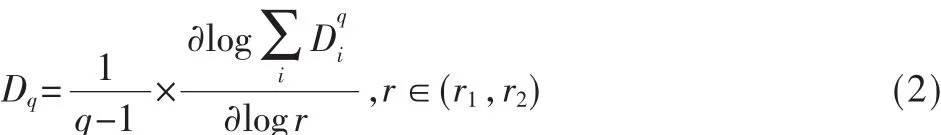
其中D0稱為分形維;當(dāng)q趨近于1時(shí),D1稱為信息分形維;當(dāng)q=2時(shí),D2稱為相關(guān)分形維。D2描述了隨機(jī)選擇的兩個(gè)數(shù)據(jù)點(diǎn)的距離落在某一范圍內(nèi)的概率,因此相關(guān)分形維D2的改變意味著數(shù)據(jù)集中數(shù)據(jù)點(diǎn)分布的變化。在實(shí)際應(yīng)用中,計(jì)算數(shù)據(jù)集的相關(guān)分形維幾乎是不可能的,計(jì)盒維數(shù)常被用來近似估計(jì)相關(guān)分形維數(shù)。
3.2 基于分形維數(shù)的屬性約簡算法
決策表 S=<U,A=C∪D,V,f>其中 U 可以看作E=|C∪D|維空間中的點(diǎn)集,可用于區(qū)分?jǐn)?shù)據(jù)對象的屬性數(shù)目不超過E。由此,可以通過計(jì)算E維空間中的點(diǎn)集的分形維來估計(jì)S應(yīng)包含的最少屬性數(shù)。可通過兩個(gè)計(jì)算步驟來約簡S的屬性集:(1)計(jì)算包括所有E個(gè)屬性的分形維,稱為WFD(全分形維);(2)剔除其中的一個(gè)屬性,再計(jì)算剩余的E-1個(gè)屬性的分形維,稱為PFD(部分分形維),共計(jì)算出 E 個(gè)部分分形維 PFDi,i=1,2,…,E,從這些部分分形維中選擇最接近WFD的PFDi將其對應(yīng)的aj刪除,同時(shí)令 WFD=PFDi在 A=A-{aj}中繼續(xù)上述的步驟,直到剩余屬性數(shù)目與S的分形維數(shù)相同。具體算法描述如下:
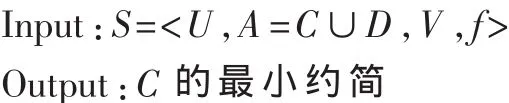
(1)計(jì)算出決策表S的計(jì)盒維數(shù)WFD;令WFD0=WFD。
(2)?ai∈A,計(jì)算 U 在 A-{ai}上的 PFDi。
(3)從 PFD1,… ,PFD|A|中 選 擇 最 接 近 WFD的 一 個(gè)PFDj,令 WFD=PFDj,A=A-{aj}。
(4)如果|A|>W(wǎng)FD0+1,則轉(zhuǎn)(2)。
(5)輸出 A,算法結(jié)束。
在該算法中,計(jì)算有N個(gè)元組的決策表的分形維的時(shí)間復(fù)雜度為O(N×N);從|A|個(gè)屬性中選擇一個(gè)屬性并剔除需要掃描|A|次對象集 U,如果剔除 K(K<|A|)個(gè)屬性,則需要掃描(K×(2|A|l-K+1))/2次,所以整個(gè)算法的時(shí)間復(fù)雜度為 O(|A|×K×N×N)。
4 本文特征選擇方法基本步驟
設(shè)T為原始特征集,C為類別集,對于?cj∈C,設(shè) cj的訓(xùn)練文檔集為DSj,其原始特征集Tj=T,cj的特征詞選擇算法如下:
對于每個(gè)fi∈Tj,給定最小詞頻數(shù)n以及特征辨別能力閾值ω。
(1)計(jì)算 fi的 Feature-Distinguishability(fi,cj)。
(2)若 Feature-Distinguishability(fi,cj)<ω 則 把 fi從 Tj中刪除,否則fi保留。
(3)若Tj中還存在沒考察的元素則轉(zhuǎn)到步驟(1)。
(4)若C中還存在沒考察的類別則轉(zhuǎn)到步驟(1)。
(5)將上述各類別所選的特征合并為1個(gè)特征集。
(6)將步驟(5)得到的特征集以及標(biāo)有類的訓(xùn)練集組成一個(gè)決策表:S=<U,R=C∪D,V,f>, 使用本文提出的屬性約簡算法進(jìn)行屬性約簡。
(7)對得到的特征子集進(jìn)行微調(diào),以突出那些對分類貢獻(xiàn)比較大的特征詞,然后輸出特征集。
5 實(shí)驗(yàn)例證
5.1 實(shí)驗(yàn)語料庫
進(jìn)行文本分類方面的實(shí)驗(yàn),語料庫的選擇是非常重要的,選擇的原則是國內(nèi)外使用廣泛、權(quán)威標(biāo)準(zhǔn)和規(guī)范。這樣使得實(shí)驗(yàn)和國內(nèi)外同行的試驗(yàn)結(jié)果具有可比性,同時(shí)也便于分析實(shí)驗(yàn)數(shù)據(jù)、算法的優(yōu)劣。
在中文文本分類方面,經(jīng)過分析、比較,本文選用的分類語料庫是復(fù)旦大學(xué)中文文本分類語料庫。語料文檔全部采自互聯(lián)網(wǎng),可以從網(wǎng)上免費(fèi)下載,網(wǎng)址為:http://www.nlp.org.cn/categories/default.php?cat_id=16。復(fù)旦大學(xué)中文文本分類語料庫中包含20個(gè)類別,分為訓(xùn)練文檔集和測試文檔集兩個(gè)部分。每個(gè)部分都包括20個(gè)子目錄,相同類別的文檔存放在一個(gè)對應(yīng)的子目錄下;每個(gè)存儲文件只包含1篇文檔,所有文檔均以文件名作為唯一編號。共有19 637篇文檔,其中訓(xùn)練文檔9 804篇,測試文檔9 833篇;訓(xùn)練文檔和測試文檔基本按照1:1的比例來劃分。去除部分重復(fù)文檔和損壞文檔后,共保留有文檔14 378篇,其中訓(xùn)練文檔8 214篇,測試文檔6 164篇,跨類別的重復(fù)文檔沒有考慮,即一篇文檔只屬于一個(gè)類別。該語料庫中的文檔的類別分布不均勻。其中,訓(xùn)練文檔最多的類Economy有1 369篇訓(xùn)練文檔,而訓(xùn)練文檔最少的類Communication有25篇訓(xùn)練文檔;同時(shí),訓(xùn)練文檔數(shù)少于100篇的稀有類別共有11個(gè)。訓(xùn)練文檔集和測試文檔集之間互不重疊。本文只取前10個(gè)類的部分文檔,其類別文檔分布如表1所示。
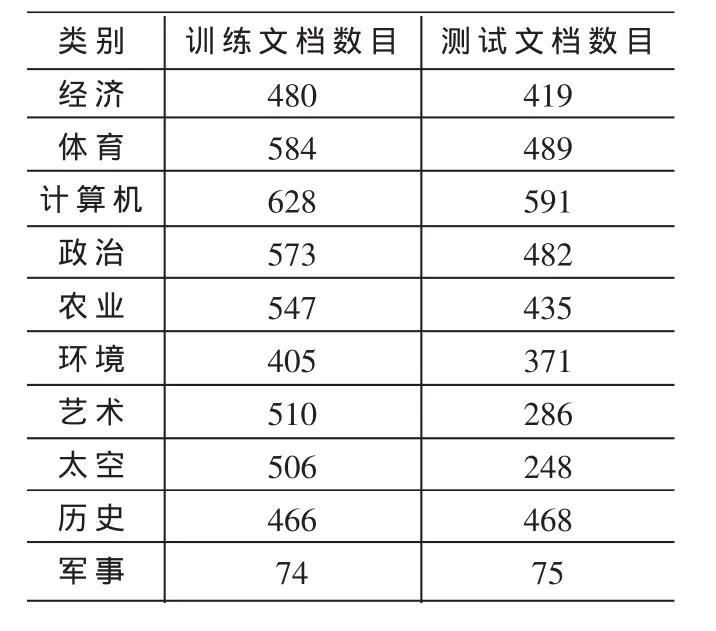
表1 文檔分布
5.2 實(shí)驗(yàn)環(huán)境及參數(shù)設(shè)置
實(shí)驗(yàn)設(shè)備是一臺普通計(jì)算機(jī):操作系統(tǒng)為Microsoft Windows XP Professional(SP2),CPU 規(guī) 格 為 Intel(R)Celeron(R)CPU 2.40 GHz,內(nèi)存 512 MB,硬盤 80 GB。
進(jìn)行中文分詞處理時(shí),采用的是中科院計(jì)算所開源項(xiàng)目“漢語詞法分析系統(tǒng)ICTCLAS”系統(tǒng)。
實(shí)驗(yàn)使用的軟件工具是Weka,這是新西蘭的Waikato大學(xué)開發(fā)的數(shù)據(jù)挖掘相關(guān)的一系列機(jī)器學(xué)習(xí)算法。實(shí)現(xiàn)語言是Java軟件可以直接調(diào)用,也可以在代碼中調(diào)用。Weka包括數(shù)據(jù)預(yù)處理、分類、回歸分析、聚類、關(guān)聯(lián)規(guī)則、可視化等工具,對機(jī)器學(xué)習(xí)和數(shù)據(jù)挖掘的研究工作很有幫助。
本算法中各參數(shù)需要反復(fù)試驗(yàn)各參數(shù)最后設(shè)置如下:n=3,ω=0.09。
5.3 實(shí)驗(yàn)所用分類器及其評價(jià)標(biāo)準(zhǔn)
本實(shí)驗(yàn)旨在比較本文方法與信息增益(IG)、X2統(tǒng)計(jì)量(CHI)、互信息(MI)三種特征選擇方法對后續(xù)文本分類精度的影響,因此實(shí)驗(yàn)采用相同的分類器對文本進(jìn)行分類。實(shí)驗(yàn)中使用KNN分類器來比較這幾種特征選擇方法(K設(shè)置為 10)。
為了評價(jià)實(shí)驗(yàn)效果,實(shí)驗(yàn)中選擇分類正確率和召回率作為評價(jià)標(biāo)準(zhǔn):準(zhǔn)確率=a/(a+b),作為所判斷的文本與人工分類文本吻合的文本所占的比率;召回率=a/(a+c),作為人工分類結(jié)果應(yīng)有的文本與分類系統(tǒng)吻合的文本所占的比率。在實(shí)際應(yīng)用中,查準(zhǔn)率比查全率重要。其中a、b、c代表相應(yīng)的文檔數(shù),其含義如表2所示。
5.4 實(shí)驗(yàn)結(jié)果
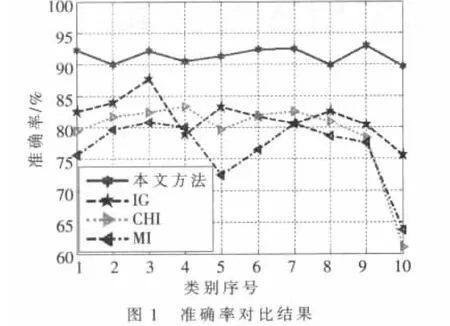
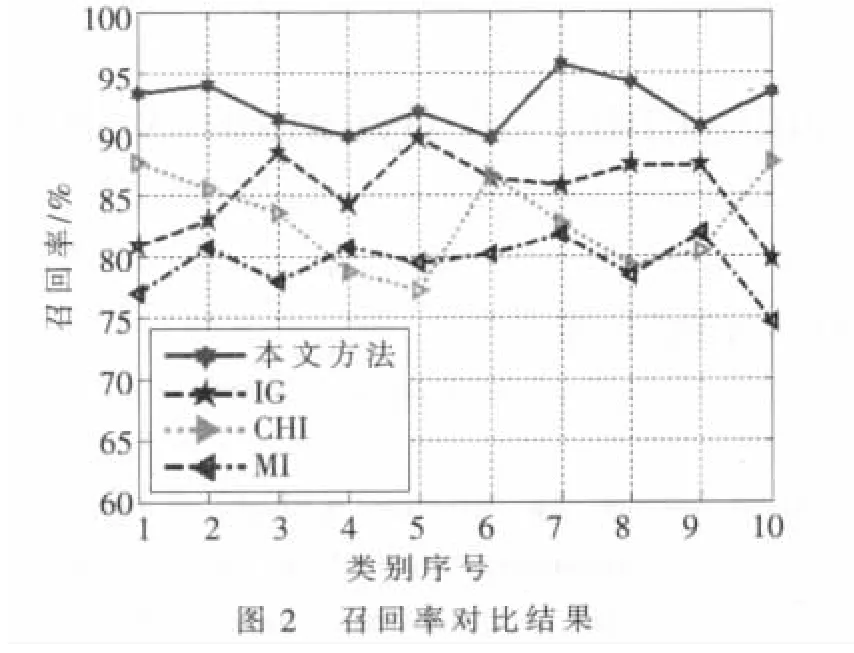
圖1、圖2表明了四種方法在所選數(shù)據(jù)集上的分類準(zhǔn)確率和召回率,從總體上看,本文方法>IG>CHI>MI。由于本方法首先利用特征辨別能力進(jìn)行特征初選以過濾掉一些詞條來降低特征空間的稀疏性,然后利用所提屬性約簡算法消除冗余,從而獲得較具代表性的特征子集,所以效果最佳;由于IG方法受樣本分布影響,在樣本分布不均勻的情況下,其效果就會大大降低,但從整體上看本文所選樣本分布相對均勻,只有極個(gè)別相差較大,所以總體效果次之;MI方法僅考慮了特征發(fā)生的概率;而CHI方法同時(shí)考慮了特征存在與不存在時(shí)的情況,所以CHI方法比MI方法效果要好。總體來說,本文所提的方法是有效的,在文本分類中有一定的實(shí)用價(jià)值。
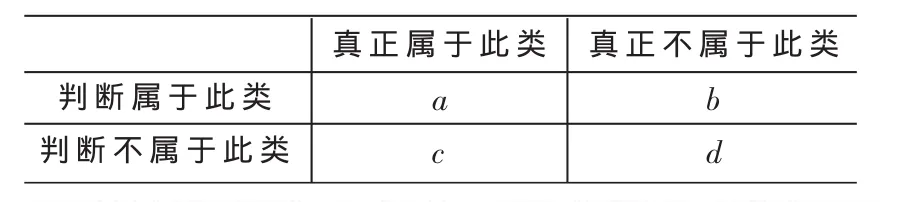
表2 二值聯(lián)表
本文首先簡單分析了幾種經(jīng)典的特征選擇方法,總結(jié)了它們的不足,然后提出了特征辨別能力的概念,緊接著把分形維數(shù)引入粗糙集,并提出了一個(gè)基于分形維數(shù)的屬性約簡算法,最后把該屬性約簡算法與特征辨別能力結(jié)合起來,提出了一個(gè)綜合的特征選擇方法。由于該方法首先利用特征辨別能力進(jìn)行特征初選以過濾掉一些詞條來降低特征空間的稀疏性,然后利用所提屬性約簡算法消除冗余,從而獲得較具代表性的特征子集。實(shí)驗(yàn)證明,本文特征選擇方法與三種經(jīng)典特征選擇方法“互信息”、“x2統(tǒng)計(jì)量”以及信息增益相比,具有較高的準(zhǔn)確率和召回率,為后續(xù)的知識發(fā)現(xiàn)算法減少了時(shí)間與空間復(fù)雜性,從而使得本方法在文本分類中有一定的使用價(jià)值。
[1]DELGADO M,MARTIN M J,SANCHEZ D,et al.Mining text data:special features and patterns[A].In proceedings of ESF exploratory workshop[C].London:U.K, Sept, 2002,32-38.
[2]申紅,呂寶糧,內(nèi)山將夫,等.文本分類的特征提取方法比較與改進(jìn)[J].計(jì)算機(jī)仿真,2006,23(3):221-224.
[3]朱顥東,鐘勇.一種新的基于多啟發(fā)式的特征選擇算法[J].計(jì)算機(jī)應(yīng)用,2009,29(3):849-851.
[4]YANG Y,PEDERSEN J O.A comparative study on feature selection in text categorization[A].In:Fisher DH,ed.Proc.of the 14th Int’l Conf.on Machine Learning(ICML’97)[C].Nashville:Morgan Kaufmann Publishers,1997:412-420.
[5]張海龍,王蓮芝.自動(dòng)文本分類特征選擇方法研究[J].計(jì)算機(jī)工程與設(shè)計(jì),2006,27(20):3838-3841.
[6]宋楓溪,高秀梅,劉樹海.統(tǒng)計(jì)模式識別中的維數(shù)削減與低損降維[J].計(jì)算機(jī)學(xué)報(bào),2005,28(10):1915-1922.
[7]周茜,趙明生,扈曼,等.中文文本分類中的特征選擇研究[J].中文信息學(xué)報(bào),2004,18(3):17-23.
[8]胡佳妮,徐蔚然,郭軍,等.中文文本分類中的特征選擇算法研究[J].光通訊研究,2005(3):44-46.
[9]寇蘇玲,蔡慶生.中文文本分類中的特征選擇研究[J].計(jì)算機(jī)仿真,2007,24(3):289-291.
[10]胡壽松,何亞群.粗糙決策理論與應(yīng)用[M].北京:北京航空航天大學(xué)出版社,2006.
[11]LIANG Ji Ye, CHIN K S, CHUANGYIN D, et al.A new method for measuring uncertainty and fuzziness in rough set theory[J].International Journal of General Systems, 2002,31(4):331-342.
[12]柴慧芳.粗糙集下基于信息熵的知識約簡算法研究[D].昆明:昆明理工大學(xué),2007.
[13]TRAINA C, TRAINA A, WU L, et al.Fast feature selection using fractal Dimension[A].In:C.Faloutsos,ed.Proc.of XV brazilian symposium on Databases, Paraila,Brazil:Springer,2000:78-90.
[14]YAN Guang Hui, LI Zhan Huai, YUAN Liu.The practical method of fractal dimensionality reduction based on Z-ordering technique[C]//LI X,ZAIANE O R,LI Z.Proceedings of the Second International Conference on Advanced Data Mining and Applications.Berlin Heidelberg:Springer-Verlag,2006:542-549.
[15]楊光俊.分形的數(shù)學(xué)[M].昆明:云南大學(xué)出版社,2002.
猜你喜歡
數(shù)學(xué)小靈通(1-2年級)(2021年4期)2021-06-09 06:25:56
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
制造技術(shù)與機(jī)床(2019年10期)2019-10-26 02:48:08
當(dāng)代陜西(2019年10期)2019-06-03 10:12:04
中學(xué)生數(shù)理化·七年級數(shù)學(xué)人教版(2019年4期)2019-05-20 10:06:32
電子制作(2018年18期)2018-11-14 01:48:06
中學(xué)生數(shù)理化·七年級數(shù)學(xué)人教版(2018年6期)2018-06-26 08:36:06
初中生世界·七年級(2017年9期)2017-10-13 22:27:46
數(shù)學(xué)小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
小學(xué)教學(xué)參考(2015年20期)2016-01-15 08:44:38
