智能空間中的服務機器人路徑規劃
2010-06-21 06:44:24薛英花田國會吉艷青
智能系統學報 2010年3期
薛英花,田國會,吳 皓,吉艷青
(1.山東大學控制科學與工程學院,山東 濟南 250061;2.山東財政學院計算機信息工程學院,山東 濟南 250014)
1996年日本東京大學的Hashimoto實驗室提出了“智能空間”的概念.此后,智能空間作為一種新的技術手段,在國內外都得到了廣泛研究[1-4].將智能空間技術應用于服務機器人系統,可以有效地解決許多機器人靠自身無法解決或難于解決的問題,使得服務機器人應用變得輕松可行[5].
路徑規劃是服務機器人順利完成智能空間中各種服務(如物品抓取、目標跟蹤)的基本環節之一,定義為按照某一性能指標搜索一條從起始狀態到目標狀態的最優或近似最優的無碰路徑.路徑規劃可分為靜態路徑規劃和動態路徑規劃2類[6-8].全局規劃需要環境中的全部先驗信息,而局部規劃則強調避碰行為,雖實時性好,但是由于缺乏規劃,有時會產生局部極值點或振蕩,無法保證機器人順利地到達目標點.智能空間的環境是部分未知的,一方面,智能空間中的整體布局已知,如沙發、茶幾、電視機柜的擺放等;另一方面,環境中存在著不可預知的動態障礙物,如人、另外的機器人等.單獨使用全局規劃和局部規劃都不能滿足智能空間中路徑規劃的安全性、實時性和高效性要求.
本文首先分析了柵格地圖的不足,建立了環境信息更加豐富的危險度地圖;然后采用了分層的路徑規劃方法,既有效利用了已知環境信息,又實現了實時避障.本文充分利用了智能空間的多傳感器和通信網絡,從多角度獲取動態障礙物的信息,使服務機器人可以對環境做出快速反映,安全及時地完成任務.
1 環境模型的建立
柵格法是一種常用的環境建模方法,由于其表示直觀、實現簡單而得到了廣泛應用[9].圖1為根據環境中障礙物的疏密建立的柵格地圖.
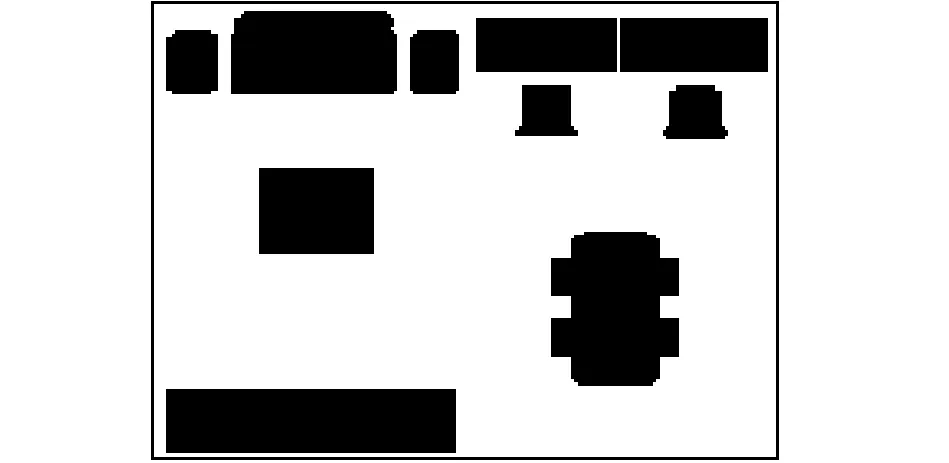
圖1 柵格地圖Fig.1 Grids map
柵格地圖只能表示某處障礙物的有無,不能提供更為詳細的其他環境信息,如該柵格距離障礙物的遠近等.為了能提供更充分的環境信息,采用危險度地圖來表示環境[10].危險度地圖是在柵格地圖的基礎上,充分考慮周圍障礙物與柵格的距離和障礙物的疏密程度而建立的能充分體現該處危險程度的地圖.
設柵格地圖的行數為r,列數為c.柵格的取值用 gij(1≤i≤r,1≤j≤c)表示,危險度用 dij表示.若gij=0,說明該柵格本身就是障礙物,是機器人不可通過區域,因此將其危險度置為最大;若gij=1,說明該柵格為自由柵格,這時應根據其周圍障礙物的多少和距離遠近來計算該柵格的危險度,如式(1)所示:
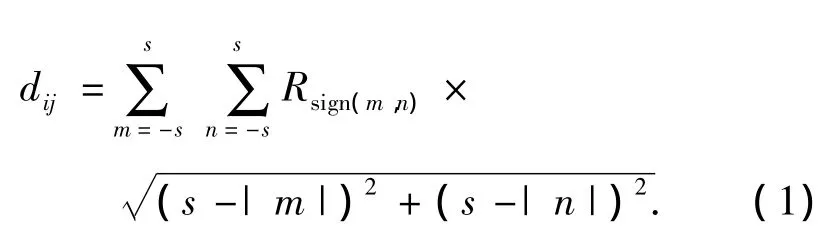
式中:s為窗口尺寸因子,實際窗口大小為(2s+1)×(2s+1);Rsign(m,n)為點(i+m,j+n)處的障礙物標志,當g(i+m,j+n)=0,即該點為障礙物時,Rsign(m,n)=1,否則取0.
由圖2可知,危險度地圖包含了比柵格地圖更豐富的環境信息,除了能表示障礙物的有無外,還能表示任意位置的危險程度,為機器人路徑規劃提供了更有效的環境表示.

圖2 危險度地圖Fig.2 Danger dergree map
2 改進的PSO靜態路徑規劃
粒子群優化算法(particle swarm optimization,PSO)是一種進化計算技術,具有個體數目少、計算簡單、魯棒性好等優點.PSO初始化為一群隨機粒子,然后通過迭代尋找最優解[11].粒子根據下面的公式來完成自己的速度和位置的進化:
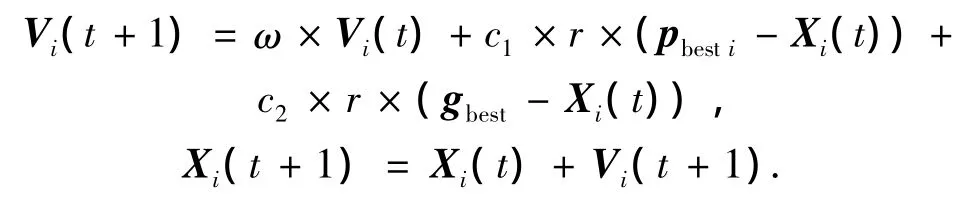
式中:Vi(t)是粒子i在第t代的速度,Xi(t)是粒子i在第t代的位置,粒子的速度V和位置X均為m維向量,pbesti為粒子本身個體極值,gbest為全局極值,r是介于(0,1)之間的隨機數,c1和c2是學習因子,ω為慣性因子.
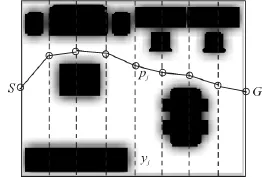
圖3 路徑規劃建模Fig.3 Model of path planning
定義n個m維粒子,粒子每一維位置分量xij(1≤i≤n,1≤j≤m)分別對應圖3中垂直于SG的直線yj,則一個粒子就對應一條路徑P.
在圖3中,定義起始點 S為 p0,目標點 G為pm+1,則路徑P的長度和危險度可分別用式(2)、(3)表示:
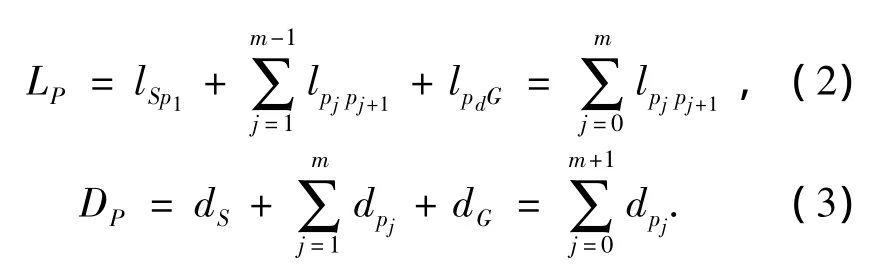
式中:lpjpj+1為點pj與點pj+1間的距離;dpj為路徑點pj的危險度;dS為起始點S的危險度;dG為目標點G的危險度;Dp越大,表示該路徑的危險度越高.
取路徑長度和路徑危險度的加權和作為粒子的適應度函數,則第i個粒子的適應度函數Fi表示為

式中:wl和wd是LPi和DPi的加權因子,為大于等于零的實數,lij,i(j+1)表示粒子i第j維和第j+1維間的長度,dij表示粒子i第j維的危險度.該適應度函數可充分反映路徑的長度和危險程度,使粒子在迭代過程中能自動避開危險度高的區域,選擇一條既安全又長度較短的路徑.
3 動態路徑規劃
智能空間為機器人動態路徑規劃提供了豐富的信息.由于機器人本身攜帶超聲等距離傳感器,因此能夠檢測出進入其探測區域的障礙物,如圖4中的沙發和另一機器人(或人).結合已知的先驗地圖(即全局地圖),可知沙發為固定障礙物,不做任何處理,而另一障礙物在先驗地圖中并不存在,故為動態障礙物.另外,文中假定障礙物為圓形.由于智能空間中的動態障礙物一般為人或其他機器人,所以該假設不失一般性.單獨依靠超聲只能檢測機器人與障礙物的距離,無法得到障礙物的大小等信息;利用智能空間中的頂棚攝像頭可識別出動態障礙物,再作一個包含動態障礙物的最小外切圓作為動態障礙物在二維地圖中的覆蓋范圍,并把相關數據通過智能空間網絡系統傳遞給機器人,這樣機器人就可獲得比較完備的動態障礙物信息.
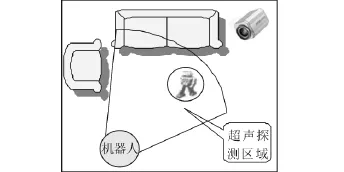
圖4 智能空間中的動態障礙物檢測Fig.4 Dynamic obstacle detection in intelligent space
智能空間中的動態路徑規劃包含3個基本行為,即跟蹤靜態路徑的行為、避障的行為和目標制導的行為[12].其中,避障的行為采用基于動態危險度地圖的加權A*算法實現,該方法實現簡單、實時性強.
3.1 跟蹤靜態路徑的行為
若在智能空間中未發現動態障礙物,由改進的粒子群算法規劃出的靜態路徑就是一條最優路徑,機器人只需跟蹤這條靜態路徑即可.目前路徑跟蹤的方法主要是根據靜態路徑劃分出一些局部目標點,使機器人能夠沿著已經規劃好的路徑前進.因此,根據上一節改進的粒子群優化算法得到機器人靜態路徑,將各路徑點也就是各粒子的最優位置作為路徑跟蹤的局部目標點.該方法簡單易行,能迅速得到局部目標點,很好地滿足了自主機器人導航的實時性要求.
3.2 避障行為
設定安全距離ρs,當機器人檢測到有動態障礙物進入其探測區域時,計算機器人與動態障礙物之間的距離ρ.當ρ<ρs時表示障礙物已進入機器人周圍的危險區域,轉入避障行為,否則繼續跟蹤靜態路徑.
如前所述,智能空間可獲得動態障礙物的位置、大小等信息,將這些信息添加到已有的靜態地圖中去,就可生成動態地圖,再按照第1節所述的方法,建立包含動態障礙物的危險度地圖,即動態危險度地圖,如圖5所示.由于動態障礙物的位置可能會隨時發生變化,因此智能空間和機器人必須實時監控動態障礙物的狀態,定時刷新動態危險度地圖,以保持對動態障礙物的跟蹤.
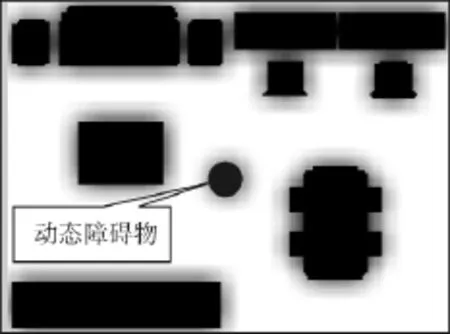
圖5 動態危險度地圖Fig.5 Dynamic danger degree map
在動態危險度地圖的基礎上,采用改進的加權A*算法進行避障.取評價函數為

即用實際耗散g(n)與啟發函數h(n)的加權和作為評價函數.式中:權值wg和wh在搜索過程中可動態調整,n(n=1,2,…,8)是機器人周圍8個柵格節點中的某一個,g(n)是從當前節點(即機器人的當前位置)到節點n的實際代價,h(n)是從節點n到路徑終點的估計代價,h(n)體現了搜索的啟發信息[13].
為了在避障的同時能自主選擇危險度低的路徑,在g(n)中加入了表示路徑節點危險度的信息,即取機器人當前節點到節點n的路徑長度ln和路徑危險度dn的加權和作為 g(n),即g(n)=wlln+wdwn.圖6為機器人周圍的局部動態危險度地圖,機器人左上方節點的危險度為255,即該處有障礙物,由于此處的危險度遠遠高出其他位置,故此節點不會被選中.無障礙物區域的危險度為0~1(已進行歸一化).
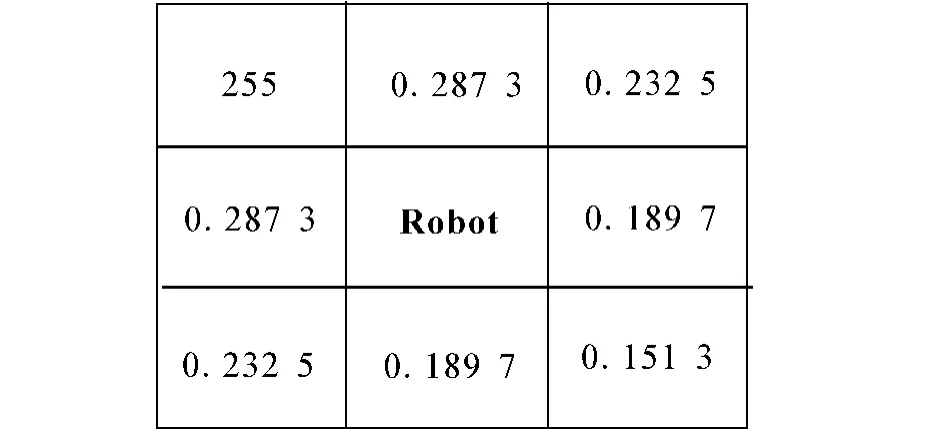
圖6 局部動態危險度地圖Fig.6 Local dynamic danger degree map
取h(n)為n節點到路徑終點G的歐氏距離,即

式中:(xn,yn)是柵格 n的中心點坐標,(xG,yG)是路徑終點G的坐標.
這樣,總的評價函數為
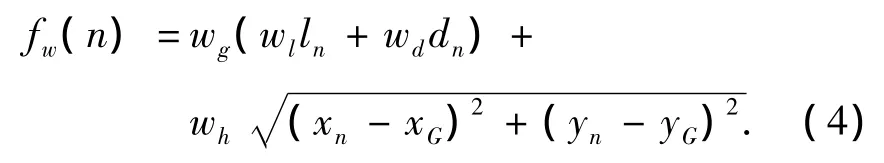
由式(4)可知,當一個節點的危險度越小,與機器人當前位置越近,與終點距離越短,那么整個的啟發函數就越小,此節點就更容易選中.這樣就可以保證在進行下一個節點選取的時候,選擇一個相對于其他節點既安全又路徑較短的柵格節點.
3.3 目標制導行為
機器人避障時,通常會偏離原始靜態路徑,目標制導行為是為了使機器人能夠以最小的代價到達目的地.一般來說,當機器人偏離靜態路徑不遠時,可以引導機器人尋回原來靜態路徑,從而繼續跟蹤靜態路徑;當機器人已經遠遠偏離靜態路徑時,繼續跟蹤靜態路徑可能比重新規劃的路徑所需代價更高,這時機器人應當重新規劃路徑,以便迅速到達目的地.
綜合考慮了機器人可能遇到的各種情況,制定的目標制導策略如下:
1)計算剩余路徑的長度lleave,若lleave小于設定的閾值l0,則重新規劃后續路徑,否則轉2);
2)判斷當前路徑點與靜態路徑點的偏離程度ldeparture,若ldeparture小于閾值l1,則繼續跟蹤靜態路徑,否則轉3);
3)判斷當前路徑點與靜態路徑點間是否有障礙物,若有則重新規劃后續路徑,否則轉4);
4)判斷原靜態路徑是否逐漸趨近于當前路徑點(即偏離程度會越來越小),若是,則繼續跟蹤靜態路徑,否則重新規劃后續路徑.
尋回靜態路徑和重新規劃后續路徑仍采用改進的PSO算法,因為需要規劃的路徑相對較短,故粒子數和粒子維數都很少,所需時間也大大縮短.
4 實驗仿真結果
硬件環境為 Intel(R)Core(TM)2 E4700@2.60 GHz、RAM 4.0 GB,軟件環境為 Microsoft Windows Vista Home Premium、Matlab 7.4.0(R2007a).參數設置為:n=30,m=19,wl=1.0,wd=0.3.
4.1 靜態路徑規劃仿真
圖7為靜態路徑規劃仿真結果.其中圖7(a)為常規PSO算法的路徑規劃結果,圖7(b)為本文方法得到的路徑,經過多次實驗得到其性能對比如表1所示.

圖7 靜態路徑規劃仿真Fig.7 Static path planning diagram
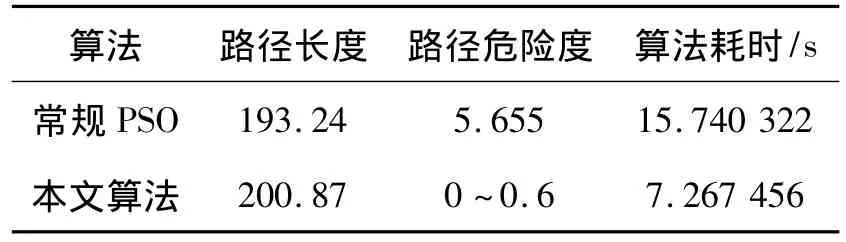
表1 常規PSO算法與本文算法性能對比Table 1 Performance comparison of conventional PSO and modified algorithm
由表1可知,利用改進的粒子群優化算法得到的路徑雖然比常規PSO算法略長,但是路徑的危險度卻大大降低,且本文算法耗時不到常規算法的1/2,極大提高了算法的收斂速度.由圖7(c)和(d)可知該算法對一般智能空間環境和陷阱環境亦能得到最優路徑.
4.2 動態路徑規劃仿真
圖8為動態路徑規劃的仿真結果,其中動態障礙物處于t=10時的位置,即若不進行避障,服務機器人沿靜態路徑行進時將與動態障礙物發生碰撞.

圖8 動態路徑規劃仿真Fig.8 Dynamic path planning diagram
圖8(a)為機器人避障結束后選擇尋回原始靜態路徑策略時獲得的動態路徑.機器人開始時跟蹤靜態路徑前進;t=5時機器人探測到有動態障礙物進入其危險區域,啟動避障行為;t=11時動態障礙物離開機器人的危險區域,避障結束,開始尋找原始路徑;t=15時找到原始靜態路徑,此后一直跟蹤原始靜態路徑直到目標點.表2為該奔向目標策略下的性能.
圖8(b)為機器人避障結束后選擇重新規劃后續路徑策略獲得的動態路徑.機器人開始時跟蹤靜態路徑;t=5時機器人轉入避障行為;t=11時避障結束,此時機器人根據目標制導策略,選擇重新規劃后續路徑并沿新規劃的路徑到達目標點.表3為該策略下的性能.

表2 尋回靜態路徑策略Table 2 Strategy of looking for the static path after avoiding

表3 重新規劃后續路徑策略Table 3 Strategy of planning the remaining path after avoiding
由表2和表3可知,不同的奔向目標策略都可以得到最優路徑,且避障迅速,在避障結束后能快速靈活地進行后續路徑規劃;另外,與靜態路徑相比,動態路徑的長度有所增加,但是路徑的危險度反而有所降低,這主要是由于本文的動態避障算法更注重安全性.
5 結束語
安全性是路徑規劃中最為重要的一個問題.針對智能空間環境的特點,提出一種層次化路徑規劃方法,克服了常規路徑規劃算法對安全性重視不夠的缺點.本文設計的智能空間中的路徑規劃有以下4個特點:
1)能充分利用智能空間中的豐富信息,及時快速地獲取動態障礙物的完備資料;
2)實時性好,能迅速避開動態障礙物;
3)避障結束后機器人能根據當前狀況靈活快速地選擇不同的目標制導策略;
4)動態路徑規劃安全可靠且路徑長度較短.
因此,本文設計的智能空間中的動態路徑規劃方案是完全可行的.當然,本文的工作也有一些不足之處,如尚未考慮智能空間中有多個障礙物的情況和機器人的實際運行速度等問題,這些問題將在今后的研究中進一步解決.
[1]BROOKS R A.The intelligent room project[C]//Proceedings of the Second International Conference on Cognitive Technology.Fukushima,Japan,1997:271-278.
[2]JOHANSON B,WINOGRAD T,FOX A.Interactive workspaces[J].Computer,2003,36(4):99-101.
[3]NIITSUMA M,HASHIMOTO H.Spatial memory as an aid system for human activity in intelligent space[J].IEEE Transactions on Industrial Electronics,2007,54(2):1122-1131.
[4]SHI Yuanchun,XIE Weikai,XU Guangyou.The smart classroom:merging technologies for seamless tele-education[J].Pervasive Computing,2003,2(2):47-55.
[5]田國會,李曉磊,趙守鵬,等.家庭服務機器人智能空間技術研究與進展[J].山東大學學報:工學版,2007,37(5):53-59.TIAN Guohui,LI Xiaolei,ZHAO Shoupeng,et al.Research and development of intelligent space technology for a home service robot[J].Journal of Shandong University:Engineering Science,2007,37(5):53-59.
[6]席裕庚,張純剛.一類動態不確定環境下機器人的滾動路徑規劃[J].自動化學報,2002,28(2):161-174.XI Yugeng,ZHANG Chungang.Rolling path planning of mobile robot in a kind of dynamic uncertain environment[J].Acta Automatica Sinica,2002,28(2):161-174.
[7]TOMPKINS P,STENTZ A,WETTERGREEN D.Missionlevel path planning and re-planning for rover exploration[J].Robotics and Autonomous Systems,2006,54(2):174-183.
[8]MORA M C,TORNERO J.Path planning and trajectory generation using multi-rate predictive artificial potential fields[C]//Proceedings of the IEEE/RSJ International Conference on IntelligentRobotsand Systems. Nice,France,2008:2990-2995.
[9]LI Jigong,FENG Yiwei,GUO Ge.Real-time path planning based on certainty grids map in complex environments[C]//Proceedings of the IEEE International Conference on Integration Technology.Shenzhen,China,2007:525-529.
[10]XUE Yinghua,TIAN Guohui,HUANG Bin.Optimal robot path planning based on danger degree map[C]//Proceedings of the IEEE International Conference on Automation and Logistics.Shenyang,China,2009:1040-1045.
[11]EBERHART R C,SHI Y.Particle swarm optimization:developments,applications and resources[C]//Proceedings Congress on Evolutionary Computation.Piscataway,USA,2001:81-86.
[12]樸松昊,洪炳熔.一種動態環境下移動機器人的路徑規劃方法[J].機器人,2003,25(1):18-21,43.PIAO Songhao,HONG Bingrong.A path planning approach to mobile robot under dynamic environment[J].Robot,2003,25(1):18-21,43.
[13]RUSSELL S,NORVIG P.Artificial intelligence:a modern approach[M].2nd ed.Beijing:Pearson Education Asia Limited and Posts& Telecom Press,2004:76-105.
猜你喜歡
文苑(2018年23期)2018-12-14 01:06:06
文苑(2018年19期)2018-11-09 01:30:14
文苑(2018年17期)2018-11-09 01:29:26
文苑(2018年21期)2018-11-09 01:22:32
領導決策信息(2018年50期)2018-02-22 06:17:16
商周刊(2017年5期)2017-08-22 03:35:26
中國衛生(2016年2期)2016-11-12 13:22:16
中國工程咨詢(2016年4期)2016-02-14 07:28:28
