基于logistic回歸的上市公司財務危機預警模型
2007-12-29 00:00:00朱振梅
會計之友 2007年24期
【摘要】為了建立合理有效的財務危機預警模型,本文選擇了代表公司財務健康狀況的18個指標作為備選預警指標,并運用logistic過程中逐步回歸的方法從中選擇了3個對因變量影響顯著的財務指標。用容許度(TOL)和方差膨脹因子(VIF)兩個指標對3個財務指標進行多重共線性檢驗。在多重共線性不顯著的情況下,對符合條件的財務數據進行logistic回歸,得到了財務危機預警模型。最后通過回代判定,發現這個模型具有較高的預測準確性。
一、財務危機預警研究概述
企業財務危機是一個連續的動態過程,并直接表現為績效指標的惡化,因此可通過一定的財務指標來構造企業的財務預警模型。從現實情況來看,股票投資者、債權人和政府監管機構對企業財務危機預測具有很大的需求,這些需求推動了財務危機預警研究的不斷深化。
國外對于財務預警模型的研究相對比較成熟,早在1966年,Beaver就運用單變量判定分析研究公司財務危機問題;Altman(1968)最早運用多變量線性判別分析(Multiple Discriminate Analysis)探討企業危機預測問題,其發現最具解釋能力的5個財務比率分別為:營運資金/總負債、保留利潤/總資產、息稅前利潤/總資產、權益市價/總負債和銷售收入/總資產。Altman、Haldeman和Narayanan(1977)繼續對Altman(1968)的原始模型修正和補充,提出一個“新Zeta模型”。隨著統計技術和計算機技術的不斷發展,遞歸分類、人工智能及人工神經元網絡等技術也逐漸被引入到財務危機預警模型中。
近年來,隨著公司破產數量的增多,國內學者對公司財務危機預警模型的研究也越來越多:1999年,陳靜發表了《上市公司財務惡化預測的實證分析》,該文將1998年年報后被特別處理(ST)的27家上市公司定義為財務危機公司。陳瑜在2000年發表了《對我國證券市場ST公司預測的實證研究》一文(《經濟科學》,2000年6月),該文以1999年底前曾被特別處理(ST)的58家上市公司為樣本進行了分析。吳世農、盧賢義(《我國上市公司財務困境的預測模型研究》,《經濟研究》)以1998~2000年發生ST的70家上市公司為研究對象,結果表明(1)在財務困境發生前2年或1年有16個財務指標的信息時效性較強,其中凈資產報酬率的判別成功率較高;(2)模型在財務困境發生前能做出較準確的預測,且在財務困境發生前4年的誤判率在28%以內;(3)相對同一信息集而言,Logistic預測模型的誤判率最低,財務困境發生前1年的誤判率僅為6.47%。
二、預警指標和模型
(一)財務危機預警指標的選擇
單純的幾個財務比率很難揭示公司陷入財務危機或被特別處理的原因,通常的做法是挑選不同的變量代表上市公司財務特征的不同方面。因此,本文在借鑒前人經驗的基礎上,初步從反映公司財務健康狀況的每一大類特征中選出某一個或幾個指標,形成一個財務危機預警指標體系,然后運用回歸模型挑選出正確率最高的變量組合。在實際分析中,本文將ST公司近似看作財務危機公司,并選擇ST和非ST公司六大類財務特征指標列為備選預警變量(備選預警指標描述見表1)。
本文的研究對象是2003~2005年發生的A股ST公司及同時期非ST上市公司66家;其中,2003年發生ST的上市公司為48家,2004年發生ST的上市公司為11家,2003年發生ST的上市公司為7家;同時,取66家非ST上市公司作為對比研究,具體見表2。
(二)分析模型簡述
Logistic回歸方法主要是用來預測二值響應變量(例如成功和失敗)或者次序變量(例如,沒有、一般和嚴重)的值,二值響應的因變量(或者稱為反應變量)值可以是上榜、落榜的結果,或者疾病經過治療后治愈、復發的兩種可能。不論其如何定義,Logistic回歸是為了找出這個因變量與一組變量(稱為自變量)之間的線性關系,所用的參數估計方法為極大似然估計法。在二值響應模型中,通常用Y代表一個個體或者一個實驗單元,它的取值有兩種可能,為方便起見,分別記為0和1(例如,如果不發病則Y=0,發病則Y=1),X=(X1,X2,…,Xt),是一組可以說明Y發生概率大小的變量,用以表示Y的某一種特定情況(以1表示)發生的概率,p=Prob(Y=1/X)。假設Xi為第I個陷入危機公司的財務預測變量矩陣,那么其陷入危機概率Pi和Yi之間存在如下回歸關系:

Yi=lnPi/1-Pi
其中,Yi=a+∑biXi
Logistic回歸模型的曲線為S形,且預測最大值趨近1,最小值趨近0,一般選擇0.5作為分割點,即如果通過模型計算出來的危機概率Pi大于0.5,那么該公司可歸入陷入危機的公司;反之,則將該公司視為正常公司。
本文之所以采用logistic模型,主要是因為Logistic回歸對于變量的分布沒有具體要求,適應范圍更廣,而且Logistic模型計算得到的是一個概率值,給人直觀明了的感覺,在實際運用中非常簡單、方便。
三、運用Logistic模型進行實證分析
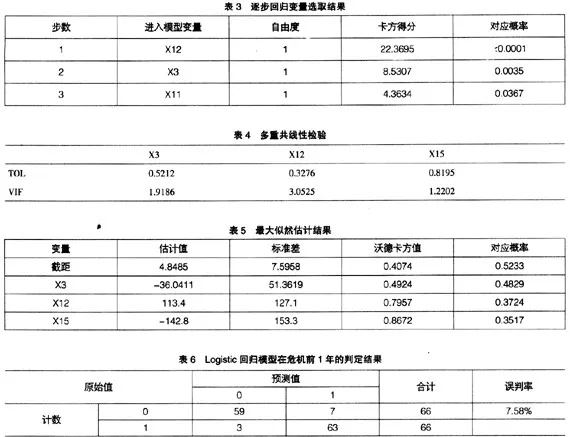
首先,利用SAS軟件中的logistic過程對財務危機前1年的數據進行分析。在過程中,運用逐步回歸法進行變量的選取,規定自變量進入模型和保留在模型中的顯著性水平都是0.3,結果如表3所示。
最后選擇了X3(營運資本/總資產)、X12(資產報酬率)、X15(凈利潤增長率)三個變量。從分析結果可以看出,沃德卡方統計量對應的臨界值在0.01的水平上都是顯著的。
為了避免多重共線性,對選定的3個變量進行多重共線性檢驗。本文使用的檢驗指標是容許度(TOL)和方差膨脹因子(VIF)。計算公式為:
TOLj=1-R2j=1/CIF1
其中,R2j為Xj對其余k-1個自變量回歸中的判定系數。當TOLj較小時,認為存在多重共線性。一般地,方差膨脹因子VIF大于10,認為具有高的多重共線性。VIF檢驗的結果見表4。從表5可知,6個變量的VIF均小于10,可認為各變量之間不存在顯著的多重共線性。
接著,最大似然估計分析給出了參數的最大似然估計值、標準差及沃德檢驗的卡方值及其對應的概率,見表5。
由此,本文得出了logistic回歸的方程:
LnPi/1-Pi=4.8485-36.0411X3+113.4X12-142.8X15
最后,從logistic過程給出的一致性可以看出,本模型預測概率與預測因變量之間的關聯性達到了92.42%,而不一致的概率僅為7.58%。具體分析結果見表6。
注:0代表非ST上市公司,1代表ST公司。
在財務危機前1年,72家非財務危機有4家被錯判,72家財務危機公司有3家被錯判,總體上看,144家公司有7家被錯判,誤判率為4.86%,說明基于logistic模型建立的財務危機預警模型所進行的預測是基本準確的。
