3D 非均勻直線網格GPU 體繪制方法研究
2010-01-01 01:46:28袁斌
圖學學報 2010年3期
關鍵詞:方法
袁 斌
(北京應用物理與計算數學研究所,北京 100088)
在醫學、計算物理等領域涉及大規模的體數據集,需要合適的可視化技術。體繪制技術是重要的可視化技術之一。體繪制的研究多集中于無結構數據場和均勻數據場的研究,比如,對于均勻數據場有光線投射方法[1],shear-warp 方法[2],紋理體繪制方法[3?5]和GPU 光線投射方法[6?9]。Steven P 采用k-buffer 較好地實現了無結構數據場體繪制[10]。
可編程圖形處理器GPU 是特殊的SIMD 硬件,提供了片元編程技術,它提供了許多SIMD指令[11]。SIMD 是單指令多數據的并行機制。SIMD 技術適合于3D 數據場的繪制,3D 點的位置可以用坐標向量(x, y, z)表示,也可以用齊次坐標向量(x, y, z, w)表示,而顏色用向量(r, g, b, a)表示。圖形數據很適合于用向量表示,在圖形繪制中采用SIMD 技術是很自然的事情。借助于紋理映射,在片元處理階段,可以進行光線積分。GPU 光線投射方法可以看作光柵化方法和光線投射方法結合的方法,在GPU 中, 首先要繪制三角面片,才能執行相應的片元處理。基于GPU片元編程的算法是一種SIMD 算法。
在目前的3D 科學計算中經常使用非均勻直線網格(Non-uniform Rectilinear Grid),它根據物理量的變化自適應地調整網格間隔。非均勻直線網格與均勻網格的區別在于,它的每個方向的網格間隔是變化的。在CPU 光線積分中,需要判別采樣點所在的位置,對于均勻網格很容易通過簡單的取整計算即可以實現,對于非均勻網格不能采用這種方法。在GPU 體繪制中,紋理圖像相當于均勻網格,它不能直接表示非均勻網格。因而,無法使用目前業已存在的針對均勻網格的基于切片的紋理體繪制方法和GPU 光線投射方法。一般處理辦法是將非均勻直線網格轉換成均勻網格, 然后利用這兩種方法進行體繪制。但是,這樣會導致數據量大大增加,并且需要重采樣,必然會花費相當的計算時間和帶來一定的誤差。這里以Lared-S 密度數據(非均勻直線網格)為例,來說明這一點。它的節點數為220×80×80,如果把它轉換成均勻網格,為了減小失真,在每個方向上,均勻網格的網格間距必須不大于原網格最小間距的一半,這樣網格節點至少為15250×159×159,是原來網格的273.8 倍。這里均勻網格梯度計算的時間必然遠大于原網格梯度計算的時間,而且重采樣需要花費大量的計算時間。因而,研究針對非均勻直線網格的GPU 體繪制方法是很有意義的。
本文首先給出針對非均勻直線網格的CPU光線投射方法,一方面它為后面的內容作鋪墊,另一方面可以用來比較。接著給出針對非均勻直線網格的基于輔助紋理的GPU 光線投射和基于切片的3D 紋理體繪制方法。最后,對這些方法進行了比較分析。
1 針對非均勻直線網格的CPU 光線投射方法
本文先給出針對非均勻直線網格的CPU 光線投射方法。
光線投射方法的基本思想是,對每個像素發出一條光線,沿光線進行光亮度積分。在光線積分過程中,沿光線進行均勻采樣。當光線跨出數據包圍盒,或不透明度接近1,停止追蹤。對于非均勻直線網格,在光線積分過程中,借助均勻的輔助網格,快速確定采樣點所在的單元。
輔助網格的設計應該使它具有最少的存儲量和最簡單的計算形式。按照這種想法,本文中使用的輔助網格,是隱式網格,它的每個網格單元或節點并不占用內存。輔助網格的網格面與原網格的網格面平行,輔助網格的每個方向的網格間隔應該小于非均勻網格的相應方向的最小網格間隔,這樣在每個方向上,輔助網格單元至多與原網格的1 個網格面相交。設輔助網格的尺寸為nx×ny×nz。非均勻直線網格的坐標數組(或稱為坐標向量)為X, Y, Z 在實際計算中,需要把它們變換到輔助網格的體素空間。這里需要3 個索引數組xindex,yindex,zindex(它們的數組元素的個數分別為nx, ny, nz),分別定義為
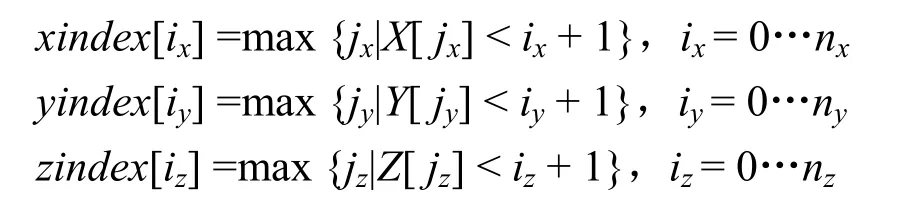
例如,如圖1 所示,非均勻直線網格的邊界與輔助網格的邊界重合,實線為非均勻網格的網格線,虛線為輔助網格的網格線,xindex[0] =0,xindex[1]=1,xindex[2]= index[3]=2。按照這個定義,每個索引只保存一個整數值。在實際計算中,xindex 用O(n)的算法實現:
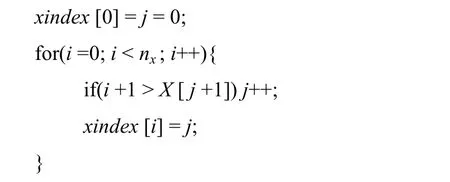
yindex,zindex 采用類似的方法計算。
實現輔助網格占用的空間為O(nx+ ny+ nz),而不是O(nx×ny×nz)。
在光線積分過程中,先通過取整,計算采樣點所在的輔助網格單元,再利用索引快速發現采樣點所在的直線網格單元,光線的當前采樣點的位置為(xs, ys, zs)。通過如下方法得到的(icx, icy, icz),即是采樣點所在單元的結構坐標。

然后,進行插值計算,通過查表計算不透明度,如果不透明度不為0,通過查表計算光照效果,累積顏色和不透明度。在這個算法中,單元(xindex[ix], yindex[iy], zindex[iz])稱為推薦單元;當前采樣點所在的單元,稱為當前單元。推薦單元未必是當前單元,通過修正得到當前單元。
非均勻直線網格中,節點(i, j, k)的梯度采用如下的加權差分公式計算,梯度作為法向量用于光照計算,采用Phone 的光照模型,這樣光照效果反映了數據的局部變化。
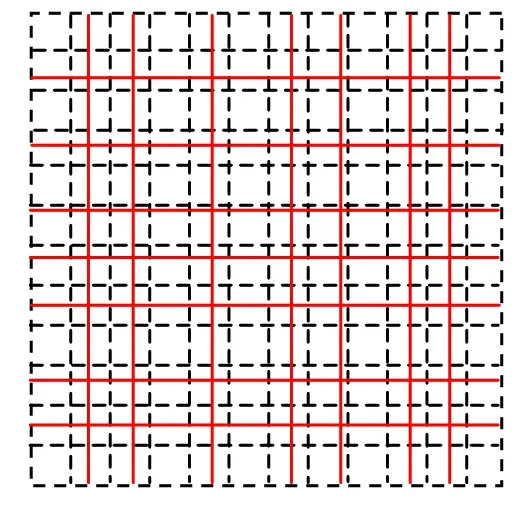
圖1 輔助網格
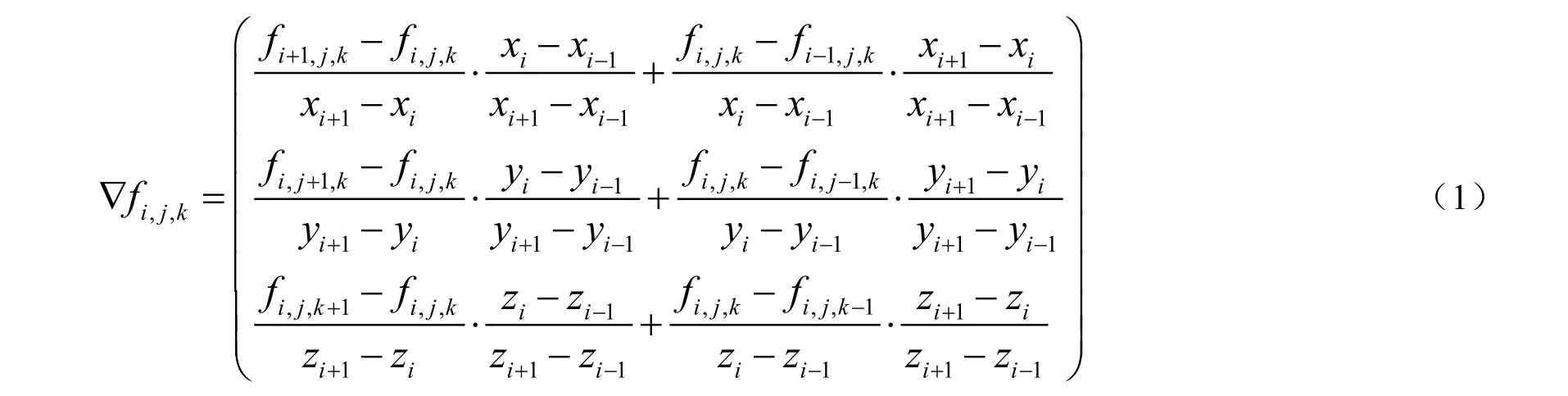
在體繪制中有些數據的不透明度值為0,對體繪制積分沒有任何貢獻,視為無效數據。包含所有有效單元的最小長方體,稱為有效區域。在繪制時只對有效區域進行繪制。這樣不訪問無用的單元,大大提高性能。本文只對有效區域內的光線段進行體繪制積分,這樣可以忽略大片的空白區域,加快繪制速度。
在體繪制時按照Nyquist 采樣定理,光線上采樣點的間隔取為最小網格間隔的一半。如果要得到更精確的圖像可以用更小的采樣間隔。
2 針對非均勻直線網格的GPU 體繪制方法
2.1 GPU 光線投射方法
GPU 的光線投射的基本步驟是:
(1) 把數據場裝入GPU 內存;
(2) 裝入片元程序;
(3) 設置片元程序的輸入參數;
(4) 啟用片元程序;
(5) 繪制有效數據體包圍盒的前表面。
在對一個數據場進行交互繪制時,只在第一次繪制時需要數據裝入操作。為了加快繪制,只繪制有效區域,因而只需裝入有效區域的數據。通過繪制有效數據體包圍盒的前表面,對它所覆蓋的每個片元(fragment),調用片元程序,進行光線積分。在光線積分過程中,需要計算每個采樣點的標量值和梯度值,然后通過查傳輸函數獲得采樣點的材質(Material,包括顏色和不透明度),采用Phone 的光照模型計算顏色,并進行累積。對于均勻網格,在把標量數據和梯度數據裝入紋理內存后,可以直接通過紋理映射快速計算每個采樣點的標量值和梯度值。然而,對于非均勻直線網格需要借助于輔助紋理來完成這一過程。
對于模型空間V(或稱為物理空間)內的非均直線網格R,可以通過“擠壓變換”T 強制其間隔均等,使R 變成一個均勻網格S,它作為三維紋理圖像裝入GPU 內存,該紋理空間記為Q,紋理裝入實現了一個線性變換M,把S 映射為Q中的均勻網格,不妨表示為MTR,MTR 的每個節點為紋元(texel)的中心。T 是一個非線性變換,但它是分段線性變換, 當它約束到每個單元空間,即為線性變換。R 的輔助網格A 是模型空間V 中的均勻網格,在實際計算時,需要用線性變換L,把A 變換成輔助紋理空間B 中的均勻網格,記為LA。用L 把R 變換到B,仍然得到一個非均勻直線網格,不妨用LR 表示。A 的體素(voxel)空間為C,變換H 把A 變換為C 中的間隔為1的均勻網格;H 把R 變換到C,仍然得到一個非均勻直線網格,不妨用HR 表示。MTL-1是非線性變換,它可以把輔助紋理空間B 中采樣點的坐標轉換為Q 中的坐標,進而通過紋理映射得到標量和梯度。
對每個方向只要一維的輔助紋理,它保存原網格的索引,稱為索引紋理,這里索引紋理的尺寸應該為2 的冪。每個索引紋理保存MTR 的垂直于相應坐標軸的網格面的截距。在此,xindex的定義修正為

這里,X 是HR 的坐標向量。
yindex, zindex 的定義和計算方法也要作相應修正。
由于GPU 中紋理的最大尺寸為4096。而輔助網格的尺寸會超過這個值,因此,把索引信息均分成幾段,每一段作為2D 紋理的一行,這樣把一維紋理折疊成2 維紋理。3 個方向的索引紋理的高度分別用xh, yh, zh 表示,輔助紋理空間B為[0, xh]×[0, yh]×[0, zh],繪制有效區域時,其包圍盒頂點的紋理坐標設置為LA 包圍盒的頂點坐標。另外,對每個方向,還要有一維紋理保存紋理空間B 中非均勻直線網格LR 的坐標向量,稱為坐標紋理。為了保證精度,索引紋理和坐標紋理,均采用32 位浮點紋理,它們的放大和縮小濾波方式均設置為GL_NEAREST。
作者按照公式(1)計算梯度量和梯度,保存到3D 紋理圖像中;把標量和梯度數據裝入GPU 內存。此外,還要把索引紋理和坐標紋理裝入到GPU 內存。在片元程序中,在輔助紋理空間B中進行積分。在光線積分中,對每個采樣點p,計算MTL-1p,得到Q 中的紋理坐標,通過紋理映射得到標量值和梯度,由傳輸函數(用紋理表示)得到采樣點的材質,通過光照計算得到采樣點的顏色,累積顏色和不透明度。
在直線網格中,單元(i, j, k)有8 個頂點,均為網格節點;其中,節點(i, j, k)稱為它的第一頂點,節點(i+1, j+1, k+1)稱為它的第8 頂點。計算變換MTL-1的算法思想是,根據光線采樣點的坐標查索引紋理,查得推薦單元第一頂點在紋理空間Q 中的坐標,保存到t1,通過LR 的坐標向量紋理,由t1 查得第一頂點在B 中的坐標,把它與當前采樣點的坐標比較,修正t1 得到當前單元的第一頂點在Q 中的紋理坐標,計算當前單元的第8 頂點在Q 中的紋理坐標tb;通過LR 的坐標向量紋理,由t1 查得當前單元第一頂點在B 中的坐標a,第8 頂點在B 中的紋理坐標b,計算當前采樣點在當前單元中的插值參數;進而計算當前采樣點在Q 中的紋理坐標。下面給出具體算法,這是向量算法。索引紋理映射可以用函數XIndex(v), YIndex(v), ZIndex(v)表示,v 是向量,為2D 紋理坐標。spacing.x, spacing.y, spacing.z分別表示Q 中s, t, r 方向相鄰紋元的間隔。這里用X(s), Y(s), Z(s)表示直線網格LR 的坐標向量紋理映射,s 為1D 紋理坐標。如果操作數為向量,+, – ,*, / 為向量運算。a.x, b.x 等為標量,無“.”的變量為4 維向量。向量函數SLT(u, v)表示向量比較指令SLT[11]。texcoord 為輔助紋理坐標。向量函數fraction(v)取v 的每個分量的小數部分,向量函數floor(v)取v 的每個分量的整數部分。算法如下:
算法1 計算變換MTL-1的算法
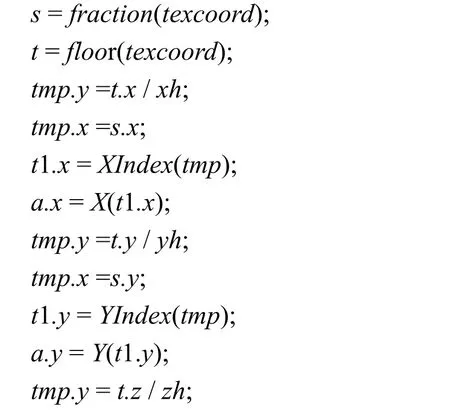

用算法1 計算出t1 后,用t1 通過紋理映射查詢標量值和梯度值。
光線積分在輔助紋理空間B 中進行,需要對采樣步長進行修正。下面說明這一點。


由此可見,在透視變換下,如果在LA 中,采用同樣的步長進行采樣,不同方向的光線在模型空間V 中的相應采樣步長很可能不同。因此,要使得各方向光線的采樣步長變換到模型空間V中保持相同,必須在B 中根據光線方向計算采樣步長。設在輔助紋理空間B 中光線方向為v(單位向量),在模型空間V 中設定采樣步長為d,那么,該光線在輔助紋理空間B 中的采樣步長是
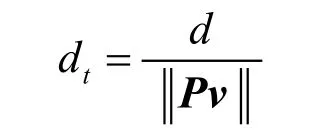
首先實現了針對均勻網格的GPU 光線投射方法,在實現過程中,參考了S Stegmaier 等人的片元程序[6]和vtk[12]的3D 紋理體繪制中的片元程序。整個光線投射算法是用ARB fp1 匯編語 言[11]實現,為了采用分支命令和循環命令,在程序開頭加上OPTION NV_fragment_program2。在實現的用于光線積分的片元程序中采用了光線早終止技術,只要累積不透明度大于0.98, 就終止光線積分,這樣節省計算。如果采樣點的透明度為0,則跳過采樣點,不進行光照計算,這樣也可以節省計算。在此基礎上,把前面的算法1用ARB fp1 匯編語言實現,并插入到光線積分循環中每步的開頭,從而實現了基于輔助網格的針對非均勻直線網格的GPU 光線投射方法。
算法采用標量傳輸函數(它把采樣點的標量轉換成顏色和不透明度)和梯度量傳輸函數(它把梯度量轉換成調制因子)。算法用數組表示傳輸函數,并裝入一維紋理,這樣通過紋理映射實現傳輸函數。通過采用梯度量調制,可以突出梯度變化大的區域,使物質分界面更清晰。
2.2 基于切片的3D 紋理體繪制方法
作者又把2.1 節的算法與基于切片的3D 紋理體繪制算法結合,得到針對非均勻直線網格的3D 紋理體繪制方法。在該算法中不必對采樣步長進行校正。算法中所用的切片平行于視平面。為了提高繪制精度,切片的間隔為最小網格間隔的一半。
3 結果與結論
作者實現了針對非均勻直線網格的CPU 光線投射和GPU 光線投射,以及基于切片的3D 紋理體繪制。為了便于描述,在下文中分別簡稱為GPU 光線投射,CPU 光線投射和3D 紋理體繪制。
在Intel P4 3.0GHz 的機器上測試上述算法,它裝有Nvidia Geforce 6800GT 圖形卡。在測試中GPU 光線投射和CPU 光線投射采用一致的采樣步長(即把兩種方法的采樣點映射到同樣的坐標系下,兩者的采樣步長是相等的),相當于3D 紋理體繪制中相鄰切片的距離。為了保證繪制質量,采樣步長均為最小網格間隔的一半。
如圖2,對于vtk 的非均勻直線網格RectGrid數據進行繪制,數據尺寸47×33×44,圖像尺寸(視區尺寸)512×512,采用初始傳輸函數。CPU光線投射方法繪制時間6.375 秒, 最大積分步數156。如圖2(b),GPU 光線投射,繪制時間0.265秒。如圖2(d)所示,用3D 紋理體繪制方法,繪制到普通幀緩存,圖像質量較差,這是由于普通幀緩存,R、G、B、A 分量各占8 位,因而精度不夠, 當不透明度小于1/256 時,便被忽略,不能正確累積顏色。解決辦法是將圖像繪制到浮點緩存中,再把浮點緩存綁定到紋理,再通過片元程序把紋理繪制到普通幀緩存中。每次繪制切片需要采用圖形流水線中的混合操作,把顏色累計到浮點緩存中。采用Pbuffer 實現浮點緩存。Nvidia Geforce 6800GT 的混合操作運算是16 位的浮點運算[13],把Pbuffer 配置成浮點緩存,并且每個顏色分量配置成16 位浮點數,這樣,其計算精度必然低于光線投射方法。圖2(c)是采用16 位浮點緩存的3D 紋理體繪制結果,繪制時間0.093 秒,切片數155。在這里,圖2(a),圖2(b), 圖2(c)圖像質量相當。圖2(f)的質量低于圖2(e),這說明3D 紋理體繪制,即使采用了16 位浮點緩存,其圖像質量仍低于GPU 光線投射。
在后面的測試結果中,如果沒有特別聲明,基于切片的3D 紋理繪制采用16 位浮點緩存。
圖3 是Lared-S 密度數據(非均勻直線網格)的繪制結果,數據尺寸220×80×80,圖像尺寸512×512,為繪制這個圖像,調整了傳輸函數,對數據進行多次平移和旋轉變換。圖3(a)是CPU光線投射方法的圖像,繪制時間16.578 秒。光線積分步數是708。圖3(b)是GPU 光線投射圖像,繪制時間0.843 秒。圖3(c)是3D 紋理體繪制算法繪制的圖像。繪制這幅圖像,用了1112 個切片,繪制時間0.39 秒。前兩幅圖像質量相當,(把圖像放大后可以看出)3D 紋理體繪制圖像質量稍差一些。
把均勻網格數據Hydrogen 和fish,按照正弦函數調整x 方向的網格間隔,得到非均勻直線網格數據,RectHydrogen,Rectfish。這里用RectHydrogen 和Rectfish 對算法進行測試。
Rectfish 數據尺寸256×256×512,圖像尺寸512×512,圖4(a)采用CPU 光線投射,繪制時間18.797 秒,最大積分步數637;圖4(b)采用GPU光線投射方法,繪制時間1.218 秒;圖4(c)采用3D 紋理體繪制方法,繪制時間0.671 秒,切片數758。圖4(b)比圖4(a)稍有差別,因為梯度的編碼方法有所不同。圖4(b)與圖4(c)質量相當,但后者繪制速度更快一些。
RectHydrogen 數據尺寸128×128×128,圖像尺寸512×512,圖5(a)采用GPU 光線投射方法,繪制時間1.062 秒;圖5(b)和圖5(c)采用3D紋理體繪制方法,切片數741,圖5(b)使用的繪制緩沖區的每個顏色分量為16 位浮點數,繪制時間0.593 秒;圖5(c)使用的繪制緩沖區的每個顏色分量為8 位整數,繪制時間0.593 秒。圖5(b)與圖5(a)質量相當,圖5(c)的質量較差一些。

圖2 RectGrid 數據

圖3 Lared-S 密度數據

圖4 Rectfish 數據

圖5 RectHydrogen 數據
采用GPU 光線投射具有與CPU 方法相似的精度,而繪制速度得到大幅度提高。一般情況下,3D 紋理體繪制比GPU 光線投射快,但GPU 光線投射可以獲得更好的精度。在GPU 光線積分算法中,一旦累積不透明度超過0.98 即終止光線積分,并且只對不透明的采樣點計算光照,這樣整體的計算量小于3D 紋理繪制的計算量,但GPU 光線投射繪制的速度卻小于3D 紋理體繪制的速度,這是因為GPU 擁有多條片元處理流水線,在GPU 光線投射算法中,各個片元處理流水線的負載嚴重不平衡,而在3D 紋理體繪制中各流水線的負載基本平衡。這說明片元處理流水線之間的負載平衡對于GPU 繪制是十分有意義的。
對于較大規模的數據場,繪制大幅面的精確圖像,其速度仍難達到交互。有兩種方法解決這個問題:一是降低數據的分辨率,另一個是降低圖像的分辨率。對于后者,可以先繪制到Pbuffer, 然后把它連接到紋理,通過紋理映射繪制大幅面的圖像。
[1] Marc Levoy. Efficient ray tracing for volume data [J]. ACM Transactions on Graphics, 1990, 9(3): 245-261.
[2] Philippe Lacroute, Marc Levoy. Fast volume rendering using a shear-warp factorization of the viewing transformation [C]//Proceedings of the 21st Annual Conference on Computer Graphics and Interactive Techniques. New York, NY, USA, ACM Press, 1994: 451-458.
[3] Brian Cabral, Nancy Cam, Jim Foran. Accelerated volume rendering and tomographic reconstruction using texture mapping hardware [C]//Proceedings of the 1994 Symposium on Volume Visualization. New York, NY, USA, ACM Press, 1994: 91-98.
[4] Klaus Engel, Martin Kraus, Thomas Ertl. High-quality pre-integrated volume rendering using hardware- accelerated pixel shading [C]//Proceedings of the ACM SIGGRAPH/EUROGRAPHICS Workshop on Graphics Hardware, 2001: 9-16.
[5] 童 欣, 唐澤圣. 基于空間跳躍的三維紋理硬件體繪制算法[J]. 計算機學報, 1998, 21(9): 807-812.
[6] Stegmaier S, Strengert M, Klein T, et al. A simple and flexible volume rendering framework for graphics- hardware-based raycasting[C]//Proceedings of the International Workshop on Volume Graphics ’05. Stony Brook, New York, USA, 2005: 187-195.
[7] Klein T, Strengert M, Stegmaier S, et al. Exploiting frame-to-frame coherence for accelerating high-quality volume raycasting on graphics hardware [C]// Proceedings of IEEE Visualization '05, 2005, IEE, 2005: 223-230.
[8] 儲璟駿, 楊 新, 高 艷. 使用GPU 編程的光線投射體繪制算法[J].計算機輔助設計與圖形學學報, 2007, 19(2): 257-262.
[9] 陳 為, 彭群生, 鮑虎軍. 視點相關的層次采樣:一種硬件加速體光線投射算法[J]. 軟件學報, 2006, 17(3): 587-601.
[10] CALLAHAN S P, IKITS M, COMBA J L D, et al. Hardware-assisted visibility sorting for unstructured volume rendering [J]. IEEE Transactions on Visualization and Computer Graphics, 2005, 11(3): 285-295.
[11] NVIDIA. 2007. NVIDIA OpenGL extension specifications[DB/OL]. http://developer.nvidia.com/ object/nvidia_opengl_specs.html
[12] Martin K, Schroeder W, Lorensen B. The visualization toolKit (VTK) [DB/OL]. http://www.vtk.org/2008.
[13] Kilgariff E, Fernando R. The GeForce 6 series GPU architecture [M]. GPU Gems 2, Addison-Wesley, 2005. 471-491.
猜你喜歡
中老年保健(2021年9期)2021-08-24 03:52:04
河北畫報(2021年2期)2021-05-25 02:07:46
中學生數理化(高中版.高考理化)(2020年2期)2020-04-21 05:33:04
兒童繪本(2020年5期)2020-04-07 17:46:30
兒童故事畫報(2019年5期)2019-05-26 14:26:14
Coco薇(2016年2期)2016-03-22 02:42:52
山東青年(2016年1期)2016-02-28 14:25:23
Coco薇(2015年1期)2015-08-13 02:47:34
小雪花·成長指南(2015年7期)2015-08-11 15:03:12
小雪花·成長指南(2015年4期)2015-05-19 14:47:56
