分層聚類(lèi)算法在文本挖掘中的應(yīng)用
2010-08-07 08:20:56劉卓徐斌
網(wǎng)絡(luò)安全技術(shù)與應(yīng)用 2010年7期
劉卓 徐斌
蘇州科技學(xué)院電子與信息工程學(xué)院 江蘇 215011
0 引言
自20世紀(jì)80年代以來(lái),隨著Internet技術(shù)的高速發(fā)展,信息化的浪潮席卷全球,社會(huì)的每個(gè)角落都有了數(shù)字化信息的身影。其中尤其以Web頁(yè)數(shù)量最為龐大,并且大約以每4至 6 個(gè)月翻一倍的速度增加。巨量的 Web頁(yè)在為我們提供了海量的信息同時(shí),又給我們提出了新的挑戰(zhàn),即如何從這些浩瀚的Web頁(yè)信息中快捷準(zhǔn)確地得到我們想要的信息。自然我們不能夠采用人工的方式完成這項(xiàng)任務(wù),借助于計(jì)算機(jī)采用數(shù)據(jù)挖掘的方法是目前廣泛使用的技術(shù)。
1 Web文本挖掘概述
數(shù)據(jù)挖掘(data mining)習(xí)慣上又稱(chēng)為數(shù)據(jù)庫(kù)中知識(shí)發(fā)現(xiàn)(Knowledge Discovery in Database, KDD),簡(jiǎn)單的說(shuō)就是利用計(jì)算機(jī),從浩瀚如海的信息資源中找出真正具有價(jià)值的信息。數(shù)據(jù)挖掘可以按以下不同角度分類(lèi):從挖掘的數(shù)據(jù)源分類(lèi),一般可以分為關(guān)系數(shù)據(jù)庫(kù)、事務(wù)數(shù)據(jù)庫(kù)、空間數(shù)據(jù)庫(kù)、時(shí)間數(shù)據(jù)庫(kù)、面向?qū)ο髷?shù)據(jù)庫(kù)、文本數(shù)據(jù)庫(kù)、多媒體數(shù)據(jù)庫(kù)、主動(dòng)數(shù)據(jù)庫(kù)、Internet信息庫(kù)挖掘等。從挖掘出的知識(shí)分類(lèi),一般情況下,數(shù)據(jù)挖掘可以分為關(guān)聯(lián)規(guī)則、特征規(guī)則、分類(lèi)規(guī)則、聚類(lèi)規(guī)則、序列模式、數(shù)據(jù)綜合和概括、總結(jié)規(guī)則 、趨勢(shì)分析、偏差分析、模式分析、孤立點(diǎn)分析挖掘等。按照挖掘所采用的技術(shù)分類(lèi),數(shù)據(jù)挖掘一般可以分為統(tǒng)計(jì)分析方法,遺傳算法、粗糙集方法、決策樹(shù)、人工神經(jīng)網(wǎng)絡(luò)、模糊邏輯、規(guī)則歸納、聚類(lèi)分析、模式識(shí)別、最鄰接技術(shù)、可視化技術(shù)挖掘等。Web挖掘就是數(shù)據(jù)挖掘方法中的一種,它是指從大量Web文檔的集合C中發(fā)現(xiàn)隱含的模式p。如果將C 看作輸入,將p看作輸出,那么Web挖掘的過(guò)程就是從輸入到輸出的一個(gè)映射N(xiāo): C→p。按照挖掘?qū)ο蟮牟煌琖eb挖掘又可以分為兩類(lèi):內(nèi)容挖掘和結(jié)構(gòu)挖掘。內(nèi)容挖掘指的是從Web文檔的內(nèi)容信息中抽取知識(shí),結(jié)構(gòu)挖掘指的是從 Web文檔的結(jié)構(gòu)信息中推導(dǎo)知識(shí)。Web內(nèi)容挖掘又分為對(duì)文本文檔(包括 text,HTML 等格式)和多媒體文檔(包括image,audio,video 等媒體類(lèi)型)的挖掘。Web 文本挖掘可以對(duì)Web上大量文檔集合的內(nèi)容進(jìn)行總結(jié)、分類(lèi)、聚類(lèi)、關(guān)聯(lián)分析,以及利用 Web 文檔進(jìn)行趨勢(shì)預(yù)測(cè)等。本文所探討的對(duì)象為針對(duì)于Web文本文檔的挖掘。
2 Web文本挖掘中的聚類(lèi)算法
聚類(lèi)是根據(jù)個(gè)體所滿(mǎn)足的屬性對(duì)個(gè)體域進(jìn)行剖分,把屬性相同或相近的個(gè)體劃歸為同一個(gè)“概念類(lèi)”的過(guò)程,它是機(jī)器學(xué)習(xí)領(lǐng)域中的一個(gè)重要研究方向。文檔聚類(lèi)的目標(biāo)即使將文檔聚集成類(lèi),使得類(lèi)與類(lèi)之間的相似度盡量的小,而類(lèi)內(nèi)的相似度盡量的大。處理聚類(lèi)問(wèn)題,主要有以下幾種方法:統(tǒng)計(jì)方法、機(jī)器學(xué)習(xí)方法、神經(jīng)網(wǎng)絡(luò)方法和面向數(shù)據(jù)庫(kù)的方法等。
聚類(lèi)算法一般分為分割聚類(lèi)法和分層聚類(lèi)法。分割聚類(lèi)算法通過(guò)一個(gè)評(píng)價(jià)函數(shù)把數(shù)據(jù)集分割為K個(gè)部分,需要K作為輸入?yún)?shù)。典型的分割聚類(lèi)算法有 K-means 算法、K-medoids 算法、CLARANS 算法;分層聚類(lèi)是由不同層次的分割聚類(lèi)組成,層次之間的分割具有嵌套的關(guān)系,不需要K作為輸入?yún)?shù)。典型的分層聚類(lèi)算法是 BIRCH算法、DBSCAN算法和CURE算法。目前,使用聚類(lèi)方法自動(dòng)建立文檔的類(lèi)別過(guò)程通常如下所示:
(1)輸入多篇無(wú)類(lèi)別標(biāo)識(shí)的文本。
(2)借助詞典對(duì)這些文本進(jìn)行分詞處理。
(3)提取每一個(gè)文本的特征向量。
(4)利用文本的特征向量,使用聚類(lèi)算法進(jìn)行類(lèi)別組合計(jì)算。
(5)人工為每個(gè)得到的文本類(lèi)別建立類(lèi)別標(biāo)識(shí)。
3 分層聚類(lèi)法算法實(shí)現(xiàn)
本文采用分層聚類(lèi)法并結(jié)合了改進(jìn)的特征詞權(quán)重計(jì)算等方法,進(jìn)行了無(wú)類(lèi)別文檔集合的劃分處理。具體算法如下:輸入:無(wú)文本類(lèi)別標(biāo)識(shí)的文本集輸出:標(biāo)識(shí)了類(lèi)別的訓(xùn)練文本集(1)文本分詞處理。
(2)統(tǒng)計(jì)詞頻,完成非完整詞串取舍,提取出文本文檔中的關(guān)鍵詞。
(3)公式(1)計(jì)算詞的特征值。
(4)按照詞的特征值使用插入排序算法遞增排序,并從排好序的詞集中提取前M個(gè)詞作為當(dāng)前文檔的特征詞,從而得到每一個(gè)文檔的特征向量di(i=1,2,3,……,n)。
(5)di看作是一個(gè)具有單個(gè)成員的類(lèi)Ci={di},從而構(gòu)成了該文檔集合的一個(gè)聚類(lèi)C(n)={c1,c2,……,cn}。
(6)用公式(2)計(jì)算C中每對(duì)類(lèi)(ci,cj)之間的相似度。
(7)選取具有最大相似度的類(lèi)對(duì),并將其合并為一個(gè)新的類(lèi),從而構(gòu)成該文檔集合的一個(gè)新的聚類(lèi) C(n-1)={c1,c2,……,cn-1}。
(8)如果n!=1,轉(zhuǎn)到步驟3。
(9)對(duì)各個(gè)類(lèi)文檔進(jìn)行人工建立標(biāo)號(hào)。算法說(shuō)明:
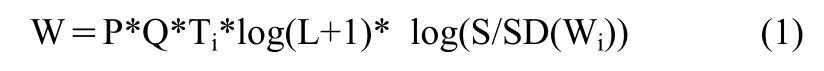
其中:P為位置加權(quán)系數(shù),Q為受限語(yǔ)義加權(quán)系數(shù),L為Wi的長(zhǎng)度,Ti為在文檔中出現(xiàn)的頻率,S為總文檔數(shù),SD為在其中出現(xiàn)至少一次的文檔的數(shù)目。
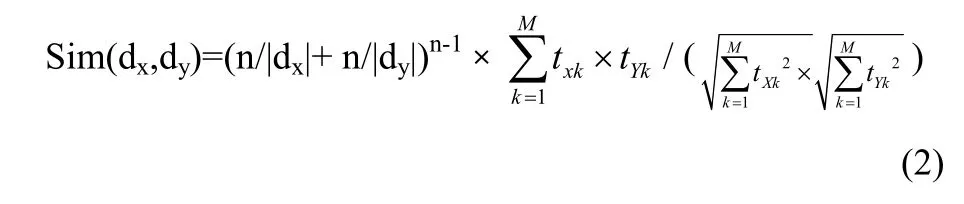
其中:n為文檔 dx與 dy共同所有的特征詞個(gè)數(shù),|dx|文檔dx中特征詞總數(shù),|dy|文檔dy中特征詞總數(shù),txk為向量dx第k維值。
4 結(jié)束語(yǔ)
本文對(duì)文本挖掘中所使用的層次聚類(lèi)分析方法進(jìn)行了探討,通過(guò)以上聚類(lèi)算法的分析處理,我們可以在一定范圍內(nèi)完成對(duì)各類(lèi)訓(xùn)練文本庫(kù)的建立。但是針對(duì)于公式中參數(shù)的選取還需要進(jìn)一步的研究,以便在更大范圍內(nèi)完成訓(xùn)練語(yǔ)料庫(kù)的建立。
[1] 鄒臘梅,肖基毅,龔向堅(jiān).Web 文本挖掘技術(shù)研究.情報(bào)雜志.2007.
[2] 王繼成,潘金貴,張福炎.Web 文本挖掘技術(shù)研究.計(jì)算機(jī)研究與發(fā)展.1999.
[3] J.Han,Micheline,Kamber,Data,Mining:Concepts and Tchniques.San Mateo,CA:Morgan Kaufmann.2000.
[4] 張紅云,石陽(yáng),馬垣.數(shù)據(jù)挖掘中聚類(lèi)算法比較研究.鞍山鋼鐵學(xué)院學(xué)報(bào).2001.
[5] 于琨,糜仲春,蔡慶生.可應(yīng)用與互聯(lián)網(wǎng)的自學(xué)習(xí)中文關(guān)鍵詞抽取算法.中國(guó)科學(xué)技術(shù)大學(xué)報(bào).2002.
[6] 顧立帆,王永成.聯(lián)想樹(shù)分析方法及其在無(wú)詞庫(kù)中文自動(dòng)標(biāo)引中的應(yīng)用.情報(bào)學(xué)報(bào).1992.
[7] 何新貴,彭甫陽(yáng).中文文本的關(guān)鍵詞自動(dòng)抽取和模糊分類(lèi).中文信息學(xué)報(bào).1998.
[8] 羅三定,陸文彥,王浩,賈維嘉.基于概念的文本類(lèi)別特征提起與文本模糊匹配.計(jì)算機(jī)工程與應(yīng)用.2002.
[9] 孫麗華,張積東,李靜梅.一種改進(jìn)的 KNN 方法及其在文本分類(lèi)中的應(yīng)用.應(yīng)用技術(shù). 2002.
猜你喜歡
大眾投資指南(2021年35期)2021-02-16 01:06:26
制造技術(shù)與機(jī)床(2019年10期)2019-10-26 02:48:08
電子制作(2018年18期)2018-11-14 01:48:06
電力與能源(2017年6期)2017-05-14 06:19:37
財(cái)經(jīng)(2017年2期)2017-03-10 14:35:35
財(cái)經(jīng)(2016年15期)2016-06-03 07:38:02
財(cái)經(jīng)(2016年3期)2016-03-07 07:44:46
財(cái)經(jīng)(2016年6期)2016-02-24 07:41:51
小學(xué)教學(xué)參考(2015年20期)2016-01-15 08:44:38
信息通信技術(shù)(2015年6期)2015-12-26 01:16:46
 網(wǎng)絡(luò)安全技術(shù)與應(yīng)用2010年7期
網(wǎng)絡(luò)安全技術(shù)與應(yīng)用2010年7期
- 網(wǎng)絡(luò)安全技術(shù)與應(yīng)用的其它文章
- 移動(dòng)自組網(wǎng)中基于按需加權(quán)的NTDR分簇算法
- OA系統(tǒng)與檔案管理系統(tǒng)數(shù)據(jù)交換的研究與實(shí)現(xiàn)
- 一種基于ARM的電費(fèi)綜合自助系統(tǒng)的設(shè)計(jì)與實(shí)現(xiàn)
- 基于Struts體系結(jié)構(gòu)的企業(yè)績(jī)效考核系統(tǒng)的設(shè)計(jì)與開(kāi)發(fā)
- 跨站腳本攻擊實(shí)踐及防范
- 基于網(wǎng)絡(luò)安全風(fēng)險(xiǎn)控制的DDoS攻擊防御系統(tǒng)設(shè)計(jì)分析